Notice: This material is excerpted from Special Edition Using HTML, 2nd Edition, ISBN: 0-7897-0758-6. This material has not yet been through the final proof reading stage that it will pass through before being published in printed form. Some errors may exist here that will be corrected before the book is published. This material is provided "as is" without any warranty of any kind.
by Jim O'Donnell
![]() HTML
pages are like annotated bibliographies: they give you the opportunity
to expand on an endless variety of topics and present additional factual
or thematic resources to further explore a subject.
HTML
pages are like annotated bibliographies: they give you the opportunity
to expand on an endless variety of topics and present additional factual
or thematic resources to further explore a subject.
Of course, ![]() HTML
pages are also like gossip magazines: sooner or later you'll see just about
everything on them.
HTML
pages are also like gossip magazines: sooner or later you'll see just about
everything on them.
But regardless of how anyone perceives HTML, everyone who uses it speaks the same language. Elements, tags, anchors, hyperlinks, URLs, and attributes: they're all part of the lexicon of the Web's documents. To create inspired Web pages (and to cast a critical eye on those already on the Web), you need to have an intimate familiarity with the building blocks of HTML.
This chapter answers the following questions:
See "Common Conventions in HTML Documents,"(ch. 8)
![]() HTML
is a subset of
HTML
is a subset of ![]() SGML
(Standardized General Markup Language).
SGML
(Standardized General Markup Language). ![]() SGML
documents are more complex and programming-like than
SGML
documents are more complex and programming-like than ![]() HTML.
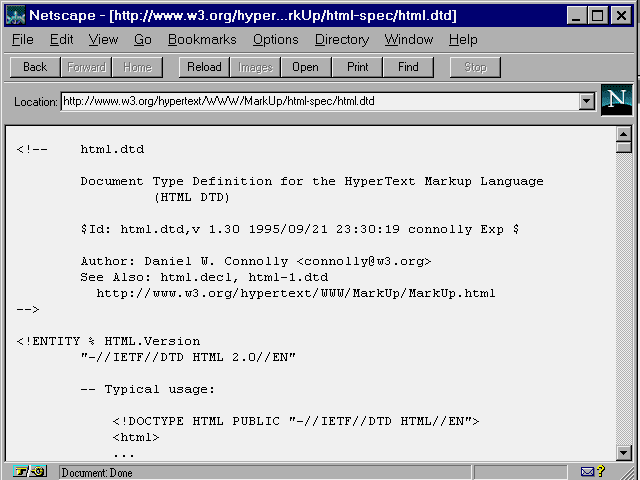
Figure 4.1 shows how an
HTML.
Figure 4.1 shows how an ![]() SGML
document describes the
SGML
document describes the ![]() HTML
standard (the figure is, in fact, the SGML declaration for HTML-the SGML
document that defines HTML).
HTML
standard (the figure is, in fact, the SGML declaration for HTML-the SGML
document that defines HTML).
![]() SGML
coding provides
SGML
coding provides ![]() machine-level
display format and function commands.
machine-level
display format and function commands.
![]() HTML
resembles simplified
HTML
resembles simplified ![]() SGML.
The observation that
SGML.
The observation that ![]() SGML
is to
SGML
is to ![]() HTML
as
HTML
as ![]() HTML
is to plain text seems reasonable on the surface. When you take a look
under the hood, though, it's easy to see how
HTML
is to plain text seems reasonable on the surface. When you take a look
under the hood, though, it's easy to see how ![]() HTML
shares the advantages of both systems of marking text.
HTML
shares the advantages of both systems of marking text.
Troubleshooting
SGML seems very complicated. How do I find out more about it?
SGML is not for the faint of heart, as the code in figure 4.1 suggests. SGML code constructs are not based as much in "plain English" as HTML is. The following text is written in SGML, describing how the HTML element BLOCKQUOTE is used:
<!ELEMENT (%blockquote) - - %body.content> <!ATTLIST (%blockquote) %attrs; %needs; - for control of text flow - >How would that read in English? The
A good way to learn a little more about
ftp://www.ucc.ie/pub/sgml/p2sg.psThis is a PostScript file and can be read by printing it on a
In his World Wide Web Research Notebook
http://www.w3.org/hypertext/WWW/People/Connolly/drafts/web-research.html
Daniel Connolly outlines the advantages and disadvantages to carrying
over ![]() SGML
practices and constructs into the current
SGML
practices and constructs into the current ![]() HTML
standard.
