Notice: This material is excerpted from Special Edition Using HTML, 2nd Edition, ISBN: 0-7897-0758-6. This material has not yet been through the final proof reading stage that it will pass through before being published in printed form. Some errors may exist here that will be corrected before the book is published. This material is provided "as is" without any warranty of any kind.
by Bill Brandon
You may remember the popular line from the movie Field of Dreams: "If
you build it, they will come." Everyone who creates a page or a site
for the Web would like to communicate a message, attract attention and
traffic, perhaps even win acclaim. Otherwise, there's no purpose in the
effort. But you probably found out in your first few hours on the Web that
not all pages are worthy of much attention, let alone acclaim. ![]() Building
a great Web page takes a lot of time, attention to detail, and knowledge
of your readers.
Building
a great Web page takes a lot of time, attention to detail, and knowledge
of your readers.
Four elements separate outstanding ![]() Web
pages from the other 95 percent. First, great Web pages are always mechanically
sound: the HTML is written correctly, the text and
Web
pages from the other 95 percent. First, great Web pages are always mechanically
sound: the HTML is written correctly, the text and ![]() graphics
display correctly, and the links all work. Second, an outstanding page
is aesthetically pleasing; having a pleasant appearance is different from
being cool and flashy. Third, a great page is built from the ground up
to provide value to the viewers. Finally, a great
graphics
display correctly, and the links all work. Second, an outstanding page
is aesthetically pleasing; having a pleasant appearance is different from
being cool and flashy. Third, a great page is built from the ground up
to provide value to the viewers. Finally, a great ![]() Web
page adheres to certain standard practices. These practices create a practical
user interface and allow visitors to get the page to respond in predictable
ways.
Web
page adheres to certain standard practices. These practices create a practical
user interface and allow visitors to get the page to respond in predictable
ways.
In this chapter, you learn about the following:
How often have you managed to complete an entire document or program without making a single mistake? Even when I proofread and test carefully, at least one embarrassing error always seems to get past me. HTML documents are no different, except that even more things can go wrong.
Web page verification is the continuing task of making sure your HTML
source code is intelligible to browsers and provides the interface you
and the Web surfer expect. ![]() Web
page verification also addresses the
Web
page verification also addresses the ![]() maintenance
of those vital hypertext links to other pages, to images, and to files.
You can think of Web page verification as a combination Quality Assurance
function and continuous improvement program.
maintenance
of those vital hypertext links to other pages, to images, and to files.
You can think of Web page verification as a combination Quality Assurance
function and continuous improvement program.
Resources are available on the Web itself to check your ![]() HTML
syntax and test your links. Some of these resources run on other people's
servers. Anyone on the Web can use them. These resources can go by any
of several names, such as validators or validation services, but in this
chapter I refer to the entire group as verification services.
HTML
syntax and test your links. Some of these resources run on other people's
servers. Anyone on the Web can use them. These resources can go by any
of several names, such as validators or validation services, but in this
chapter I refer to the entire group as verification services.
Most of this chapter is concerned with demonstrating several of these
tools on the ![]() Web.
I will also show you where todownload a number of these tools. You can
then run them on your own server (if you have one) to perform the same
functions.
Web.
I will also show you where todownload a number of these tools. You can
then run them on your own server (if you have one) to perform the same
functions.
The tools you will see perform at least one of the two essential verification functions: they verify HTML source code, they verify links, or they do both.
![]() HTML
is written to be read by
HTML
is written to be read by ![]() Web
browsers, not by human beings. Although most Web browsers are pretty forgiving,
basic errors in
Web
browsers, not by human beings. Although most Web browsers are pretty forgiving,
basic errors in ![]() HTML
syntax prevent a page from being displayed properly. Other
HTML
syntax prevent a page from being displayed properly. Other ![]() HTML
errors cause people to have to wait longer than they like while a page
loads. Such failures can destroy the effectiveness of your Web site.
HTML
errors cause people to have to wait longer than they like while a page
loads. Such failures can destroy the effectiveness of your Web site.
Of course, you can use an SGML-aware editor such as HoTMetaL; it does syntax checking on the fly. Such a tool makes sure you use the correct tag for any given context.
But not everyone uses an SGML-aware editor. Many people use Notepad or WordPad to prepare their HTML documents. If you are using a less capableeditor, you can employ any of several verification services on the Web to check out your HTML source for errors. Such services vary in their capabilities, but they have one outstanding characteristic in common: they are free. In fact, even if you use an SGML-aware editor, you should verify your source code. Why? Change.
A fact of life on the World Wide Web is the speed with which it has
grown. In less than three years, the Web has acquired millions of users.
