Notice: This material is excerpted from Special Edition Using HTML, 2nd Edition, ISBN: 0-7897-0758-6. This material has not yet been through the final proof reading stage that it will pass through before being published in printed form. Some errors may exist here that will be corrected before the book is published. This material is provided "as is" without any warranty of any kind.
by Mark Brown
Contrary to what the media would have you believe, the ![]() World
Wide Web did not spring into being overnight. Though relatively new in
human terms, the Web has a venerable
World
Wide Web did not spring into being overnight. Though relatively new in
human terms, the Web has a venerable ![]() genealogy
for a computing technology. It can trace its roots back over 25 years,
which is more than half the distance back to the primordial dawn of the
electronic computing age.
genealogy
for a computing technology. It can trace its roots back over 25 years,
which is more than half the distance back to the primordial dawn of the
electronic computing age.
However, the media is right in noting that the Web's phenomenal growth has so far outstripped that of any of its predecessors that, like a prize hog, it has left almost no room at the trough for any of them anymore. But like that prize hog, the Web is so much bigger and better and so much more valuable than the network technologies that preceded it, there is little reason to mourn the fact that they've been superseded.
In this chapter I'll discuss the history, development, and characteristics of the Web. You'll find out where it came from and what it's good for. If you're the impatient type and you want to just start using HTML to develop Web pages as quickly as possible, you can certainly skip this chapter and jump right in. However, as with all things, a little understanding of the background and underlying structure of the Web will not only enhance your enjoyment of and appreciation for what it is and what it can do, but it might even give you some insights into how to approach the development of your own Web sites.
The Web came out of the ![]() Internet,
and it is both empowered and limited by the structure of the
Internet,
and it is both empowered and limited by the structure of the ![]() Internet.
Today, most
Internet.
Today, most ![]() Web
browsers include the capability to access other
Web
browsers include the capability to access other ![]() Internet
technologies, such as Gopher, e-mail, and Usenet news, as well as the World
Wide Web. So the more you know about the Internet as a whole, as well as
the Web's place in it, the better you'll understand how to exploit the
entire Net to its fullest potential.
Internet
technologies, such as Gopher, e-mail, and Usenet news, as well as the World
Wide Web. So the more you know about the Internet as a whole, as well as
the Web's place in it, the better you'll understand how to exploit the
entire Net to its fullest potential.
Then, too, the Web and the ![]() Internet
are more than just technology: they are an environment in which the members
of an entire cyberculture communicate, trade, and interact. If you hope
to establish your own Web site and make yourself a part of that culture,
you'd better know what you're getting into. In a way, it's like moving
to another country and trying to set up shop; if you don't speak the lingo
and learn the customs, you'll never become a part of the community.
Internet
are more than just technology: they are an environment in which the members
of an entire cyberculture communicate, trade, and interact. If you hope
to establish your own Web site and make yourself a part of that culture,
you'd better know what you're getting into. In a way, it's like moving
to another country and trying to set up shop; if you don't speak the lingo
and learn the customs, you'll never become a part of the community.
In the late 1950s, at the height of the Cold War, the ![]() Department
of Defense began to worry about what would happen to the nation's
Department
of Defense began to worry about what would happen to the nation's ![]() communications
systems in the event of an
communications
systems in the event of an ![]() atomic
war. It was obvious that maintaining communications would be vital to the
waging of a worldwide war, but it was also obvious that the very nature
of an all-out
atomic
war. It was obvious that maintaining communications would be vital to the
waging of a worldwide war, but it was also obvious that the very nature
of an all-out ![]() nuclear
conflict would practically guarantee that the nation's existing
nuclear
conflict would practically guarantee that the nation's existing ![]() communications
systems would be knocked out.
communications
systems would be knocked out.
In 1962, Paul Baran, a researcher at the government's RAND think tank, described a solution to the problem in a paper titled "On Distributed Communications Networks." He proposed a nationwide system of computers connected together using a decentralized network so that if one or more major nodes were destroyed, the rest could dynamically adjust their connections to maintain communications.
If, for example, a computer in Washington, D.C., needed to communicate
with one in Los Angeles, it might normally pass the information first to
a computer in Kansas City, then on to L.A. But if ![]() Kansas
City were destroyed or knocked out by an
Kansas
City were destroyed or knocked out by an ![]() A-bomb
blast, the Washington computer could reroute its communications through,
say, Chicago instead, and the data would still arrive safely in L.A. (though
too late to help the unfortunate citizens of Kansas City).
A-bomb
blast, the Washington computer could reroute its communications through,
say, Chicago instead, and the data would still arrive safely in L.A. (though
too late to help the unfortunate citizens of Kansas City).
The proposal was discussed, developed, and expanded by various members
of the computing community. In 1969, the first ![]() packet-switching
network was funded by the
packet-switching
network was funded by the ![]() Pentagon's
Advanced Research Projects Agency (ARPA).
Pentagon's
Advanced Research Projects Agency (ARPA).
So What's Packet Switching?
Packet switching is a method of breaking up data files into small pieces-usually only a couple of kilobytes or less-called packets, which can then be transmitted to another location. There, the packets are reassembled to recreate the original file. Packets don't have to be transmitted in order or even by the same route. In fact, the same packet can be transmitted by several different routes just in case some don't come through. The receiving software at the other end throws away duplicate packets, checks to see if others haven't come through (and asks the originating computer to try to send them again), sorts them into their original order, and puts them back together again into a duplicate of the original data file. Although this isn't the fastest way to transmit data, it is certainly one of the most reliable.
Besides the original file data, data packets may include information about where they came from, the places they've visited in transit, and where they're going to. The data they contain may be compressed and/or encrypted. Packets almost always also include some kind of information to indicate whether the data that arrives at the destination is the same data that was sent in the first place.
ARPAnet, as it was called, linked four research facilities: the University of California at Los Angeles (UCLA), the Stanford Research Institute (SRI), the University of California at Santa Barbara (UCSB), and the University of Utah. By 1971, ARPAnet had grown to include 15 nodes; there were a grand total of 40 by 1972. That year also marked the creation of the InterNetworking Working Group (INWG), which was needed to establish common protocols for the rapidly growing system.
For more on the history of the Internet, consult Bruce Sterling's excellent article on the topic at gopher://oak.zilker.net:70/00/bruces/F_SF_Science_Column/F_SF_Five_.
Because ARPAnet was decentralized, it was easy for computer administrators
to add their machines to the network. All they needed was a phone line,
a little hardware, and some free NCP (Network Control Protocol)
software. Within just a few years, there were over a hundred ![]() mainframe
computers connected to ARPAnet, including some overseas.
mainframe
computers connected to ARPAnet, including some overseas.
ARPAnet immediately became a forum for the exchange of information and
ideas. Collaboration among scientists and educators was the number one
use of the system, and the main incentive for new sites to want to be connected.
Thus, it is not surprising that the first major application developed for
use on the ARPAnet was ![]() electronic
mail.
electronic
mail.
