Notice: This material is excerpted from Special Edition Using HTML, 2nd Edition, ISBN: 0-7897-0758-6. This material has not yet been through the final proof reading stage that it will pass through before being published in printed form. Some errors may exist here that will be corrected before the book is published. This material is provided "as is" without any warranty of any kind.
by Jim O'Donnell
Creating an accurate document head is the first step to writing good
![]() HTML.
Fortunately, it's also the easiest. The head section of an
HTML.
Fortunately, it's also the easiest. The head section of an ![]() HTML
document precedes the main content of the document. Similar to the banner
page of a magazine, the head provides information for both the viewer software
and the end user.
HTML
document precedes the main content of the document. Similar to the banner
page of a magazine, the head provides information for both the viewer software
and the end user.
This chapter answers the following questions:
HTML documents are platform-independent, meaning that they don't
conform to any one system standard. If they are created properly, you can
move home pages to any server platform, or you can access them with any
compliant WWW viewer. One way to indicate this independence is the <HTML>
tag. Because ![]() HTML
documents are not compiled (or processed) for execution, some applications
need a hint to know how to interpret the plain text in a home page. That's
where the <HTML> tag comes into play.
HTML
documents are not compiled (or processed) for execution, some applications
need a hint to know how to interpret the plain text in a home page. That's
where the <HTML> tag comes into play.
Remember that the <HTML> and </HTML> tags should be the
first and last elements of your HTML document. Although most viewers can
handle a home page without the <HTML> tag, it is recommended that
all your HTML documents use it (see fig. 5.1).
The end of the ![]() HTML
container is defined with the end tag </HTML>.
HTML
container is defined with the end tag </HTML>.
Using the <HTML> and </HTML> tags to open and close your
![]() HTML
documents is a good idea.
HTML
documents is a good idea.
Technically, the <HTML> tag is not part of the head section, as it contains all the HTML portions of the current document, including the head section. But, for purposes of clarity, the tag is presented here, where users begin to write their HTML code. The tag's closing component, </HTML>, comes at the very end of the document, like the traditional "The End" at the end of a book or movie. Logically, the closing is unnecessary (after all, if the file contains no more text, the document is ended). But, as a matter of good usage, take the extra second or two to include the </HTML> line.
Files without the <HTML> tag can be misinterpreted as text-only
documents, and the markup tags as just more text on the page. This fact
is particularly relevant as other applications increasingly access existing
![]() HTML
documents without the presumption that the document is HTML and not a plain
text file (mail and news readers, for instance).
HTML
documents without the presumption that the document is HTML and not a plain
text file (mail and news readers, for instance).
The head section is like a quick reference for WWW viewers and other
applications that access HTML files. The head supplies the document title
and establishes relationships between ![]() HTML
documents and file directories. The document head can signal the WWW viewer
to use its search capabilities to index the current document.
HTML
documents and file directories. The document head can signal the WWW viewer
to use its search capabilities to index the current document.
![]() HTML
provides the
HTML
provides the ![]() HEAD
element to define the head section in a document. The <HEAD> tag
encloses or contains the head section (which is enclosed by the <HTML>
tag). The closing </HEAD> tag sets the bounds for the head section.
The only element in the head section displayed by the end user's viewer
is the value of the
HEAD
element to define the head section in a document. The <HEAD> tag
encloses or contains the head section (which is enclosed by the <HTML>
tag). The closing </HEAD> tag sets the bounds for the head section.
The only element in the head section displayed by the end user's viewer
is the value of the ![]() TITLE
element. Figure 5.2 shows a typical document
head.
TITLE
element. Figure 5.2 shows a typical document
head.
The elements in a document head define its function and clearly show the relationships between the document and other files.
Writing proper document heads is not only good ![]() HTML,
it also prepares your documents to be used by additional applications (such
as WAIS searches) and other future, undefined uses.
HTML,
it also prepares your documents to be used by additional applications (such
as WAIS searches) and other future, undefined uses.
It's not a head element, but it's a good idea to include a comment, enclosed in "<!--" "-->" to explain, describing the document in the head section.