At the same time, the ![]() HTML
convention has gone through three standards. The browsers used to access
documents on the Web have undergone a similar explosive growth. An editor
that is up-to-date in its ability to parse and correct syntax today may
well be obsolescent in three months or less.
HTML
convention has gone through three standards. The browsers used to access
documents on the Web have undergone a similar explosive growth. An editor
that is up-to-date in its ability to parse and correct syntax today may
well be obsolescent in three months or less.
Some browsers now use non-standard tags (extensions) in documents to deliver special effects. You may have seen pages on the Web marked "This page appears best under Netscape" or "This page appears best with Internet Explorer." To say that this presents a challenge to Web page developers is an understatement.
See "Frames," and "Marquee Text," for examples of these extensions.
A developer can build a ![]() Web
page to conform to the
Web
page to conform to the ![]() HTML
3.0 Standard, for example. The page may look wonderful when viewed with
a Level 3.0 browser. But what does it look like when viewed with a Level
1.0 browser? There are also users who cruise the Web with text-only browsers
like
HTML
3.0 Standard, for example. The page may look wonderful when viewed with
a Level 3.0 browser. But what does it look like when viewed with a Level
1.0 browser? There are also users who cruise the Web with text-only browsers
like ![]() Lynx.
Millions of copies of browsers that conform to standards less capable than
Lynx.
Millions of copies of browsers that conform to standards less capable than
![]() HTML
3.0 are in use every day, all over the world. The developer wants all of
them to be able to get her message, buy her products, find her email address.
Meanwhile a growing percentage of the
HTML
3.0 are in use every day, all over the world. The developer wants all of
them to be able to get her message, buy her products, find her email address.
Meanwhile a growing percentage of the ![]() Web
population worldwide uses some version of Netscape. What will they see?
Web
population worldwide uses some version of Netscape. What will they see?
One solution to this problem is for every developer to obtain a copy of every browser and check out the page under each one. This solution seems a little extreme. The on-line verification services offer a much simpler answer. And the on-line services are constantly updated as well.
Later in this chapter, you will look in detail at the three leading on-line verification services: WebTechs, Weblint, and the Kinder-Gentler Validator. You'll also be introduced to the Chicago Computer Society's Suite of Validation Suites, which provides a convenient interface for all three of these services and much more. I'll show you four excellent alternative verification services, too. Finally, you'll learn where to obtain verification tools that you can install on your own server and get a look at what it takes to do this.
But simply checking the ![]() HTML
source ensures only that your documents appear the way you expect them
to appear on different browsers. You also need to make sure that all your
links work the way they are supposed to work.
HTML
source ensures only that your documents appear the way you expect them
to appear on different browsers. You also need to make sure that all your
links work the way they are supposed to work.
A browser tries to follow any link the user clicks. One possible source
of problems is a simple typographical error. Every page designer makes
these errors, and sometimes these errors happen while you're entering links.
An SGML-aware editor doesn't catch this problem, and chances are you won't
spot all of them either. Another source of trouble is the constant change
that the Web undergoes. A link to a valid site last week may not go to
anything next week. ![]() Web
pages require continuous maintenance and verification to guard against
these dead links.
Web
pages require continuous maintenance and verification to guard against
these dead links.
One way to check your links is to ask all your friends to test your document periodically. This idea is good in theory, but it's a fast way to lose your friends in practice. Luckily, some verification tools and services will test your links for you.
Checking links is part of routine maintenance. Most ![]() Web
browsers are very forgiving of errors in
Web
browsers are very forgiving of errors in ![]() HTML.
A broken link is not something that a browser can deal with, though. For
this reason, you should test on a regular basis.
HTML.
A broken link is not something that a browser can deal with, though. For
this reason, you should test on a regular basis.
In the section titled, "Using Doctor HTML", you will discover an excellent on-line resource for testing your links and fine-tuning page performance. Although the Doctor is not available for installation on local servers, other link testers are; they are listed in the section titled, "Obtaining and Installing Other Verification Suites." Finally, there is a service called URL-Minder that will notify you whenever there are changes to a page to which your page is linked. This is described in the section on "Using Other Verification Services on the Web."
You have a couple of ways that you can go to obtain regular verification of your pages. You can do the job yourself, or you can have someone else do it.
To do verification yourself, you install and run one or more tools on your server. These tools are CGI scripts, nearly always written in perl. Many are available from Web sites at no cost. You could also write your own CGI script.
Of course, you may not have a server of your own on which to install verification tools. In this case, you can use one of the many public tools available on the Web. This capability can be extremely convenient if you are developing pages at a client's site or in a hotel room while you're traveling.