With the advent of Ray Tomlinson's e-mail system in 1972, researchers
connected to the Net could establish one-on-one ![]() communication
links with colleagues all over the world and could exchange ideas and research
at a pace never before imagined. With the eventual addition of the ability
to send mail to multiple recipients, mailing lists were born and users
began open discussions on a multitude of topics, including "frivolous"
topics, such as science fiction.
communication
links with colleagues all over the world and could exchange ideas and research
at a pace never before imagined. With the eventual addition of the ability
to send mail to multiple recipients, mailing lists were born and users
began open discussions on a multitude of topics, including "frivolous"
topics, such as science fiction.
There are thousands of mailing lists you can subscribe to on the Internet today, covering topics as diverse as PERL programming and dog breeding. For a list of some of the many mailing lists available on the Net, check out Stephanie de Silva's list of Publicly Accessible Mailing Lists, updated monthly, at http://www.neosoft.com/internet/paml/, the list of LISTSERV lists at http://tile.net/listserv/, or the forms-searchable Liszt database of 25,000 mailing lists at http://www.liszt.com/.
![]() E-mail
has proven its value over time and has remained one of the major uses of
the
E-mail
has proven its value over time and has remained one of the major uses of
the ![]() Net.
In fact, e-mail is now handled internally by many World Wide Web browsers,
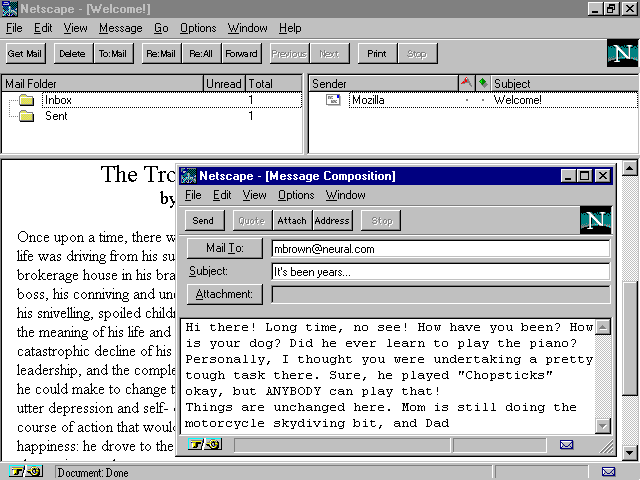
such as Netscape 2.0 (see fig. 1.1), so
a separate e-mail program is not required.
Net.
In fact, e-mail is now handled internally by many World Wide Web browsers,
such as Netscape 2.0 (see fig. 1.1), so
a separate e-mail program is not required.
Fig. 1.1
Reading or sending ![]() e-mail
with
e-mail
with ![]() Netscape
Navigator 2.0 brings up a separate
Netscape
Navigator 2.0 brings up a separate ![]() e-mail
window, shown here.
e-mail
window, shown here.
See "Linking HTML Documents"
You can find answers to most of your questions about
Deciphering ![]() Internet
e-mail addresses can be a bit challenging. Like a letter sent through the
mail, an
Internet
e-mail addresses can be a bit challenging. Like a letter sent through the
mail, an ![]() electronic
mail message must be sent to a specific address (or list of addresses).
The format for an e-mail address is name@site (which is verbalized
as "name at site").
electronic
mail message must be sent to a specific address (or list of addresses).
The format for an e-mail address is name@site (which is verbalized
as "name at site").
The name portion of the address is the recipient's personal ![]() e-mail
account name. At many sites, this may be the user's first initial and last
name. For example, my
e-mail
account name. At many sites, this may be the user's first initial and last
name. For example, my ![]() e-mail
account name is
e-mail
account name is ![]() mbrown.
However,
mbrown.
However, ![]() e-mail
names consist of anything from an obscure set of numbers and/or letters
(70215.1034) to a funky nickname (spanky). (One nearly ubiquitous
e-mail
names consist of anything from an obscure set of numbers and/or letters
(70215.1034) to a funky nickname (spanky). (One nearly ubiquitous
![]() e-mail
name is
e-mail
name is ![]() webmaster.
This
webmaster.
This ![]() generic
name is used by Webmasters at most of the
generic
name is used by Webmasters at most of the ![]() Web
sites in the world.)
Web
sites in the world.)
The site portion of an ![]() e-mail
address is the
e-mail
address is the ![]() domain
name of the server that the account is on. For example, all
domain
name of the server that the account is on. For example, all ![]() America
Online users are at
America
Online users are at ![]() aol.com,
and all
aol.com,
and all ![]() CompuServe
users are at
CompuServe
users are at ![]() compuserve.com.
I'm at neural.com, so my complete
compuserve.com.
I'm at neural.com, so my complete ![]() e-mail
address is mbrown@neural.com.
e-mail
address is mbrown@neural.com.
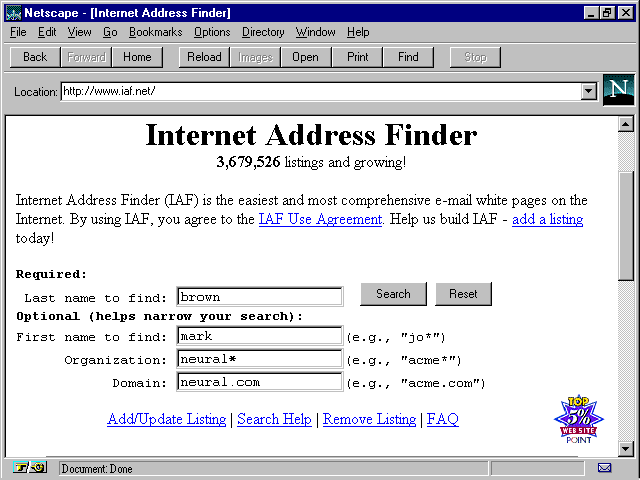
If you don't know someone's e-mail address, there are a variety of "white pages" services available on the Web for looking them up. As always, a good list of such services can be found on Yahoo! at http://www.yahoo.com/Reference/White_Pages/. My current favorite is the Internet Address Finder at http://www.iaf.net/ (see fig. 1.2).
For more information on Internet e-mail addresses, including lists of domain names for many popular online services, see John J. Chew's and Scott Yanoff's interactive forms-based "Inter-Network Mail Guide" at http://alpha.acast.nova.edu/cgi-bin/inmgq.pl.
The ![]() Internet
Address Finder can be used to find the
Internet
Address Finder can be used to find the ![]() e-mail
addresses of over 3.5 million
e-mail
addresses of over 3.5 million ![]() Internet
users.
Internet
users.
A logical extension of the mailing list is the ![]() interactive
conference, or
interactive
conference, or ![]() newsgroup.
The concept of
newsgroup.
The concept of ![]() interactive
conferencing actually predates the existence of the computers to do it
on; it was first proposed by Vannevar Bush in an article titled "As
We May Think" in the Atlantic Monthly in 1945 (v196(1), p.
101-108).
interactive
conferencing actually predates the existence of the computers to do it
on; it was first proposed by Vannevar Bush in an article titled "As
We May Think" in the Atlantic Monthly in 1945 (v196(1), p.
101-108).