HTML
standard.
These are the benefits of using SGML to define HTML:
These are the disadvantages of using SGML to define HTML:
![]() HTML's
strength comes from its combination of
HTML's
strength comes from its combination of ![]() SGML
machine-level constructs (the tags and elements that tell a viewer the
purpose of document text) and standard
SGML
machine-level constructs (the tags and elements that tell a viewer the
purpose of document text) and standard ![]() English
text markup notation.
English
text markup notation.
For example, the <B> container tag is mnemonically correct (it stands for bold), and it signals a format change to the document's viewing software, which changes the display format of the following text. When the viewer comes across the </B> closing tag, which tells it to turn off the bold attribute, it returns to the previous text formatting.
The versatility of ![]() SGML
and
SGML
and ![]() HTML
is becoming widely acknowledged as they are adopted as hypertext document
standards by more content managers, including the federal and many state
governments.
HTML
is becoming widely acknowledged as they are adopted as hypertext document
standards by more content managers, including the federal and many state
governments.
Creating the Standards
The HTML standard is constantly under development. Users and developers from around the world contribute to the on-going discourse and testing of new ideas, concepts, and uses for
The goal of any
You can get more information about the ongoing HTML standards process from Daniel Connolly's Web page:
or by reading Chapter 8, "Common Conventions in HTML Documents."
It's debatable who has contributed more to the "acronymization" of our culture. In a world where ATM can have two totally different meanings (one's great for convenience banking and the other for high-speed data networking), you might expect a language like HTML (itself an acronym) to continue the tradition.
And it does. From its elements-UL stands for, appropriately enough,
un-ordered list-to its parent language SGML, ![]() HTML
is defined by acronyms. An acronym defines
HTML
is defined by acronyms. An acronym defines ![]() HTML
as well-HTML's DTD.
HTML
as well-HTML's DTD.
DTD stands for Document Type Definition. It's a document that describes
the HTML language, its elements, and their legal uses. The ![]() HTML
DTD has many levels that pertain to different categories of use or compatibility
with the
HTML
DTD has many levels that pertain to different categories of use or compatibility
with the ![]() HTML
standard. These levels are:
HTML
standard. These levels are:
The ![]() HTML
DTD is written in
HTML
DTD is written in ![]() SGML
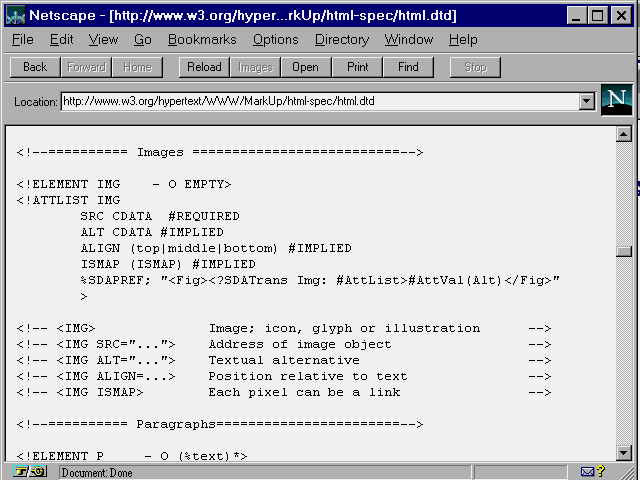
and can be difficult to interpret. Figure 4.2
shows a portion of the
SGML
and can be difficult to interpret. Figure 4.2
shows a portion of the ![]() HTML
DTD for
HTML
DTD for ![]() Level
0 (for the complete DTD, see Appendix A, "HTML Tags").
The document coding is complex and difficult to read; it's not meant entirely
to be read by people, but by SGML interpreters. Don't be surprised if it
makes no sense to you-it doesn't to the vast majority of people.
Level
0 (for the complete DTD, see Appendix A, "HTML Tags").
The document coding is complex and difficult to read; it's not meant entirely
to be read by people, but by SGML interpreters. Don't be surprised if it
makes no sense to you-it doesn't to the vast majority of people.