Running verification on your own server is a good thing if you have
a lot of HTML source code and Web pages to maintain. Companies that have
an ![]() in-house
version of the Internet (often referred to as an "intra-net")
would find this an attractive option. In the sections titled, "Installing
the WebTechs HTML Check Toolkit Locally," and "Obtaining
and Installing Other Verification Suites," you'll learn exactly
what is required to set up this capability.
in-house
version of the Internet (often referred to as an "intra-net")
would find this an attractive option. In the sections titled, "Installing
the WebTechs HTML Check Toolkit Locally," and "Obtaining
and Installing Other Verification Suites," you'll learn exactly
what is required to set up this capability.
Most people, however, only occasionally need to verify any source code and have just a handful of links to maintain. In these cases, even if you have a server available you may want to take advantage of the services on the Web. But where and how do you find these services?
The first task is to find these on-line services. Fortunately, it's
easy to locate a handy list of validation checkers. Using the Yahoo search
engine (http://www.yahoo.com), search
on the key ![]() Validation
Checkers and choose the match with the label Computers and
Validation
Checkers and choose the match with the label Computers and ![]() Internet:Software:Data
Formats:HTML:Validation Checkers. Figure 19.1
gives you an idea of the results you get this way.
Internet:Software:Data
Formats:HTML:Validation Checkers. Figure 19.1
gives you an idea of the results you get this way.
Fig. 19.1
Yahoo maintains a list of validation checkers on the Web.
The other search engines available on the Web can also be used to locate
validation checkers. None of them provides the kind of precision the ![]() Yahoo
list does, however. You should try a variety of keywords, such as html,
URL, verification, and service, in addition to validation and checker.
Use various combinations. From time to time, new validation or
Yahoo
list does, however. You should try a variety of keywords, such as html,
URL, verification, and service, in addition to validation and checker.
Use various combinations. From time to time, new validation or ![]() verification
checkers will appear on the Web, and it is difficult to predict the keywords
it will take to find them.
verification
checkers will appear on the Web, and it is difficult to predict the keywords
it will take to find them.
Table 19.1 lists four of the most popular ![]() verification
services. Each of these will verify HTML source on the Web. Although all
four perform similar functions, they provide subtle differences in their
reports. All will be discussed in this chapter in the major sections. Other
verification services available on the Web will also be described, more
briefly, in the section titled, "Using Other Verification Services
on the Web."
verification
services. Each of these will verify HTML source on the Web. Although all
four perform similar functions, they provide subtle differences in their
reports. All will be discussed in this chapter in the major sections. Other
verification services available on the Web will also be described, more
briefly, in the section titled, "Using Other Verification Services
on the Web."
Table 19.1 Four popular verification services on the Web.
| Service Name | URL |
| WebTechs | http://www.webtechs.com/html-val-svc |
| Kinder-Gentler | http://ugweb.cs.ualberta.ca/~gerald/validate.cgi |
| Weblint | http://www.khoros.unm.edu/staff/neilb/weblint.html |
| Doctor HTML | http://imageware.com/RxHTML.cgi |
WebTechs was formerly HALSoft, and remains a standard for ![]() on-line
verification. The
on-line
verification. The ![]() WebTechs
tool checks
WebTechs
tool checks ![]() HTML.
It validates a single page or a list of pages submitted together, and it
lets you enter lines of your source directly. WebTechs is located at http://www.webtechs.com/html-val-svc.
HTML.
It validates a single page or a list of pages submitted together, and it
lets you enter lines of your source directly. WebTechs is located at http://www.webtechs.com/html-val-svc.
On some Web pages, you may have seen a yellow box like the one shown
here![]() . It indicates
that the HTML on the Web page has passed WebTechs validation tests. Although
getting this icon isn't exactly the same as winning an Oscar, it indicates
that the person who developed the page knows his or her stuff.
. It indicates
that the HTML on the Web page has passed WebTechs validation tests. Although
getting this icon isn't exactly the same as winning an Oscar, it indicates
that the person who developed the page knows his or her stuff.
When your page passes the test, the validation system itself gives you the graphic. It comes with some HTML code that makes the graphic link to the WebTechs site.
So how do you go about getting this bit of public recognition? The path starts with turning your Web browser to the appropriate site, as shown in table 19.2.
Table 19.2 WebTechs Validation Server sites.
| Location | URL |
| North America | http://www.webtechs.com/html-val-svc/ |
| EUnet Austria | http://www.austria.eu.net/html-val-svc/ |
| HENSA UK | http://www.hensa.ac.uk/html-val-svc/ |
| Australia | http://cq-pan.cqu.edu.au/validate/ |
After you enter the appropriate site and start the service, you see
a form similar to the one shown in figure 19.2.
On this form, you can have your ![]() Web
page (or bits of HTML) checked for conformance in a matter of seconds.