The first actual ![]() online
conferencing system was called Delphi (after the Greek oracle),
and it debuted in 1970. Though slow, it did enable hundreds of researchers
at multiple locations to participate in an organized, ongoing, international
discussion group. It is not an exaggeration to say that it revolutionized
the way research is done.
online
conferencing system was called Delphi (after the Greek oracle),
and it debuted in 1970. Though slow, it did enable hundreds of researchers
at multiple locations to participate in an organized, ongoing, international
discussion group. It is not an exaggeration to say that it revolutionized
the way research is done.
In 1976, AT&![]() T
Bell Labs added UUCP (UNIX-to-UNIX CoPy) to the
T
Bell Labs added UUCP (UNIX-to-UNIX CoPy) to the ![]() UNIX
V7 operating system. Tom Truscott and
UNIX
V7 operating system. Tom Truscott and ![]() Jim
Ellis of Duke University and Steve Bellovin at the
Jim
Ellis of Duke University and Steve Bellovin at the ![]() University
of North Carolina developed the first version of
University
of North Carolina developed the first version of ![]() Usenet,
the UNIX User Network, using UUCP and
Usenet,
the UNIX User Network, using UUCP and ![]() UNIX
shell scripts and connected the two sites in 1979.
UNIX
shell scripts and connected the two sites in 1979. ![]() Usenet
quickly became the
Usenet
quickly became the ![]() online
conferencing system of choice on the Net. In 1986, the
online
conferencing system of choice on the Net. In 1986, the ![]() Network
News Transfer Protocol (NNTP) was created to improve
Network
News Transfer Protocol (NNTP) was created to improve ![]() Usenet
news performance over
Usenet
news performance over ![]() TCP/IP
networks. Since then, it has grown to accommodate more than 2.5 million
people a month and is available to over ten million users at over 200,000
sites.
TCP/IP
networks. Since then, it has grown to accommodate more than 2.5 million
people a month and is available to over ten million users at over 200,000
sites.
Another important online conferencing system, BITNET (the "Because It's Time NETwork"), was started two years after Usenet at the City University of New York (CUNY). BITNET uses
Although
Usenet Newsgroups
There are over 10,000 active Usenet newsgroups, all of which are organized into hierarchies by subject matter The seven major categories are as follows:
There are also additional less-official groups that may not be carried by all
If you have a question about what a newsgroup is all about or what is appropriate to post, you can usually find a Frequently Asked Questions (FAQ) list that will give you the answer. Most of the
In some Usenet groups, it's more important to stay on topic than it is in others. For example, you really don't want the messages in a scientific research group to degenerate into flame wars over which personal computer is best. To make sure this doesn't happen, many of the more serious Usenet groups are moderated.
In a moderated group, all posted articles are first mailed to a human moderator who combs through the messages to make sure they're on topic. Appropriate messages are then posted for everyone to see, while inappropriate messages are deleted. The moderator may even e-mail
![]() Usenet
is not the
Usenet
is not the ![]() Internet
or even a part of the
Internet
or even a part of the ![]() Internet;
it may be thought of as operating in parallel to and in conjunction with
the Internet. While most
Internet;
it may be thought of as operating in parallel to and in conjunction with
the Internet. While most ![]() Internet
sites carry
Internet
sites carry ![]() Usenet
newsfeeds, there is no direct or official relationship between the two.
However, Usenet news has become such an important part of computer internetworking
that a
Usenet
newsfeeds, there is no direct or official relationship between the two.
However, Usenet news has become such an important part of computer internetworking
that a ![]() newsreader
is now built into many
newsreader
is now built into many ![]() Web
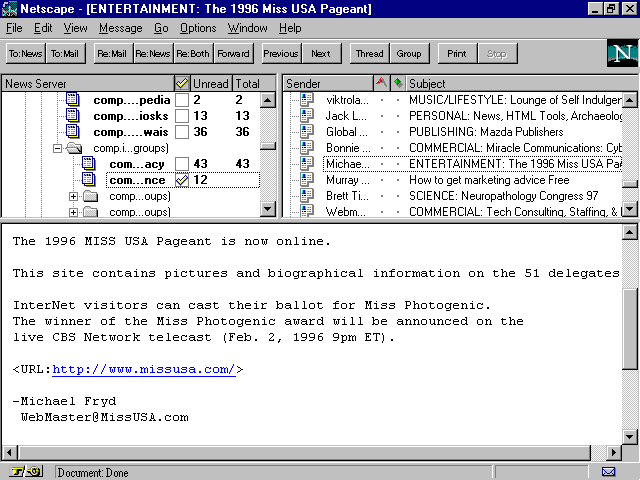
browsers (see fig. 1.3).
Web
browsers (see fig. 1.3).
Many browsers, such as Netscape 2.0, now incorporate an integral
![]() newsreader
for reading and posting to
newsreader
for reading and posting to ![]() Usenet
newsgroups.
Usenet
newsgroups.
The definitive
You can find ![]() Usenet
newsgroups of interest using the search form at http://www.cen.uiuc.edu/cgi-bin/find-news.
The Usenet Info Center Launch Pad at http://sunsite.unc.edu/usenet-i/
also offers a wealth of information on Usenet, including lists and indexes
of available Usenet discussion groups.
Usenet
newsgroups of interest using the search form at http://www.cen.uiuc.edu/cgi-bin/find-news.
The Usenet Info Center Launch Pad at http://sunsite.unc.edu/usenet-i/
also offers a wealth of information on Usenet, including lists and indexes
of available Usenet discussion groups.
By the mid-1970s, many government agencies were on the ARPAnet, but each was running on a network developed by the lowest bidder for their specific project. For example, the Army's system was built by DEC, the Air Force's by IBM, and the Navy's by Unisys. All were capable networks, but all spoke different languages. What was clearly needed to make things work smoothly was a set of networking protocols that would tie together disparate networks and enable them to communicate with each other.
In 1974, ![]() Vint
Cerf and Bob Kahn published a paper titled "
Vint
Cerf and Bob Kahn published a paper titled "![]() A
Protocol for
A
Protocol for ![]() Packet
Network Internetworking" that detailed a design that would solve the
problem. In 1982, this solution was implemented as TCP/IP. TCP stands
for Transmission Control Protocol; IP is the abbreviation for Internet
Protocol. With the advent of TCP/IP, the word Internet-which
is a
Packet
Network Internetworking" that detailed a design that would solve the
problem. In 1982, this solution was implemented as TCP/IP. TCP stands
for Transmission Control Protocol; IP is the abbreviation for Internet
Protocol. With the advent of TCP/IP, the word Internet-which
is a ![]() portmanteau
word for interconnected networks-entered the language.
portmanteau
word for interconnected networks-entered the language.
The ![]() TCP
portion of the TCP/IP provides data
TCP
portion of the TCP/IP provides data ![]() transmission
verification between client and server: If data is lost or scrambled, TCP
triggers
transmission
verification between client and server: If data is lost or scrambled, TCP
triggers ![]() retransmission
until the errors are corrected.
retransmission
until the errors are corrected.
You've probably heard the term socket mentioned in conjunction with TCP/IP. A socket is a package of subroutines that provide access to TCP/IP protocols. For example, most Windows systems have a file called winsock.