Using the TITLE element is as simple as it sounds-the ![]() TITLE
element "names" your document. The title doesn't assign a file
name to a document; it defines a text string that is interpreted as the
HTML title of the document. The actual file name is incidental (thankfully);
most file systems either limit the number of characters in a file name
or limit the use of "special" characters that are required by
the system (such as the / character). In HTML titles, any character can
be displayed.
TITLE
element "names" your document. The title doesn't assign a file
name to a document; it defines a text string that is interpreted as the
HTML title of the document. The actual file name is incidental (thankfully);
most file systems either limit the number of characters in a file name
or limit the use of "special" characters that are required by
the system (such as the / character). In HTML titles, any character can
be displayed.
The
HTML character set does reserve some characters for special uses, such as the "less than" and "greater than" angle brackets. However, you can display these characters in your software viewer by using their HTML "entity" equivalents. If you try to use the special characters as normal, the viewer software either ignores them or displays the rest of the document's body text in unexpected (and unwanted) ways.
Many Windows-based viewers display the ![]() TITLE
text in a title bar, or at the top of the document (see
fig. 5.3).
TITLE
text in a title bar, or at the top of the document (see
fig. 5.3).
Windows viewers display the text in the viewer's interface.
![]() HTML
doesn't limit the length of the
HTML
doesn't limit the length of the ![]() TITLE
element. However, before you rush off to give your documents voluminous
and wonderfully expository titles, consider the space where the title is
displayed (the viewer's title bar or window label). A good rule of thumb
for the length of a title is no more than a single phrase or no longer
than 60 characters. See figure 5.4 for an
incorrect use of TITLE.
TITLE
element. However, before you rush off to give your documents voluminous
and wonderfully expository titles, consider the space where the title is
displayed (the viewer's title bar or window label). A good rule of thumb
for the length of a title is no more than a single phrase or no longer
than 60 characters. See figure 5.4 for an
incorrect use of TITLE.
![]() TITLE
values that are too long might get cut off by the viewer's title bar or
window, decreasing the effectiveness of the
TITLE
values that are too long might get cut off by the viewer's title bar or
window, decreasing the effectiveness of the ![]() home
page.
home
page.
When a user adds your document to his or her viewer's "hot list" or bookmark list, the
Troubleshooting
I put a TITLE statement in the head section, but some people complain that their viewers display something else. What's happening?
You probably made a mistake in your document's head section, either leaving off an angle bracket or forgetting the closing tag </TITLE>. Although some viewers try to catch these errors and display what they think the author intended, others don't. Viewers can display all sorts of nasty text with a
Although viewers have a limited capability to display a document's ![]() TITLE
value, by combining the
TITLE
value, by combining the ![]() TITLE
text with a lead heading statement, you can effectively create a "1-2"
punch with your introductory text. This approach can provide a way of including
a longer title for your document, including the longer title within the
document as the lead heading and a shorter version as the actual title
(see fig. 5.5.)
TITLE
text with a lead heading statement, you can effectively create a "1-2"
punch with your introductory text. This approach can provide a way of including
a longer title for your document, including the longer title within the
document as the lead heading and a shorter version as the actual title
(see fig. 5.5.)
Using a lead heading to title your document allows you to include longer titles than can be used in the TITLE element.
Computer files are glorious things: small, lightweight, easily transportable. With a few keystrokes, you can relocate entire directories of files, or files with similar names or extensions. Reorganizing a hard disk of files or creating copies on a different system doesn't take a great deal of work (or knowledge). And making havoc of an orderly file system doesn't take any effort at all.
As the volume of HTML files under your management increases, you'll be thankful for two elements HTML uses for document heads. These tags serve to connect HTML documents to each other and to their authors.
![]() HTML
documents often rely on the
HTML
documents often rely on the ![]() physical
locations of other
physical
locations of other ![]() HTML
files. A document might include a pointer to another document, for instance
(see fig. 5.6).
HTML
files. A document might include a pointer to another document, for instance
(see fig. 5.6).
Pointers in ![]() HTML
documents can point to other documents (as shown here), or to other locations
in the same document.
HTML
documents can point to other documents (as shown here), or to other locations
in the same document.