The document for each level defines a measure of compatibility to
the ![]() HTML
specification.
HTML
specification.
Annotated versions of the HTML DTD make it easier for developers and end users to verify conformity issues. Daniel Connolly maintains one popular version, and you can find it at:
http://www.w3.org/hypertext/WWW/People/Connolly/
The Web sites listed in Appendix D, "WWW Bibliography," collect other descriptions of the various HTML standards.
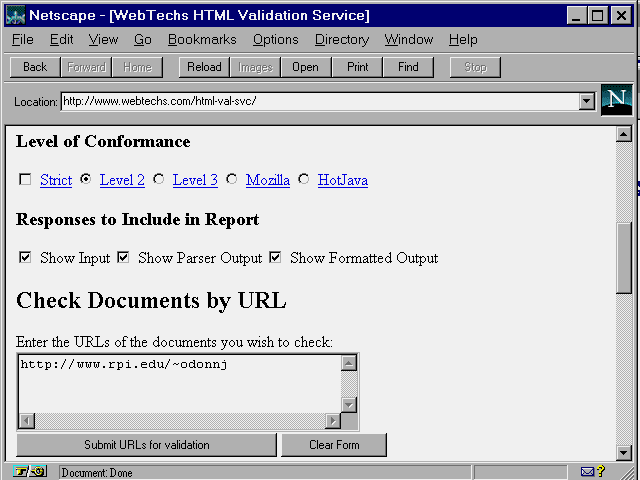
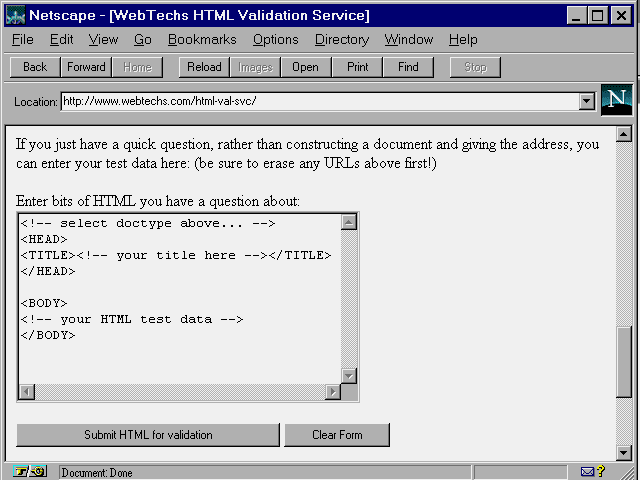
It is possible to check your HTML documents for conformance with HTML standards. The Webtechs HTML Validation Service can be found at:
http://www.webtechs.com/html-val-svc/
As shown in figure 4.3 and 4.4,
you can check for conformance at different levels, and supply the ![]() HTML
document either as a URL to an existing document (see
figure 4.3) or by directly inputting the
HTML
document either as a URL to an existing document (see
figure 4.3) or by directly inputting the ![]() HTML
(see figure 4.4).
HTML
(see figure 4.4).
The Webtechs HTML Validation Service allows you to check your HTML documents for conformance to a variety of levels.
If you want to check out a small amount of HTML, you can enter it directly, rather than building a separate web page.
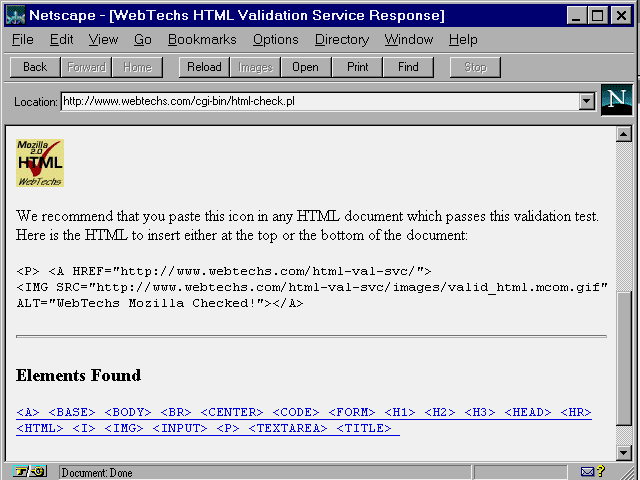
After you submit your URL or HTML code, the Webtechs service will analyze it and return a report such as that shown in figure 4.5. If it conforms to the HTML 2.0 standard, you are invited to include the validation icon on your web pages.