The ![]() IP
portion of TCP/IP moves data packets from node to node. It decodes addresses
and routes data to designated destinations. The
IP
portion of TCP/IP moves data packets from node to node. It decodes addresses
and routes data to designated destinations. The ![]() Internet
Protocol (IP) is what creates the network of networks, or
Internet
Protocol (IP) is what creates the network of networks, or ![]() Internet,
by linking systems at different levels. It can be used by small computers
to communicate across a LAN (Local Area Network) in the same room or with
computer networks around the world. Individual computers connected via
a
Internet,
by linking systems at different levels. It can be used by small computers
to communicate across a LAN (Local Area Network) in the same room or with
computer networks around the world. Individual computers connected via
a ![]() LAN
(either Ethernet or token ring) can share the
LAN
(either Ethernet or token ring) can share the ![]() LAN
setup with both TCP/IP and other network protocols, such as Novell or Windows
for Workgroups. One computer on the
LAN
setup with both TCP/IP and other network protocols, such as Novell or Windows
for Workgroups. One computer on the ![]() LAN
then provides the
LAN
then provides the ![]() TCP/IP
connection to the outside world.
TCP/IP
connection to the outside world.
The ![]() Department
of Defense quickly declared the
Department
of Defense quickly declared the ![]() TCP/IP
suite as the standard protocol for internetworking
TCP/IP
suite as the standard protocol for internetworking ![]() military
computers. TCP/IP has been ported to most
military
computers. TCP/IP has been ported to most ![]() computer
systems, including
computer
systems, including ![]() personal
computers, and has become the new standard in internetworking. It is the
protocol set that provides the infrastructure for the
personal
computers, and has become the new standard in internetworking. It is the
protocol set that provides the infrastructure for the ![]() Internet
today.
Internet
today.
TCP/IP comprises over 100 different protocols. It includes services for remote logon, file transfers, and data indexing and retrieval, among others.
An excellent source of additional information on TCP/IP is the Introduction to
gopher://gopher-chem.ucdavis.edu/11/Index/Internet_aw/Intro_the_Internet/intro.to.ip/.
One of the driving forces behind the development of ARPAnet was the desire to afford researchers at various locations the ability to log on to remote computers and run programs. At the time, there were very few computers in existence and only a handful of powerful supercomputers (though the supercomputers of the early 1970s were nowhere near as powerful as the desktop machines of today).
Along with e-mail, remote ![]() logon
was one of the very first capabilities built into the ARPAnet.
logon
was one of the very first capabilities built into the ARPAnet.
Today, there is less reason for logging on to a remote system and running
programs there. Most major ![]() government
agencies, colleges, and research facilities have their own computers, each
of which is as powerful as the computers at other sites.
government
agencies, colleges, and research facilities have their own computers, each
of which is as powerful as the computers at other sites.
TCP/IP provides a remote ![]() logon
capability through the
logon
capability through the ![]() Telnet
protocol. Users generally log in to a
Telnet
protocol. Users generally log in to a ![]() UNIX
shell account on the remote system using a text-based or
UNIX
shell account on the remote system using a text-based or ![]() graphics-based
terminal program. With Telnet, the user can list and navigate through directories
on the remote system and run programs.
graphics-based
terminal program. With Telnet, the user can list and navigate through directories
on the remote system and run programs.
The most popular programs run on ![]() shell
accounts are probably
shell
accounts are probably ![]() e-mail
programs, such as PINE; Usenet news readers, such as nn or rn; and text
editors, such as vi or Emacs. Students are the most common users of Telnet
these days; professors, scientists, and administrators are more likely
to have a more direct means of access to powerful computers, such as an
X Windows terminal.
e-mail
programs, such as PINE; Usenet news readers, such as nn or rn; and text
editors, such as vi or Emacs. Students are the most common users of Telnet
these days; professors, scientists, and administrators are more likely
to have a more direct means of access to powerful computers, such as an
X Windows terminal.
Most ![]() Web
browsers don't include built-in
Web
browsers don't include built-in ![]() Telnet
capabilities.
Telnet
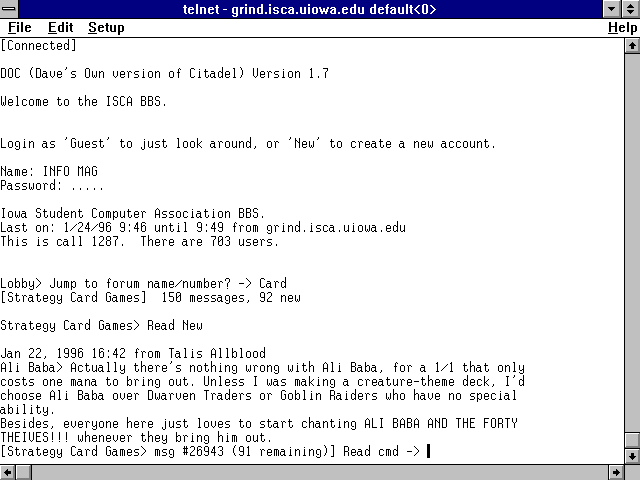
capabilities. ![]() Telnet
connections are usually established using a stand-alone
Telnet
connections are usually established using a stand-alone ![]() terminal
program, such as that shown in figure 1.4.
These programs can also be used by those who want Telnet capabilities on
the Web by configuring them as browser helper applications.
terminal
program, such as that shown in figure 1.4.
These programs can also be used by those who want Telnet capabilities on
the Web by configuring them as browser helper applications.
A ![]() Telnet
session can be initiated with an
Telnet
session can be initiated with an ![]() Internet
computer using a stand-alone
Internet
computer using a stand-alone ![]() terminal
program, such as QVTNET on Windows shown here.
terminal
program, such as QVTNET on Windows shown here.
An excellent
The ability to transfer data between computers is central to the internetworking
concept. TCP/IP implements ![]() computer-to-computer
data transfers thorough FTP (File Transfer Protocol).
computer-to-computer
data transfers thorough FTP (File Transfer Protocol).
An ![]() FTP
session involves first connecting to and signing on to an
FTP
session involves first connecting to and signing on to an ![]() FTP
server somewhere on the Net. Most
FTP
server somewhere on the Net. Most ![]() public
FTP sites allow anonymous
public
FTP sites allow anonymous ![]() FTP.
This means you can sign in with the user name anonymous and use
your e-mail address as your password. However, some sites are restricted
and require the use of an assigned user name and password.
FTP.
This means you can sign in with the user name anonymous and use
your e-mail address as your password. However, some sites are restricted
and require the use of an assigned user name and password.
Once in, you can list the files available on the site and move around through the directory structure just as though you were on your own system. When you've found a file of interest, you can transfer it to your computer using the get command (or mget for multiple files). You can also upload files to an FTP site using the put command.
The ![]() FTP
process was originally designed for text-only
FTP
process was originally designed for text-only ![]() UNIX
shell style systems. But today, there are many
UNIX
shell style systems. But today, there are many ![]() FTP
programs available that go way beyond the original
FTP
programs available that go way beyond the original ![]() FTP
capabilities, adding windows, menus, buttons, automated uploading and downloading,
site directories, and many more modern amenities.
FTP
capabilities, adding windows, menus, buttons, automated uploading and downloading,
site directories, and many more modern amenities.