You instantly get a report that lays out any problems with the HTML source.
Web
page (or bits of HTML) checked for conformance in a matter of seconds.
You instantly get a report that lays out any problems with the HTML source.
WebTechs changes the appearance and layout of this form from time to time. In particular, the last radio button in the first row is quite likely to change. For a time, it was HotJava as shown here. It has since been changed to "SQ", for SoftQuad's HoTMeTaL Pro Extensions. In the future it will probably be used to specify other sets of HTML extensions as well. These changes do not affect the use of the form.
Fig. 19.2
Check your Web page using this WebTechs HTML Validation Service form.
Incidentally, if you have many pages to maintain, you can add some HTML to each page to save you time and work. The code in listing 19.1 adds a button labeled "Validate this URL" to your page. Whenever you update a page, all you have to do is click on the button instead of opening up the WebTechs URL. Table 19.3 gives the possible values for each of the variables.
Listing 19.1 - Add this HTML to provide a button that automatically submits your page for validation.
<FORM METHOD="POST" ACTION="http://www.webtechs.com/cgi-bin/html-check.pl"> <INPUT NAME="recommended" VALUE="0" TYPE="hidden"> <INPUT NAME="level" VALUE="2" TYPE="hidden"> <INPUT NAME="input" VALUE="0" TYPE="hidden"> <INPUT NAME="esis" VALUE="0" TYPE="hidden"> <INPUT NAME="render" VALUE="0" TYPE="hidden"> <INPUT NAME="URLs" VALUE="http://www.foo.com/goo.html" TYPE="hidden"> <INPUT NAME="submit" VALUE="Validate this URL"> </FORM>
Remember to replace "http://www.foo.com/goo.html" with the proper address for the page on which this button is placed!
![]() Table
19.3 Values for the variables used in setting up the
Table
19.3 Values for the variables used in setting up the ![]() Validate
this URL button.
Validate
this URL button.
| Variable | Meaning | Range of Settings |
| recommended | Type of checking | 0 = standard, 1 = strict |
| level | Level of DTD to use | 2, 3, or Mozilla |
| input | Echo HTML input | 0 = don't echo, 1 = echo |
| esis | Echo output of parser | 0 = don't echo, 1 = echo |
| render | Render HTML for preview | 0 = don't render, 1 = render |
| URLs | Full declaration of URL |
WebTechs refers to the
Netscape extensions as Mozilla. WebTechs does not specify a "level" variable for HotJava,
When you arrive at the WebTechs HTML Validation Service, you may want
to set some options. WebTechs lets you specify the level of conformance
for the test. That is, you can test a document for conformance to the HTML
2.0 Specification, the HTML 3.0 Specification, the Netscape Document Type
Definition (DTD), or some other DTD. The radio buttons marked ![]() Level
2,
Level
2, ![]() Level
3, and Mozilla, respectively, indicate these different specifications (see
Fig. 19.3.) As noted before, the identity and use of the fourth radio
button on this row changes from time to time. You can select only one radio
button at a time.
Level
3, and Mozilla, respectively, indicate these different specifications (see
Fig. 19.3.) As noted before, the identity and use of the fourth radio
button on this row changes from time to time. You can select only one radio
button at a time.
Fig. 19.3
Use the radio buttons to tell WebTechs what kind of HTML is in your source.
These radio buttons tell WebTechs which DTD to use in checking your page. Successful choice of DTD requires that you understand how WebTechs works, as I will explain in the next few paragraphs.
WebTechs is actually an SGML parser. As such, it requires a DOCTYPE
declaration in the first line of any document it checks; this declaration
tells it which DTD to use. However, ![]() Web
browsers aren't
Web
browsers aren't ![]() SGML
parsers and ignore a
SGML
parsers and ignore a ![]() DOCTYPE
declaration when they find one. As a result, most
DOCTYPE
declaration when they find one. As a result, most ![]() Web
documents do not include DOCTYPE. By selecting a radio button, you instruct
WebTechs to respond as though the corresponding DOCTYPE were at the beginning
of your page - if no DOCTYPE declaration is in the document when it opens.
Web
documents do not include DOCTYPE. By selecting a radio button, you instruct
WebTechs to respond as though the corresponding DOCTYPE were at the beginning
of your page - if no DOCTYPE declaration is in the document when it opens.
If WebTechs finds a DOCTYPE declaration in your source when opened, it uses that declaration and ignores the radio buttons. It will also ignore the check box, provide you with the correct options settings, and (if your source passes) it will provide you with the correct validation icon.
Perhaps you don't actually know the DOCTYPE declared in your document or the species of HTML contained in it. If you select an inappropriate button, you could get a list of errors relating to a standard you perhaps didn't think applied.