Successfully passing the ![]() HTML
Validation check can be indicated on your
HTML
Validation check can be indicated on your ![]() web
pages by including a link to the validation icon.
web
pages by including a link to the validation icon.
![]() HTML
is composed of elements, or instructions, to WWW viewers to perform a defined
task (make text bold, insert a paragraph break, or format and number a
list in a predetermined manner).
HTML
is composed of elements, or instructions, to WWW viewers to perform a defined
task (make text bold, insert a paragraph break, or format and number a
list in a predetermined manner). ![]() HTML
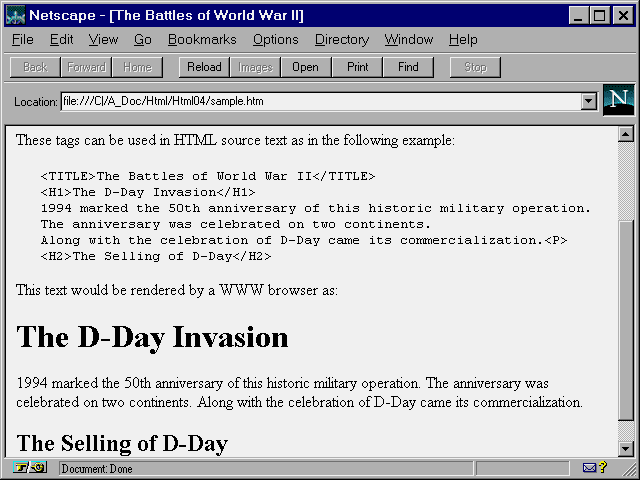
tags consist of individual elements inside angle brackets. Figure
4.6 shows a few typical elements and how they are written in tag format.
HTML
tags consist of individual elements inside angle brackets. Figure
4.6 shows a few typical elements and how they are written in tag format.
![]() HTML
tags are "invisible" when the WWW viewer displays the document.
HTML
tags are "invisible" when the WWW viewer displays the document.
Ttoubleshooting
If WWW viewers read
Displaying the
<TITLE>The Battles of World War Two</TITLE>you must use entities for the angle bracket characters.
<TITLE>The Battles of World War Two</TITLE>
As the name implies, ![]() HTML
marks up text in a document by defining the specific formatting for sections
of the document. HTML is a hybrid, using some elements to define the abstract
value of text (such as "emphasized") and others to define the
actual on-screen representation in the WWW viewer's window (such as "italicized").
This "split personality" created quite a controversy in the authoring
community, spawning two camps of thought that support the different uses
of HTML markup.
HTML
marks up text in a document by defining the specific formatting for sections
of the document. HTML is a hybrid, using some elements to define the abstract
value of text (such as "emphasized") and others to define the
actual on-screen representation in the WWW viewer's window (such as "italicized").
This "split personality" created quite a controversy in the authoring
community, spawning two camps of thought that support the different uses
of HTML markup.
Unlike the file systems of some operating systems, HTML element names are case independent. You can write tags with any mixture of upper and lowercase characters. For example, you can write one tag that defines the formatting of a section of text as <BLOCKQUOTE>, <blockquote>, <BlockQuote>, or any capitalization combination. Some authors use unorthodox capitalization schemes, such as <bLocKquOtE>, but that doesn't make for easy-to-read HTML, and your site administrator probably discourages this brand of "net.hipness."
This book's convention of using all uppercase characters in
![]() HTML
uses two types of elements: empty (or open) and container tags. These tags
differ because of what they represent. Empty tags represent formatting
constructs, such as line breaks and horizontal rules. These tags indicate
"one time" instructions that WWW viewers can read and execute
without concern for any other
HTML
uses two types of elements: empty (or open) and container tags. These tags
differ because of what they represent. Empty tags represent formatting
constructs, such as line breaks and horizontal rules. These tags indicate
"one time" instructions that WWW viewers can read and execute
without concern for any other ![]() HTML
construction or document text.
HTML
construction or document text.