One of the biggest lists of
Using ![]() Anonymous
FTP to obtain
Anonymous
FTP to obtain ![]() freeware
and
freeware
and ![]() shareware
programs,
shareware
programs, ![]() electronic
texts, and
electronic
texts, and ![]() multimedia
files remains one of the most popular activities on the Internet-so much
so that
multimedia
files remains one of the most popular activities on the Internet-so much
so that ![]() FTP
capabilities are now built into most
FTP
capabilities are now built into most ![]() Web
browsers (see fig. 1.5).
Web
browsers (see fig. 1.5).
![]() Web
browsers, such as Netscape 2.0, generally handle anonymous
Web
browsers, such as Netscape 2.0, generally handle anonymous ![]() FTP
too, automatically creating an on-screen directory file with icons and
clickable links.
FTP
too, automatically creating an on-screen directory file with icons and
clickable links.
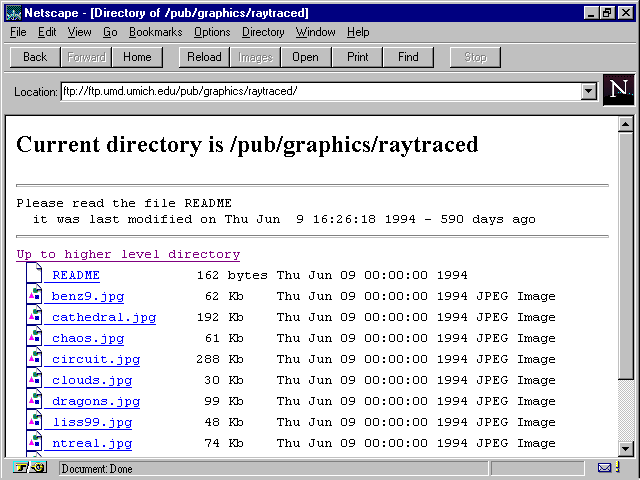
When accessing an FTP site using a Web browser, the URL will be preceded by
Individual files on an ![]() FTP
site are handled according to the way they are defined in your browser's
configuration setup, just as though you were browsing a Web site. For example,
if you're exploring an
FTP
site are handled according to the way they are defined in your browser's
configuration setup, just as though you were browsing a Web site. For example,
if you're exploring an ![]() FTP
site and click the link for a .gif picture file, it will be displayed in
the browser window. Text files and
FTP
site and click the link for a .gif picture file, it will be displayed in
the browser window. Text files and ![]() HTML
encoded files will be displayed too. If you have configured helper applicationsfor sound or video, clicking these types of files will display them using
the configured helper applications. Clicking an unconfigured file type
will generally bring up a
HTML
encoded files will be displayed too. If you have configured helper applicationsfor sound or video, clicking these types of files will display them using
the configured helper applications. Clicking an unconfigured file type
will generally bring up a ![]() requester
asking you to configure a viewer or save the file to disk.
requester
asking you to configure a viewer or save the file to disk.
Since you most often want to save files to disk from an FTP site, not view them, you can generally get around all this by using the browser's interactive option to save a file rather than display it. For example, in Netscape you can choose to save a file rather than view it by simply holding down the Shift key before clicking the file's link.
You might wonder, with hundreds of FTP sites on the Net and millions
of files stored at those sites, how in the world can you ever hope to find
the file you're looking for? Archie is the answer. Archie is a program
for finding files stored on any anonymous ![]() FTP
site on the
FTP
site on the ![]() Internet.
The Archie Usage Guide at http://info.rutgers.edu/Computing/Network/Internet/Guide/archie.html
provides an excellent overview of Archie, including instructions on how
to find and hook up to Archie servers on the Net.
Internet.
The Archie Usage Guide at http://info.rutgers.edu/Computing/Network/Internet/Guide/archie.html
provides an excellent overview of Archie, including instructions on how
to find and hook up to Archie servers on the Net.
The complete list of
http://www.cis.ohio-state.edu/hypertext/faq/usenet/ftp-list/faq/faq.html.
Along with e-mail, remote logon, and file transfer, information indexing and retrieval was one of the original big four concepts behind the idea of internetworking.
Though there were a plethora of different data indexing and retrieval
experiments in the early days of the Net, none was ubiquitous until, in
1991, Paul Lindner and Mark P. McCahill at the ![]() University
of Minnesota created
University
of Minnesota created ![]() Gopher.
Though it suffered from an overly cute (but highly descriptive) name, its
technique for organizing files under an intuitive menuing system won it
instant acceptance on the Net.
Gopher.
Though it suffered from an overly cute (but highly descriptive) name, its
technique for organizing files under an intuitive menuing system won it
instant acceptance on the Net.
![]() Gopher
treats all data as a menu, a document, an index, or a Telnet connection.
Through Telnet, one
Gopher
treats all data as a menu, a document, an index, or a Telnet connection.
Through Telnet, one ![]() Gopher
site can access others, making it a true internetwork application capable
of delivering data to a user from a multitude of sites via a single interface.
Gopher
site can access others, making it a true internetwork application capable
of delivering data to a user from a multitude of sites via a single interface.
The direct precursor in both concept and function to the ![]() World
Wide Web,
World
Wide Web, ![]() Gopher
lacks
Gopher
lacks ![]() hypertext
links or
hypertext
links or ![]() graphic
elements. Its function on the Net is being taken over by the Web, though
there are currently still several thousand Gopher sites on the Net, and
it will probably be years before Gopher disappears completely. Because
so much information is still contained in Gopher databases, the ability
to navigate and view Gopherspace is now built into most
graphic
elements. Its function on the Net is being taken over by the Web, though
there are currently still several thousand Gopher sites on the Net, and
it will probably be years before Gopher disappears completely. Because
so much information is still contained in Gopher databases, the ability
to navigate and view Gopherspace is now built into most ![]() Web
browsers (see fig. 1.6).
Web
browsers (see fig. 1.6).
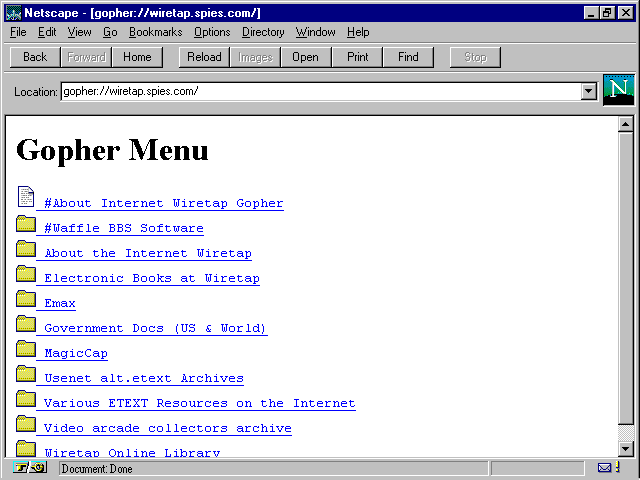
![]() Gopher
sites like this one are displayed just fine by most
Gopher
sites like this one are displayed just fine by most ![]() Web
browsers.
Web
browsers.
When accessing a Gopher site using a Web browser, the URL will be preceded by
As Archie is to FTP, Veronica is to Gopher. That is, if you want to know where something is on any Gopher site on the Net, the Veronica program can tell you. For a connection to Veronica via the Web, go to http://www.scs.unr.edu/veronica.html.