You should look at the first line of your HTML source to see what's there before you try to validate a page.
A more serious problem occurs when the DOCTYPE declaration in your document is not one that WebTechs recognizes. WebTechs can generate an enormous number of spurious errors. Be sure that your DOCTYPE declaration is correct, if you have one. The correct syntax for the declaration is
<!DOCTYPE HTML PUBLIC "quoted string">
The "quoted string" is the part that WebTechs must know. WebTechs lists the strings it recognizes in its public identifier catalog. Here are the four you are most likely to need:
"-//IETF//DTD HTML 2.0//EN" "-//IETF//DTD HTML 3.0//EN" "-//Netscape Comm. Corp.//DTDHTML//EN" "-//Sun Microsystems Corp.//DTD HotJava HTML//EN"
The WebTechs public identifier catalog is well hidden. You will find it at this URL: http://www.webtechs.com/html-tk/src/lib/catalog
These strings must appear just as they do here, including capitalization
and punctuation. The DOCTYPEs are not even necessarily the same as the
"official" ![]() public
identifiers for their respective DTDs.
public
identifiers for their respective DTDs.
Some popular
In the WebTechs HTML Service, a check box marked Strict appears at the beginning of the radio button row. You can use it to modify any of the radio button settings. The default is unchecked. When this item is checked, WebTechs uses a "strict" version of the DTD for the level (2.0, 3.0, Mozilla, or other choice) that you select.
In Strict mode, WebTechs accepts only recommended idioms in your ![]() HTML.
This restriction ensures that a document's structure is uncompromised.
In theory, all browsers should then display your document correctly. The
HTML.
This restriction ensures that a document's structure is uncompromised.
In theory, all browsers should then display your document correctly. The
![]() Strict
version of the DTD for each of the four specifications tries to tidy up
some parts of
Strict
version of the DTD for each of the four specifications tries to tidy up
some parts of ![]() HTML
that don't measure up to
HTML
that don't measure up to ![]() SGML
standards.
SGML
standards.
Unfortunately, some browsers still in common use were written when ![]() HTML
1.0 was in effect. Under this specification, the <P> tag separated
paragraphs. But now <P> is a container. Suppose that you write your
HTML to pass a Strict Level 2 test. You will find that an HTML 1.0-compliant
browser displays a line break between a list bullet and the text that should
follow it.
HTML
1.0 was in effect. Under this specification, the <P> tag separated
paragraphs. But now <P> is a container. Suppose that you write your
HTML to pass a Strict Level 2 test. You will find that an HTML 1.0-compliant
browser displays a line break between a list bullet and the text that should
follow it.
Don't use the Strict conformance to check your pages, and don't modify your pages to comply with Strict HTML unless you are sure of the browsers that users will employ to display your page.
WebTechs provides ![]() on-line
copies of the formal specifications and the DTDs for both
on-line
copies of the formal specifications and the DTDs for both ![]() HTML
versions and for Netscape and HotJava. You can find the strict DTDs here
as well. All the strict DTDs enforce four recommended idioms:
HTML
versions and for Netscape and HotJava. You can find the strict DTDs here
as well. All the strict DTDs enforce four recommended idioms:
Having no text outside paragraph elements means that all document text
must be part of a block container. Table 19.4 shows right and wrong according
to ![]() Strict
Mode. Please note that the source code on the left is different from that
on the right. The difference is subtle: on the left, the paragraph containers
are properly used while on the right, no paragraph containers are used
at all.
Strict
Mode. Please note that the source code on the left is different from that
on the right. The difference is subtle: on the left, the paragraph containers
are properly used while on the right, no paragraph containers are used
at all.
Table 19.4 The ways ![]() Strict
mode identifies valid paragraph text.
Strict
mode identifies valid paragraph text.
| Paragraphs Valid in Strict Mode | Paragraphs Not Valid in Strict Mode |
| <HTML> | <HTML> |
| <HEAD> | <HEAD> |
| <TITLE>Passes Strict Test</TITLE> | <TITLE>Fails Strict Test</TITLE> |
| </HEAD> | </HEAD> |
| <BODY> | <BODY> |
| <P>First Line</P> | First Line |
| <P>Veni, vidi, vici.</P> | Veni, vidi, vici. |
| <P>Last Line</P> | Last Line |
| </BODY> | </BODY> |
| </HTML> | </HTML> |
Why is this important? Browsers that are ![]() HTML
2.0 or 3.0 compliant will display both examples in
HTML
2.0 or 3.0 compliant will display both examples in ![]() Table
19.4. In the case on the left, each paragraph
Table
19.4. In the case on the left, each paragraph ![]() container
of text will be shown on a separate line on the screen, with one line space
before and after the text. In the case on the right, all the text will
be shown on a single line.
container
of text will be shown on a separate line on the screen, with one line space
before and after the text. In the case on the right, all the text will
be shown on a single line.