The HTML <BASE> tag acts somewhat like the DOS PATH statement;
it provides an additional file directory location for the WWW viewer to
refer to when looking up a document link. By specifying a value for <BASE>
in your document head, you can shorten the URL statements by using relative
URLs in your document's anchor and image links. <BASE> protects relative
URL links in the document from "breaking" should the file be
physically moved. Figure 5.7 demonstrates
a proper ![]() BASE
statement.
BASE
statement.
The value of <BASE> is a link to the document's absolute ![]() URL
location written in the form of an
URL
location written in the form of an ![]() anchor
link.
anchor
link.
If no ![]() BASE
value exists in a document, the WWW viewer assumes that relative URLs derive
from the current
BASE
value exists in a document, the WWW viewer assumes that relative URLs derive
from the current ![]() directory
of the HTML document.
directory
of the HTML document.
Often one problem associated with managing a growing volume of ![]() HTML
files is determining which files belong together or who is the proper author
of a file. Losing track of files is very easy when a single home page can
use an unlimited number of file links (and these files can be local or
on a remote server). Using LINK, you can easily solve these problems.
HTML
files is determining which files belong together or who is the proper author
of a file. Losing track of files is very easy when a single home page can
use an unlimited number of file links (and these files can be local or
on a remote server). Using LINK, you can easily solve these problems.
Authorship on the
![]() LINK
statements define relationships between the current document and other
documents, the author, or Web clients. They generally include a
LINK
statements define relationships between the current document and other
documents, the author, or Web clients. They generally include a ![]() hypertext
reference in the form of a URL and an attribute value that explains what
the document's relationship with this URL is. Refer to appendix
A, "HTML Tags," for more information about LINK attributes.
hypertext
reference in the form of a URL and an attribute value that explains what
the document's relationship with this URL is. Refer to appendix
A, "HTML Tags," for more information about LINK attributes.
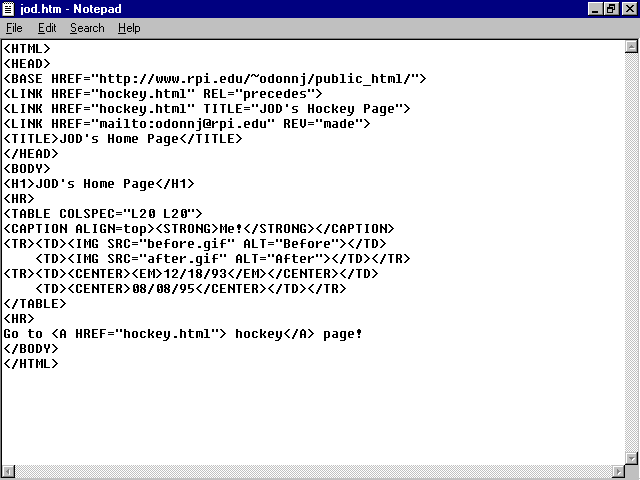
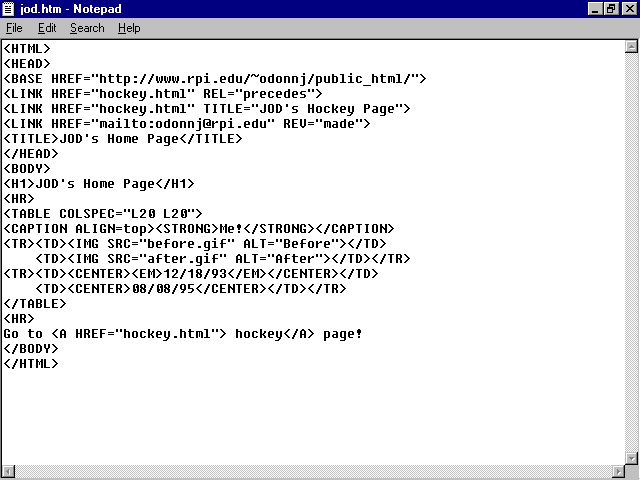
A document can include multiple ![]() LINK
statements using as many attributes as necessary (see
fig. 5.8). These attributes are shown in table 5.1.