Although I'm slightly embarrassed to do so, I know that I must pass along to you the information that Veronica is actually an acronym, though it is almost never capitalized as one should be. What does it stand for? Would you believe Very Easy Rodent Oriented Net-wide Index to Computerized Archives?
The
For more about Gopher, consult the Gopher FAQ at http://www.cis.ohio-state.edu/hypertext/faq/usenet/gopher-faq/faq.html.
With the near-universal changeover to TCP/IP protocols in the years
following 1982, the word ![]() Internet
became the common term for referring to the worldwide network of research,
military, and
Internet
became the common term for referring to the worldwide network of research,
military, and ![]() university
computers.
university
computers.
In 1983, ARPAnet was divided into ARPAnet and MILNET. MILNET was soon
integrated into the Defense Data Network, which had been created in 1982.
ARPAnet's role as the network backbone was taken over by NSFNET (the National
Science Foundation NETwork), which had been created in 1986 with the aid
of ![]() NASA
and the
NASA
and the ![]() Department
of Energy to provide an improved backbone speed of 56Kbps for interconnecting
a new
Department
of Energy to provide an improved backbone speed of 56Kbps for interconnecting
a new ![]() generation
of research supercomputers. Connections proliferated, especially to colleges,
when in 1989 NSFNET was overhauled for faster T1 line connectivity by
generation
of research supercomputers. Connections proliferated, especially to colleges,
when in 1989 NSFNET was overhauled for faster T1 line connectivity by ![]() IBM,
Merit, and
IBM,
Merit, and ![]() MCI.
ARPAnet was finally retired in 1990.
MCI.
ARPAnet was finally retired in 1990.
In 1993, InterNIC (the Internet Network Information Center) was created
by the National Science Foundation to provide information, a directory
and database, and registration services to the Internet community. InterNIC
is, thus, the closest thing there is to an ![]() Internet
administrative center. However, InterNIC doesn't dictate
Internet
administrative center. However, InterNIC doesn't dictate ![]() Internet
policy or run some huge central computer that controls the
Internet
policy or run some huge central computer that controls the ![]() Net.
Its sole purpose is to handle organizational and "bookkeeping"
functions, such as assigning Internet addresses (see the sidebar, "Domain
Names").
Net.
Its sole purpose is to handle organizational and "bookkeeping"
functions, such as assigning Internet addresses (see the sidebar, "Domain
Names").
Computers on the
However, because addresses composed of nothing but numbers are difficult for humans to remember, in 1983 the University of Wisconsin developed the Domain Name Server (DNS), which was then introduced to the Net during the following year. DNS automatically and invisibly translates names composed of real words into their
There is no formula for calculating an IP address from a
The leftmost portion of a
The
Other (generally two-letter) extensions indicate a site's country of origin, such as .ca for Canada, .de for Germany, or .fr for France.
The topic of
Your organization can get an IP address assigned by sending ![]() electronic
mail to Hostmaster@INTERNIC.NET.
This service used to be free, but there is now a reasonable charge because
of the tremendous growth of the Internet and the privatization of the process.
For more information, point your browser to InterNIC's Web site at http://rs.internic.net/rs-internic.html.
electronic
mail to Hostmaster@INTERNIC.NET.
This service used to be free, but there is now a reasonable charge because
of the tremendous growth of the Internet and the privatization of the process.
For more information, point your browser to InterNIC's Web site at http://rs.internic.net/rs-internic.html.
One of the best
By 1990, the ![]() European
High-Energy Particle Physics Lab (CERN) had become the largest
European
High-Energy Particle Physics Lab (CERN) had become the largest ![]() Internet
site in Europe and was the driving force in getting the rest of Europe
connected to the Net. To help promote and facilitate the concept of distributed
computing via the
Internet
site in Europe and was the driving force in getting the rest of Europe
connected to the Net. To help promote and facilitate the concept of distributed
computing via the ![]() Internet,
Tim Berners-Lee created the
Internet,
Tim Berners-Lee created the ![]() World
Wide Web in 1992.
World
Wide Web in 1992.
The Web was an extension of the ![]() Gopher
idea, but with many, many improvements. Inspired by Ted Nelson's work on
Xanadu and the hypertext concept, the
Gopher
idea, but with many, many improvements. Inspired by Ted Nelson's work on
Xanadu and the hypertext concept, the ![]() World
Wide Web incorporated
World
Wide Web incorporated ![]() graphics,
typographic text styles, and-most importantly-hypertext links.
graphics,
typographic text styles, and-most importantly-hypertext links.
The
In a nutshell,
The hypertext concept has since been expanded to incorporate the idea of hypermedia, in which links can also be added to and from
The Web uses three new technologies: ![]() HTML,
or
HTML,
or ![]() HyperText
Markup Language, is used to write
HyperText
Markup Language, is used to write ![]() Web
pages; a
Web
pages; a ![]() Web
server computer uses HTTP (HyperText Transfer Protocol) to transmit those
pages; and a
Web
server computer uses HTTP (HyperText Transfer Protocol) to transmit those
pages; and a ![]() Web
browser client program receives the data, interprets it, and displays the
results.
Web
browser client program receives the data, interprets it, and displays the
results.
Using ![]() HTML,
almost anyone with a text editor and an
HTML,
almost anyone with a text editor and an ![]() Internet
site can build visually interesting pages that organize and present information
in a way seldom seen in other
Internet
site can build visually interesting pages that organize and present information
in a way seldom seen in other ![]() online
venues. In fact,
online
venues. In fact, ![]() Web
sites are said to be composed of pages because the information on
them looks more like magazine pages than traditional computer screens.
Web
sites are said to be composed of pages because the information on
them looks more like magazine pages than traditional computer screens.
HTML is a markup language, which means that ![]() Web
pages can only be viewed by using a specialized
Web
pages can only be viewed by using a specialized ![]() Internet
terminal program called a
Internet
terminal program called a ![]() Web
browser. In the beginning, the potential was there for the typical
computing "chicken and the egg problem": no one would create
Web
browser. In the beginning, the potential was there for the typical
computing "chicken and the egg problem": no one would create
![]() Web
pages because no one owned a browser program to view them with, and no
one would get a browser program because there were no Web pages to view.
Web
pages because no one owned a browser program to view them with, and no
one would get a browser program because there were no Web pages to view.
Fortunately, this did not happen because shortly after the Web was invented,
a killer browser program was released to the ![]() Internet
community-free of charge!
Internet
community-free of charge!