In addition, both examples will pass a simple ![]() HTML
2.0 or 3.0 validation by WebTechs. Only the one on the left will pass a
Strict Mode validation, however.
HTML
2.0 or 3.0 validation by WebTechs. Only the one on the left will pass a
Strict Mode validation, however.
It might seem desireable to always use the Strict Mode, to ensure that
browsers will always correctly interpret your source code and display your
page the way you intended. However, as noted before, the ![]() container
elements required to pass
container
elements required to pass ![]() Strict
Mode may cause
Strict
Mode may cause ![]() HTML
1.0 compliant browsers and text browsers to display your page in ways that
you never anticipated.
HTML
1.0 compliant browsers and text browsers to display your page in ways that
you never anticipated.
Even if you know that your page will not be accessed by any HTML 1.0
compliant browsers, you may still not want to use Strict Mode for checking.
Table 19.5 shows the ![]() container
elements for
container
elements for ![]() Strict
HTML 2.0 and additional elements for
Strict
HTML 2.0 and additional elements for ![]() Strict
HTML 3.0. WebTechs rejects any others when the Strict level of conformance
is chosen. If you are using extensions that provide container elements
other than these, your source code may not pass a Strict test. This does
not mean the code won't be readable to browsers, it just means it didn't
pass the test. You will then spend time, maybe a lot or maybe a little,
checking the error report from WebTechs line by line looking for the guilty
party--without success.
Strict
HTML 3.0. WebTechs rejects any others when the Strict level of conformance
is chosen. If you are using extensions that provide container elements
other than these, your source code may not pass a Strict test. This does
not mean the code won't be readable to browsers, it just means it didn't
pass the test. You will then spend time, maybe a lot or maybe a little,
checking the error report from WebTechs line by line looking for the guilty
party--without success.
Table 19.5 Container elements under strict HTML rules.
| Valid under Strict HTML 2.0 | ...Add These Elements for Strict HTML 3.0 |
| <P>|<BLOCKQUOTE>|<PRE> | <TABLE> |
| <DL>|<UL>|<OL> | <FIG> |
| <FORM> | <NOTE> |
| <ISINDEX> | <BQ> |
What rule of thumb should you draw from all this? Just one: When deciding whether to test with Strict Mode selected, be guided by the KISS Principle(Keep It Simple, Simon).
After you have set the level of conformance that you want to establish for your source code, WebTechs gives you some options about the report contents, as shown in figure 19.4.
Fig. 19.4
The report options determine what you see in the report from WebTechs.
The basic report that WebTechs sends to you will be either a message that says Check Complete. No errors found or an actual list of the errors found. The errors, of course, reflect the Level of Conformance you chose in the first row of check boxes. Under some circumstances, you can get an erroneous No errors found message. The options you select for the report can help you spot these errors and help you make sense out of the error listing.
The error listing that WebTechs returns refers to error locations by
using line numbers. If you check the box by Show Input, your ![]() HTML
source follows the error list, with line numbers added. This report can
be very helpful.
HTML
source follows the error list, with line numbers added. This report can
be very helpful.
You can get additional help in interpreting the error listing by selecting Show Parser Output. This option appends a detailed list of the way WebTechs parsed your source.
Finally, by selecting ![]() Show
Formatted Output, you can have WebTechs append what it tested, formatted
according to the DTD you chose. This report is useful in case you enter
a URL incorrectly. If you do, WebTechs gets an error message when it tries
to connect to that URL. WebTechs handles some of these messages well, but
not all of them. In particular, if a typo causes an Error 302 ("Document
moved") message to be returned, WebTechs parses the error message
and returns the report
Show
Formatted Output, you can have WebTechs append what it tested, formatted
according to the DTD you chose. This report is useful in case you enter
a URL incorrectly. If you do, WebTechs gets an error message when it tries
to connect to that URL. WebTechs handles some of these messages well, but
not all of them. In particular, if a typo causes an Error 302 ("Document
moved") message to be returned, WebTechs parses the error message
and returns the report ![]() Check
Complete. No errors found. If you checked Show Formatted Output, you see
the actual Error message in addition to the incorrect report and therefore
avoid being tricked into thinking it was your page being validated.
Check
Complete. No errors found. If you checked Show Formatted Output, you see
the actual Error message in addition to the incorrect report and therefore
avoid being tricked into thinking it was your page being validated.
If you have an existing page on the Web that you want to test, enter the URL in the text box below the banner "Check Documents by URL." In fact, you can test several documents at the same time. Just enter the URLs, one per line, including the http:// part.