![]() Container
tags define a section of text (or of the document itself) and specify the
formatting or construction for all of the selected text. A container tag
has both a beginning and an ending: the ending tag is identical to the
beginning tag, with the addition of a forward slash. Most containers can
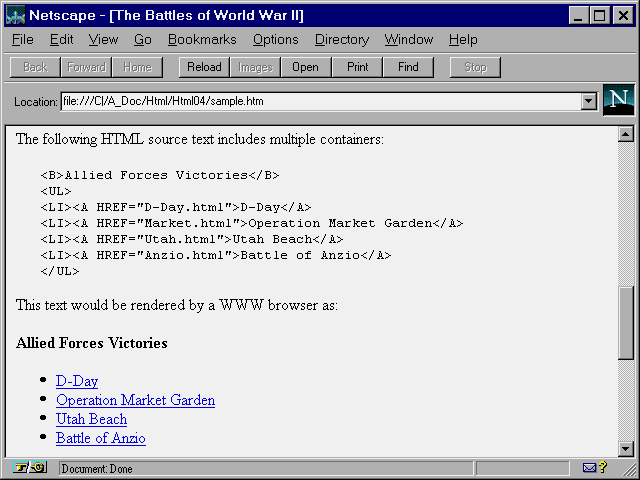
overlap and hold other containers or empty tags (see
fig. 4.7).
Container
tags define a section of text (or of the document itself) and specify the
formatting or construction for all of the selected text. A container tag
has both a beginning and an ending: the ending tag is identical to the
beginning tag, with the addition of a forward slash. Most containers can
overlap and hold other containers or empty tags (see
fig. 4.7).
Containers can hold other elements-the entire ![]() HTML
document is actually one large container, defined by the tag <HTML>.
HTML
document is actually one large container, defined by the tag <HTML>.
I'm not talking about disagreements between tags in HTML documents.
Like command-line applications, many ![]() HTML
elements use additional parameters (known as arguments or attributes) to
increase their functionality. These arguments are passed on to the client
software and affect the way the element is applied to the section of text
(or, with empty tags, how the tag's construct is displayed in the viewing
software's window).
HTML
elements use additional parameters (known as arguments or attributes) to
increase their functionality. These arguments are passed on to the client
software and affect the way the element is applied to the section of text
(or, with empty tags, how the tag's construct is displayed in the viewing
software's window).
For example, the ![]() anchor
element uses arguments to define the function of the anchor (whether it's
a marker or a hypertext link to another document or anchor). So, a document
can contain links to specific sections of text and named anchors at those
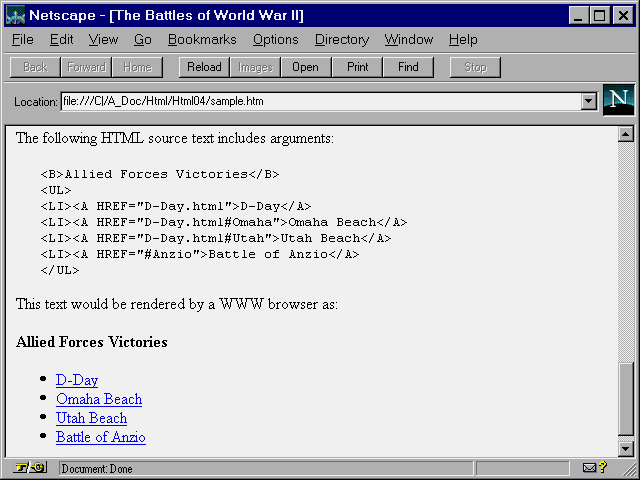
text locations (see fig. 4.8). Notice that
the parameters are contained in the tag's angle brackets.
anchor
element uses arguments to define the function of the anchor (whether it's
a marker or a hypertext link to another document or anchor). So, a document
can contain links to specific sections of text and named anchors at those
text locations (see fig. 4.8). Notice that
the parameters are contained in the tag's angle brackets.
You use anchors as both the starting and ending points of ![]() hypertext
links in
hypertext
links in ![]() HTML
documents.
HTML
documents.