LINK
statements using as many attributes as necessary (see
fig. 5.8). These attributes are shown in table 5.1.
![]() LINK
options and attributes apply to the entire
LINK
options and attributes apply to the entire ![]() HTML
document.
HTML
document.
![]() Table
5.1 LINK Attributes and Their
Table
5.1 LINK Attributes and Their ![]() Functions
Functions
| Attribute | Function |
|---|---|
| HREF | Points to a URL |
| REL | Defines the relationship between the current document and an HREF value |
| REV | Like REL, defines the relationship between the HREF value and the document (the opposite association) |
| NAME | Defines a link from an anchor or URL to this document |
| URN | Defines a Uniform Resource Number for the current document |
| TITLE | Functions the same as the <TITLE> tag in the head of the associated HREF |
| METHODS | Provides a list of functions supported by the current document; how it can be used by a viewer |
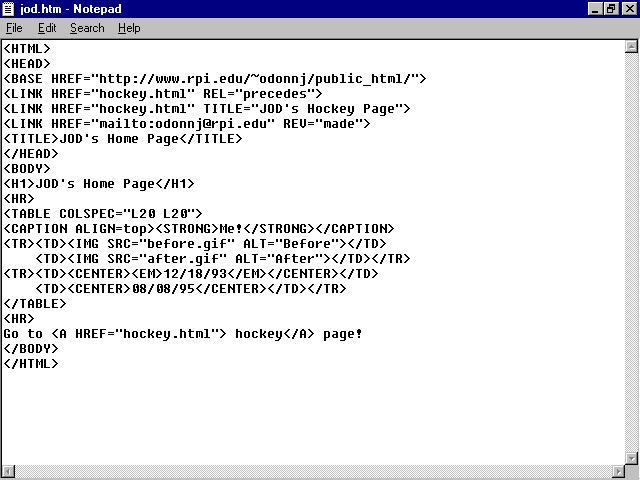
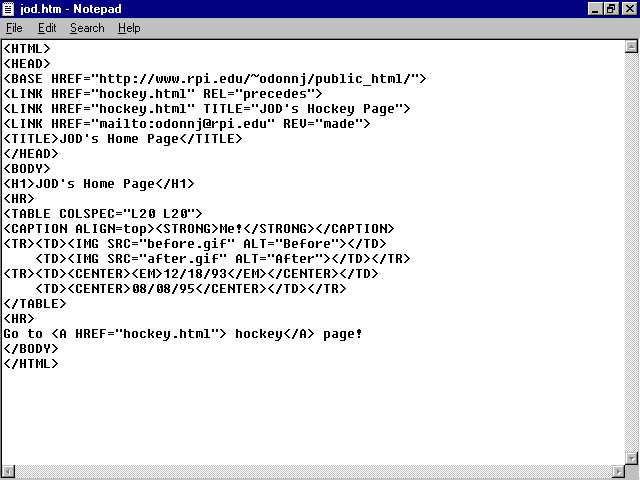
In this example, the ![]() LINK
statements are performing three tasks. The first statement
LINK
statements are performing three tasks. The first statement
<LINK HREF="hockey.html" REL="precedes">
tells the Web viewer that the current document (index.![]() html)
comes before the identified
html)
comes before the identified ![]() URL
document (hockey.html).
URL
document (hockey.html).
The second statement
<LINK HREF="hockey.html" TITLE="Hockey Stuff">
identifies the title (Hockey Stuff) for the specified document (hockey.html).
The third statement
<LINK HREF="mailto:odonnj@rpi.edu" REV="made">
says that the author of this document (REV="made") is described at the following hypertext reference-in this case, an e-mail window that allows you to send a message to the author, odonnj@rpi.edu.
Of the attributes listed in table 5.1, HREF, NAME, REL, and REV are
most often used. As ![]() HTML
documents begin to be used by more applications, these values and attributes
will become important to assist programs in using
HTML
documents begin to be used by more applications, these values and attributes
will become important to assist programs in using ![]() HTML
documents.
HTML
documents.