If a file has many problems, the SGML parser stops after about 200 errors. This means the validation service stops as well and will not validate any remaining URLs.
If you want to test only a section of HTML source, you can paste it into the text box provided for this purpose. In either case, WebTechs applies the Level and gives you the Responses you specified in the preceding sections.
WebTechs is probably the most comprehensive of the verification services on-line. Its reports can also be the most difficult to understand. For that reason, you should become familiar with the FAQ (Frequently Asked Questions) File for the service. This tool is maintained by Scott Bigham at http://www.cs.duke.edu/~dsb/wt-faq.html.
Although using WebTechs is an excellent way to verify that your ![]() HTML
source is everything it should be, WebTechs does not check your links.
Most of the systems designed to check links run only on your own server.
If you don't have a server, fortunately, you can use Doctor HTML.
HTML
source is everything it should be, WebTechs does not check your links.
Most of the systems designed to check links run only on your own server.
If you don't have a server, fortunately, you can use Doctor HTML.
Doctor HTML is different from the other tools addressed in this chapter. To begin with, it examines only Web pages; it won't take snippets of HTML for analysis. But it also provides services not found in the other tools.
![]() Doctor
HTML performs a number of functions, as you can see in figure
19.5. Some of these functions overlap with the other HTML verifiers.
But the most important reasons for using
Doctor
HTML performs a number of functions, as you can see in figure
19.5. Some of these functions overlap with the other HTML verifiers.
But the most important reasons for using ![]() Doctor
HTML are to get verification that all the hyperlinks in your document are
valid and to get specific advice concerning optimization of your page performance.
Doctor
HTML are to get verification that all the hyperlinks in your document are
valid and to get specific advice concerning optimization of your page performance.
Fig. 19.5
You can use this form to order Doctor HTML's tests.
![]() Doctor
HTML is located at
Doctor
HTML is located at ![]() http://imagiware.com/RxHTML.cgi.
The Doctor performs a complete
http://imagiware.com/RxHTML.cgi.
The Doctor performs a complete ![]() Web
site analysis, according to your specifications. The strengths of the program
are in the testing of the images and the hyperlinks, functions not found
in other verification services. Be sure to read the test descriptions;
no separate FAQ is available.
Web
site analysis, according to your specifications. The strengths of the program
are in the testing of the images and the hyperlinks, functions not found
in other verification services. Be sure to read the test descriptions;
no separate FAQ is available.
The Doctor provides you with a report that is built "on-the-fly." It contains one section for each test you specified, and a summary. You are presented with the summary first, and from it you may select the individual test report sectiions. As an example, the three figures that follow are individual test report sections. These were returned in response to the request in figure 19.5 for examination of the Macmillan Information Superlibrary (tm) on the Web.
The hyperlinks test checks for "dead" hyperlinks on your page. The resulting report indicates whether the URL pointed to is still present or if the server returns an error, as shown in figure 19.6. The report also tells you how large the destination URL is; if you get a very small size for a destination, check it by hand to determine whether the server is returning an error message.
Fig. 19.6
This typical report from ![]() Doctor
HTML describes the hyperlinks found in a document.
Doctor
HTML describes the hyperlinks found in a document.
Note that just because the report says the link is apparently valid, the page pointed to is not necessarily what it was when you set up the link. You should use the URL-Minder service described in the section "Using Other Verification Services on the Web," to track changes to the pages your links identify. The Doctor uses a 10-second time-out for each link test; slow links may time-out, and you will have to test them individually.
To tweak your page performance, you get maximum results from fixing image syntax, reducing image bandwidth requirements, and making sure that your table and form structures are right. The Doctor provides a wealth of information in all these areas.
This special report identifies images that take an excessive amount of bandwidth and that load slowly, as shown in figure 19.7. It also gives the specific image command tags to set to improve overall page performance (see fig. 19.8).
Fig. 19.7
Doctor HTML's report on images is helpful in identifying any picture that is slowing down your page.
Fig. 19.8
These image command tags require resetting, according to Doctor HTML.
The Kinder-Gentler Validator (sometimes called simply KGV) is a newer tool for validating HTML source and Web pages. You will find KGV at http://ugweb.cs.ualberta.ca/~gerald/validate.cgi. It provides informative reports, even pointing to the errors it detects. Figure 19.9 is an example of just how helpful KGV can be.
Fig. 19.9
This figure shows an example of the helpful reports provided by the Kinder-Gentler Validator.
While KGV's reports are easier to interpret than WebTechs, you should obtain the KGV FAQ which explains the more impenetrable messages that still appear.