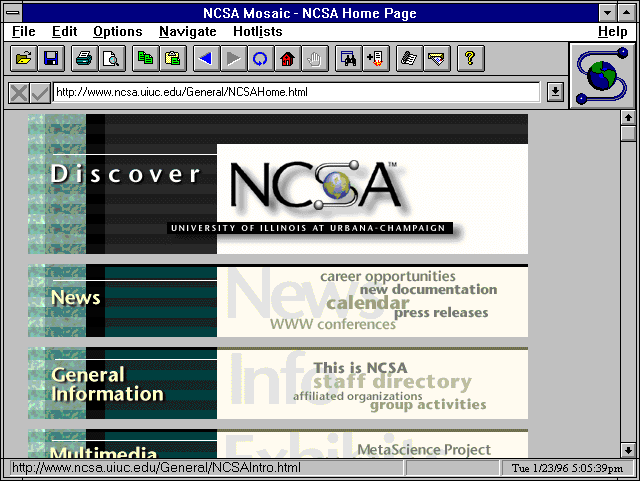
In 1993, the National Center for Supercomputing Applications (NCSA)
at the University of Illinois at Champaign-Urbana released Mosaic, a ![]() Web
browser designed by Marc Andreessen and developed by a team of students
and staff at the
Web
browser designed by Marc Andreessen and developed by a team of students
and staff at the ![]() University
of Illinois (see fig. 1.7). It spread like
wildfire though the Internet community; within a year, an estimated two
million users were on the Web with Mosaic. Suddenly, everyone was browsing
the Web, and everyone else was creating Web pages. Nothing in the
University
of Illinois (see fig. 1.7). It spread like
wildfire though the Internet community; within a year, an estimated two
million users were on the Web with Mosaic. Suddenly, everyone was browsing
the Web, and everyone else was creating Web pages. Nothing in the ![]() history
of computing had grown so fast.
history
of computing had grown so fast.
![]() NSCA
Mosaic, the browser that drove the phenomenal growth of the World Wide
Web, is still available free of charge for Windows,
NSCA
Mosaic, the browser that drove the phenomenal growth of the World Wide
Web, is still available free of charge for Windows, ![]() Windows
NT,
Windows
NT, ![]() Windows
95,
Windows
95, ![]() UNIX,
and
UNIX,
and ![]() Macintosh.
Macintosh.
By mid-1993, there were 130 sites on the World Wide Web. Six months later, there were over 600. Today, there are almost 100,000 Web sites in the world (some sources say there may be twice that many). For the first few months of its existence, the Web was doubling in size every three months. Even now, its doubling rate is (depending on whom you believe) less than five months. Table 1.1 shows just how quickly the Web has grown over its three-year history.
Table 1.1 Growth of the World Wide Web
| Date | Web Sites |
|---|---|
| 6/93 | 130 |
| 12/93 | 623 |
| 6/94 | 2,738 |
| 12/94 | 10,022 |
| 6/95 | 23,500 |
| 1/96 | 90,000 |
Source: "Measuring the Growth of the Web," Copyright 1995, Matthew Gray, http://www.netgen.com.
For more information on NCSA Mosaic, check out the NCSA Web site at http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/.
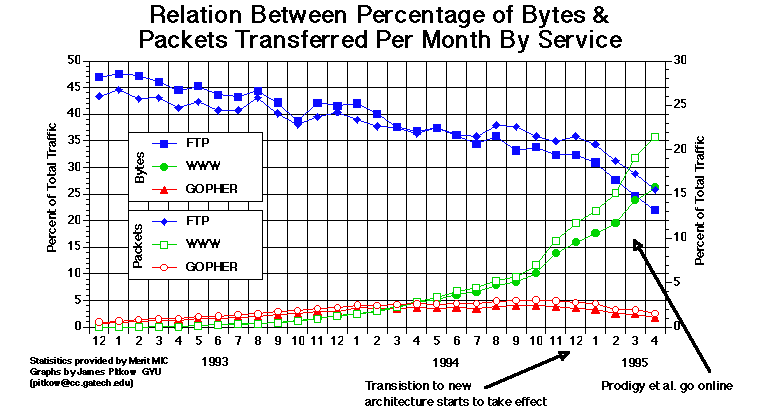
If the number of ![]() Web
sites were to keep doubling at the current rate, there would be over 300
Web sites in the world for every man, woman, and child by the end of 1998.
Clearly, this will not happen, but it does serve to illustrate just howfast the Web is expanding! See figure 1.8
for a graphical perspective.
Web
sites were to keep doubling at the current rate, there would be over 300
Web sites in the world for every man, woman, and child by the end of 1998.
Clearly, this will not happen, but it does serve to illustrate just howfast the Web is expanding! See figure 1.8
for a graphical perspective.
The ![]() Internet
is growing at a phenomenal rate as a whole, but the Web is growing so much
faster that it almost seems destined to take over the whole Net.
Internet
is growing at a phenomenal rate as a whole, but the Web is growing so much
faster that it almost seems destined to take over the whole Net.
For a wealth of both more and less accurate demographic information on the growth of the Internet in general and the World Wide Web in specific, begin with Yahoo!'s list of sites at http://www.yahoo.com/ Computers_and_Internet/Internet/Statistics_and_Demographics/. One good site to try is the
Mosaic's success-and the fact that its source code was distributed for
free!-spawned a wave of new browser introductions. Each topped the previous
by adding new HTML commands and features. Marc Andreessen moved on from
NCSA and joined with ![]() Jim
Clark of Silicon Graphics to found
Jim
Clark of Silicon Graphics to found ![]() Netscape
Communications Corporation. They took along most of the NCSA Mosaic development
team, which quickly turned out the first version of Netscape Navigator
for Windows, Macintosh, and UNIX platforms. Because of its many new features
and free trail preview offer, Netscape (as it is usually called) quickly
became the most popular browser on the Web. The Web's incredible growth
even attracted Microsoft's attention, and in 1995, they introduced their
Internet Explorer Web browser to coincide with the launch of their new
WWW service, the Microsoft Network (MSN).
Netscape
Communications Corporation. They took along most of the NCSA Mosaic development
team, which quickly turned out the first version of Netscape Navigator
for Windows, Macintosh, and UNIX platforms. Because of its many new features
and free trail preview offer, Netscape (as it is usually called) quickly
became the most popular browser on the Web. The Web's incredible growth
even attracted Microsoft's attention, and in 1995, they introduced their
Internet Explorer Web browser to coincide with the launch of their new
WWW service, the Microsoft Network (MSN).
See "How
Web Browsers and Servers Work Together"
See "Netscape-Specific
Extensions to HTML"
See "Additional
HTML Extensions Supported by Other Browsers"
Established ![]() online
services like
online
services like ![]() CompuServe,
CompuServe,
![]() America
Online, and Prodigy scrambled to meet their users' demands to add
America
Online, and Prodigy scrambled to meet their users' demands to add ![]() Web
access to their systems. Most of them quickly developed their own version
of Mosaic, customized to work in conjunction with their proprietary online
services. This enabled millions of established commercial service subscribers
to spill over onto the Web virtually overnight; "old-timers"
who had been on the Web since its beginning (only a year and a half or
so before) suddenly found themselves overtaken by a tidal wave of Web-surfing
newbies. Even
Web
access to their systems. Most of them quickly developed their own version
of Mosaic, customized to work in conjunction with their proprietary online
services. This enabled millions of established commercial service subscribers
to spill over onto the Web virtually overnight; "old-timers"
who had been on the Web since its beginning (only a year and a half or
so before) suddenly found themselves overtaken by a tidal wave of Web-surfing
newbies. Even ![]() television
discovered the Web, and it seemed that every other
television
discovered the Web, and it seemed that every other ![]() news
report featured a story about surfing the Net.
news
report featured a story about surfing the Net.