HTML documents can be long and complex. Searching for specific information in these documents is a tedious job, especially when the terminology you're looking for varies. What you need is a simple method for doing a difficult job, and in HTML, where there's a need, there's often a solution (or two).
Consider the example of an ![]() HTML
document that lists classical composers and their works with associated
HTML
document that lists classical composers and their works with associated
![]() music
data files and a brief synopsis for each work. Searching such a document
for a specific
music
data files and a brief synopsis for each work. Searching such a document
for a specific ![]() musical
composition, or an obscure composer, could take some time. What you want
is an efficient way to retrieve this information (especially if you're
providing this document for wide use and you want people to come back for
more).
musical
composition, or an obscure composer, could take some time. What you want
is an efficient way to retrieve this information (especially if you're
providing this document for wide use and you want people to come back for
more).
![]() HTML
provides the
HTML
provides the ![]() ISINDEX
element for just such a need. ISINDEX signals the WWW viewer to use its
internal capabilities to generate a simple search form, where the user
enters one or more search variables (separated by commas) in a blank and
clicks the
ISINDEX
element for just such a need. ISINDEX signals the WWW viewer to use its
internal capabilities to generate a simple search form, where the user
enters one or more search variables (separated by commas) in a blank and
clicks the ![]() Search
button. (The viewer can still view and read the document normally if a
user doesn't want to perform a keyword search.) The viewer passes the search
information to the document's server, which performs the search.
Search
button. (The viewer can still view and read the document normally if a
user doesn't want to perform a keyword search.) The viewer passes the search
information to the document's server, which performs the search.
Having the
ISINDEX requires no additional information or attributes-just add it to the head section of a document you want to make searchable.
Figure 5.9 shows how ISINDEX is included in the head of an ![]() HTML
document used for searching a long
HTML
document used for searching a long ![]() HTML
document of classical music. Figure 5.10 shows the resulting search form
at the bottom of the
HTML
document of classical music. Figure 5.10 shows the resulting search form
at the bottom of the ![]() Web
page; entering text into the form and pressing Enter (or clicking the Submit
button that some viewers provide) begins a search for the next occurrence
of the text string.
Web
page; entering text into the form and pressing Enter (or clicking the Submit
button that some viewers provide) begins a search for the next occurrence
of the text string.
Fig. 5.9
The ![]() ISINDEX
element requires no attributes or document information; it signals the
viewer to provide a search form.
ISINDEX
element requires no attributes or document information; it signals the
viewer to provide a search form.
Fig. 5.10
The WWW viewer displays a search field when it finds the ISINDEX element in the document head; press Enter to start a search based on the text string in the search field.
Your ![]() Web
server may not have a search engine to make ISINDEX a useful tool. An HTML
document author, with sufficient time and desperation (and a Web site administrator
who can't provide the necessary search program), can create a "rolodex"
or "organizer" effect in a document. This effect is possible
using anchors. Figure 5.11 shows an anchored
index in a document.
Web
server may not have a search engine to make ISINDEX a useful tool. An HTML
document author, with sufficient time and desperation (and a Web site administrator
who can't provide the necessary search program), can create a "rolodex"
or "organizer" effect in a document. This effect is possible
using anchors. Figure 5.11 shows an anchored
index in a document.
An ![]() HTML
document can incorporate a rolodex-type search feature using named anchors;
click an alphabetical category to jump to that point in the Web page.
HTML
document can incorporate a rolodex-type search feature using named anchors;
click an alphabetical category to jump to that point in the Web page.
This search function works using the HTML ANCHOR element; by defining each letter as an anchor link to a named anchor, the user can click that letter and jump immediately to the specified point in the document.
For example, in figure 5.11, the list of letters would begin like this in HTML:
<A HREF="#A">A</A> <A HREF="#B">B</A>
And so on. Clicking the highlighted B in the viewer window would jump
to the line of ![]() HTML
in the document that includes the following named anchor:
HTML
in the document that includes the following named anchor:
<A NAME="B">BACH</A>
The ![]() HTML
specification includes a mechanism to include other meta-information,
information about the document, beyond the things such as title and base
that have defined head section elements. This mechanism is the META element,
which you can use to embed specialized information into the document header.