In this example, the last line in the list
<LI><A HREF="#Anzio">Battle of AnzioD-Day</A>
is an anchor that points to a named anchor somewhere else in the document. The named anchor it points to would be found in a line such as
<A NAME="Anzio"><H1>The Battle of Anzio</H1></A>
When the user clicks the list item D-Day in the viewed document, the WWW browser would jump immediately to the associated named anchor.
Underlining and colored borders (such as red or green) are used in some
Some WWW viewers, notably Netscape Navigator and Microsoft Internet Explorer, provide support for non-standard arguments that primarily affect the display of the HTML text in the viewer's window. WWW viewers that don't support non-standard elements or arguments just ignore them. Non-standard usage is noted in chapters 15 and 16.
See "Netscape-Specific Extensions to HTML", (ch. 15)
See "Additional HTML Extensions Supported by Other Browsers", (ch. 16)
If you incorporate non-standard HTML in your own documents, let users know with a simple statement at the head of your "entry-point" document (usually the "Welcome" or introduction page). This way, they know that a given browser displays your Web pages as you intended them to be seen. Both Netscape and Microsoft have programs that allow you to include special messages and icons on your web pages indicating that they are best viewed with their browsers.
Tables 4.1, 4.2, and 4.3 provide a brief overview of some of more common
![]() HTML
elements found in different sections of
HTML
elements found in different sections of ![]() HTML
documents. These tables don't include arguments but they do include the
element's tag type. The entire
HTML
documents. These tables don't include arguments but they do include the
element's tag type. The entire ![]() HTML
document should be contained in the
HTML
document should be contained in the ![]() HTML
container element. For a complete description of each element and its associated
arguments, see Appendix A.
HTML
container element. For a complete description of each element and its associated
arguments, see Appendix A.
![]() Table
4.1 HTML Elements for
Table
4.1 HTML Elements for ![]() Head
Sections in
Head
Sections in ![]() HTML
Documents
HTML
Documents
| Element | Element Type | Description |
| BASE | empty | Base context document |
| HEAD | container | Document head |
| ISINDEX | empty | Document is a searchable index |
| LINK | empty | Link from this document |
| META | container | Generic meta-information |
| NEXTID | empty | Next ID to use for link name |
| TITLE | container | Title of document |
Table 4.2 HTML Elements for Body Sections in HTML Documents
| Element | Element Type | Description |
| A | container | Anchor: source and/or destination of a link |
| ADDRESS | container | Address, signature, or byline for a document or passage |
| B | container | Bold text |
| BLOCKQUOTE | container | Quoted passage |
| BODY | container | Document body |
| BR | empty | Line break |
| CITE | container | Name or title of cited work |
| CODE | container | Source code phrase |
| DD | empty | Definition of term |
| DIR | container | Directory list |
| DL | container | Definition list, or glossary |
| DT | empty | Term in definition list |
| EM | container | Emphasized phrase |
| H1 | container | Heading, level 1 |
| H2 | container | Heading, level 2 |
| H3 | container | Heading, level 3 |
| H4 | container | Heading, level 4 |
| H5 | container | Heading, level 5 |
| H6 | container | Heading, level 6 |
| HR | empty | Horizontal rule |
| I | container | Italic text |
| IMG | empty | Image; icon, glyph, or illustration |
| KBD | container | Keyboard phrase, such as user input |
| LI | empty | List item |
| LISTING | container | Computer listing |
| MENU | container | Menu list |
| OL | container | Ordered or numbered list |
| P | empty | Paragraph |
| PRE | container | Preformatted text |
| SAMP | container | Sample text or characters |
| SELECT | empty | Selection of option(s) |
| STRONG | container | Strong emphasis |
| TT | container | Typewriter text |
| UL | container | Unordered list |
| VAR | container | Variable phrase or substitutable |
| XMP | container | Example section |
As the HTML standard changes, elements will be deprecated, or replaced by new elements with greater functionality. Deprecated elements will still be supported by existing WWW viewers but may not be in the future. Be prepared to review your older HTML documents for deprecated elements that may no longer be useful.
Table 4.3 HTML Elements for Forms in HTML Documents
| Element | Element Type | Description |
| FORM | container | Fill-out or data-entry form |
| INPUT | empty | Form input datum |
| TEXTAREA | empty | Area for text input |
| OPTION | empty | Selection option |


|


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}