"All that growth is impressive," you say, "but... what just what exactly is the Web good for?" Good question, and one with hundreds of good answers.
People are on the Web to conduct business, to exchange information, to express their creativity, to collaborate, and to just plain have fun.
Some of the survey information used in this section is ![]() Copyright
(c)1995 CommerceNet Consortium/Nielsen Media Research.
Copyright
(c)1995 CommerceNet Consortium/Nielsen Media Research.
Today, there are over 37 million adults in North America with access
to the Internet. 24 million of them actually use their access, and 18 million
use their ![]() Internet
access time to browse the
Internet
access time to browse the ![]() World
Wide Web. The total amount of time spent cruising the Web is greater than
the time spent using all other
World
Wide Web. The total amount of time spent cruising the Web is greater than
the time spent using all other ![]() Internet
services combined, and is roughly equivalent to the time
Internet
services combined, and is roughly equivalent to the time ![]() North
Americans spend watching
North
Americans spend watching ![]() rented
videotapes.
rented
videotapes.
The number of people using the ![]() Internet
is increasing so rapidly that if the growth rate were to continue at the
current rate, by 2003 every person in the world would be on the Web!
Internet
is increasing so rapidly that if the growth rate were to continue at the
current rate, by 2003 every person in the world would be on the Web!
Increasingly, people are using the Web to conduct business. Today, over 50 percent of the sites on the Web are commercial (with a .com domain name). Over half of the users of the Web look for products at least occasionally and-since Web users are predominantly upscale, well educated, and affluent-business is paying attention. Expect Web growth in the near future to continue to be driven and driven hard by business expansion into cyberspace.
But Web surfers also use the Net for more traditional ![]() telecommunications
purposes. Three-fourths browse the Web. Two-thirds exchange e-mail. One
third download software by FTP. One in three takes part in discussion groups,
and one in five is active in multimedia.
telecommunications
purposes. Three-fourths browse the Web. Two-thirds exchange e-mail. One
third download software by FTP. One in three takes part in discussion groups,
and one in five is active in multimedia.
The ![]() World
Wide Web didn't get its name by accident. It truly is a web that encompasses
just about every topic in the world. A quick look at the premier topic
index on the Web, Yahoo! (http://www.yahoo.com,),
lists topics as diverse as art, world news, sports, business, libraries,
classified advertising, education, TV, science, fitness, and politics (see
fig. 1.9). You can't get much more diverse than that! There are literally
thousands of sites listed on Yahoo! under each of these topics and many
more.
World
Wide Web didn't get its name by accident. It truly is a web that encompasses
just about every topic in the world. A quick look at the premier topic
index on the Web, Yahoo! (http://www.yahoo.com,),
lists topics as diverse as art, world news, sports, business, libraries,
classified advertising, education, TV, science, fitness, and politics (see
fig. 1.9). You can't get much more diverse than that! There are literally
thousands of sites listed on Yahoo! under each of these topics and many
more.
If you really want to know what's on the Web, you need look no further than Yahoo!
But mere mass isn't the main draw of the Web. It's the way in which
all that information is presented. The best ![]() Web
sites integrate
Web
sites integrate ![]() graphics,
graphics,
![]() hypertext
links, and even video and audio. They make finding information interesting,
fun, and intuitive.
hypertext
links, and even video and audio. They make finding information interesting,
fun, and intuitive.
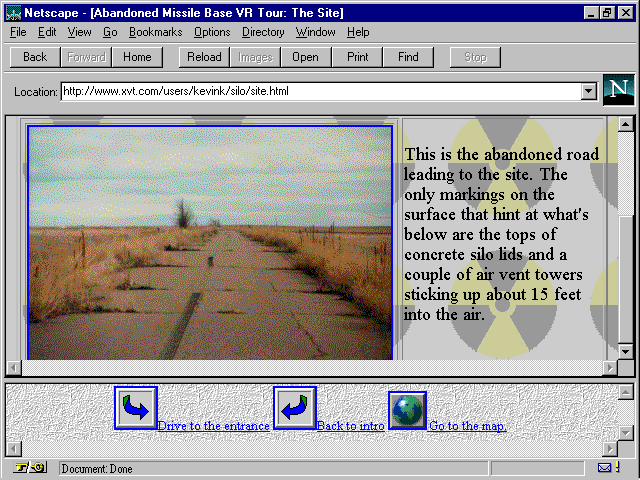
Marshall McLuhan asserted that the medium is the message, and this is
certainly true with the Web. Because its hypermedia presentation style
can overwhelm its content if done poorly, the Web is a real challenge to
developers. But when done well, the results are fantastic, such as the
tour of an abandoned ![]() US
missile silo shown in figure 1.10 (http://www.xvt.com/users/kevink/silo/site.html).
US
missile silo shown in figure 1.10 (http://www.xvt.com/users/kevink/silo/site.html).
For more information about the World Wide Web, consult the WWW FAQ at http://sunsite.unc.edu/boutell/index.html.
Fig. 1.10
A really cool ![]() Web
site integrates user interface and content seamlessly.
Web
site integrates user interface and content seamlessly.
See "Distributing Information on the Web"
Now that you know where the Web came from, it's time to jump into the whole melange feet first-but with your eyes open. HTML (HyperText Markup Language) is what you use to create Web pages, and it's the topic of this book.
![]() HTML
is relatively simple in both concept and execution. In fact, if you have
ever used a very old word processor, you are already familiar with the
concept of a markup language.
HTML
is relatively simple in both concept and execution. In fact, if you have
ever used a very old word processor, you are already familiar with the
concept of a markup language.
In the "good old days" of word processing, if you wanted text to appear in, say, italics, you might surround it with control characters like this:
/Ithis is in italics/I
The "/I" at the beginning would indicate to the word processor
that, when printed, the text following should be italicized. The "/I"
would turn off italics so that any text afterward would be printed in a
normal ![]() font.
You literally marked up the text for printing just as you would
if you were making editing marks on a printed copy with an editor's red
pencil.
font.
You literally marked up the text for printing just as you would
if you were making editing marks on a printed copy with an editor's red
pencil.
HTML works in much the same way. If, for example, you want text to appear on a Web page in italics, you mark it like this:
<I>this is in italics</I>
Almost everything you create in HTML relies on marks, or tags, like these.
See "How Web Browsers and Servers Work Together"
The rest of this book elaborates on that simple fact.
Although you don't need to know every term that's bantered about on the Internet to be able to work, play, and develop on the Web, an understanding of a few key terms will help you to better understand what's going on there. Here's a short glossary of Internet and Web terms to help you get started.
For more on computer terminology, check out the Free Online Dictionary of Computing at http://wfn-shop.princeton.edu/cgi-bin/foldoc. If computer abbreviations and acronyms have you confused, seek enlightenment at BABEL, a dictionary of such alphabet soup at http://www.access.digex.net/~ikind/babel96a.html. But if you want become a real Net insider, you'll have to learn the slang; for that, check out the latest version of the legendary Jargon File at http://www.ccil.org/jargon/jargon.html.


Internet & New Technologies Home Page - Que Home Page
For technical support for our books and software contact support@mcp.com
© 1996, Que Corporation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}