The
HTML
specification includes a mechanism to include other meta-information,
information about the document, beyond the things such as title and base
that have defined head section elements. This mechanism is the META element,
which you can use to embed specialized information into the document header.
The ![]() META
element has the three attributes shown in table 5.2.
META
element has the three attributes shown in table 5.2.
![]() Table
5.2 META Attributes and Their
Table
5.2 META Attributes and Their ![]() Functions
Functions
| Attribute | Function |
|---|---|
| HTTP-EQUIV | Binds the META element to an HTTP response header. |
| NAME | Names a property such as author, publication date, or similar. If the NAME element is not specified, it is assumed to be the same as HTTP-EQUIV. |
| CONTENT | Supplies a value for a named property. |
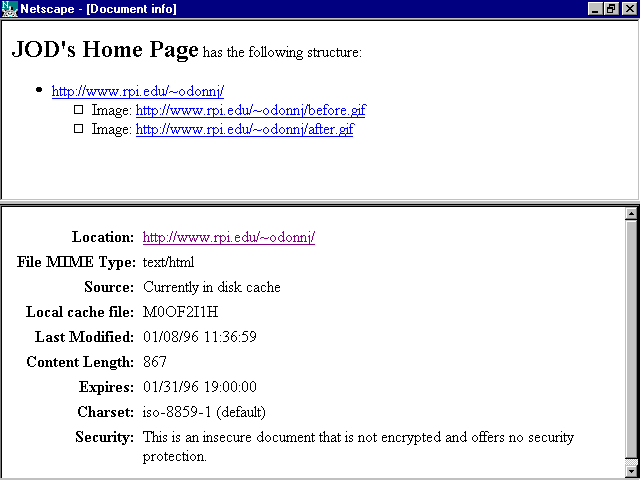
Suppose, for example, that the document contains the following META elements:
<META HTTP-EQUIV="Expires" CONTENT="Thu, 01 Feb 1996 00:00:00 GMT"> <META HTTP-EQUIV="Reply-To" CONTENT="odonnj@rpi.edu (Jim O'Donnell)"> <META HTTP-EQUIV="Keywords" CONTENT="before, after">
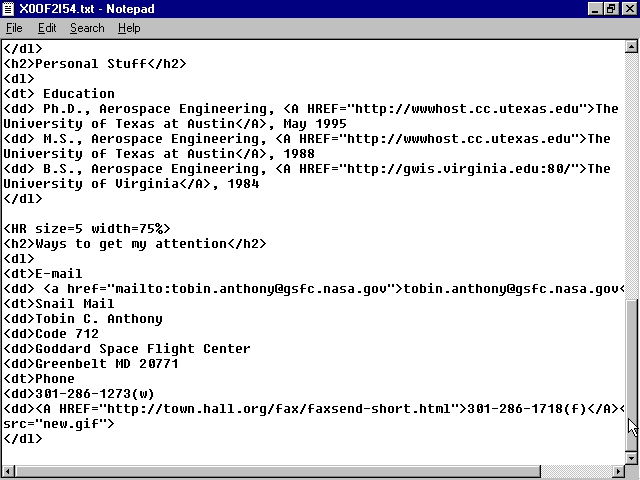
Then if you view it and display the document information, you see the information shown in figure 5.12 (notice that the HTTP server converted the expired time from GMT to local time). The HTTP server on which I have my home page supports the Expires HTTP-EQUIV attribute of the META element but not the Keywords or Reply-To attributes. Unsupported attributes are ignored by the server.
Specifying supported HTTP-EQUIV META elements includes that information in the document information view.
When no equivalent ![]() HTTP
response headers are available, you should use the NAME attribute instead
of HTTP-EQUIV. Examples of this use of the META element are as follows:
HTTP
response headers are available, you should use the NAME attribute instead
of HTTP-EQUIV. Examples of this use of the META element are as follows:
<META NAME="Last Validated" CONTENT="Mon, 01 Jan
1996 09:23:12 GMT">
<META NAME="Web Page Type" CONTENT="Personal">
<META NAME="Special Features" CONTENT="None">


|



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}