The FAQ for
KGV is very similar in some respects to WebTechs; both of them completely parse your HTML source code. Both obey the rules of the HTML language definition to the letter. And both are based on James Clark's sgmls SGML parsers.
But there is at least one big difference. KGV expects that your document
will either be ![]() HTML
2.0 conformant, or that it will have a DOCTYPE declaration on the first
line. If KGV doesn't find a DOCTYPE, it assumes the document is supposed
to be 2.0 conformant. No nice row of radio button selections here!
HTML
2.0 conformant, or that it will have a DOCTYPE declaration on the first
line. If KGV doesn't find a DOCTYPE, it assumes the document is supposed
to be 2.0 conformant. No nice row of radio button selections here!
KGV also has a ![]() public
identifier catalog, located at http://ugweb.cs.ualberta.ca/~gerald/validate/lib/catalog.
This is a longer and more complete public identifier list than WebTechs.
All the warnings given under the
public
identifier catalog, located at http://ugweb.cs.ualberta.ca/~gerald/validate/lib/catalog.
This is a longer and more complete public identifier list than WebTechs.
All the warnings given under the ![]() WebTechs
description about using the correct DOCTYPE and about spelling errors apply
to KGV as well.
WebTechs
description about using the correct DOCTYPE and about spelling errors apply
to KGV as well.
The interface for KGV (fig. 19.10) is
a bit simpler than the one for WebTechs, as you might expect. You have
the option to include an analysis by Weblint, another ![]() verification
tool that is discussed in the next section of this chapter.
verification
tool that is discussed in the next section of this chapter.
Fig. 19.10
The Kinder-Gentler Validator interface is simple but complete.
Notice that KGV provides two additional types of output. These may be
helpful when dealing with difficult problems. ![]() Show
Source Input displays the
Show
Source Input displays the ![]() HTML
text with line numbers.
HTML
text with line numbers. ![]() Show
Parse Tree shows you how KGV parses your file. These are similar to WebTechs
options "Show Input" and "Show Parser Output."
Show
Parse Tree shows you how KGV parses your file. These are similar to WebTechs
options "Show Input" and "Show Parser Output."
Finally, ![]() Kinder-Gentler
Validator provides an icon when your source code passes its test, just
like WebTechs. You can paste the snippet of code that KGV provides into
your document so that all who view it know you build righteous HTML.
Kinder-Gentler
Validator provides an icon when your source code passes its test, just
like WebTechs. You can paste the snippet of code that KGV provides into
your document so that all who view it know you build righteous HTML.
Weblint takes a middle ground with ![]() HTML
verification. One of its strengths is that it looks for specific common
errors known to cause problems for popular browsers. This makes it a heuristic
validator, as opposed to KGV and WebTechs which are parsers. "Heuristic"
simply means that it operates from a set of guidelines about HTML style.
HTML
verification. One of its strengths is that it looks for specific common
errors known to cause problems for popular browsers. This makes it a heuristic
validator, as opposed to KGV and WebTechs which are parsers. "Heuristic"
simply means that it operates from a set of guidelines about HTML style.
Weblint performs 22 specific checks. It is looking for constructs that are legal HTML but bad style, as well as for mistakes in the source code. Here is the list, as shown by UniPress (Weblint' publisher) for Weblint v1.014:
On the other hand it misses some outright errors from time to time.
One reason that KGV offers the option of showing ![]() Weblint's
findings about a
Weblint's
findings about a ![]() Web
page is to provide style feedback that WebTechs is missing. If you routinely
use WebTechs, you should make it a habit to also run your page by Weblint.
Or switch to KGV and always take the
Web
page is to provide style feedback that WebTechs is missing. If you routinely
use WebTechs, you should make it a habit to also run your page by Weblint.
Or switch to KGV and always take the ![]() Weblint
option. By using both a parser and a heuristic verifier, you will spot
many problems that would otherwise be missed if you used only one or the
other.
Weblint
option. By using both a parser and a heuristic verifier, you will spot
many problems that would otherwise be missed if you used only one or the
other.
You can access Weblint on the Web in three places. One is http://www.unipress.com/weblint/;
this is the publisher's site. Another is http://www.khoros.unm.edu/staff/neilb/weblint/lintform.html.
Figure 19.11 shows the latter interface.
Finally, a ![]() Weblint
Gateway has recently been opened to provide a very streamlined way to obtain
Weblint
Gateway has recently been opened to provide a very streamlined way to obtain
![]() verification
of your Web page: http://www.cen.uiuc.edu/cgi-bin/weblint.
verification
of your Web page: http://www.cen.uiuc.edu/cgi-bin/weblint.
FIG. 19.11
The Weblint interface is another simple design; you may enter either a URL or HTML code.
With Weblint, like WebTechs, you can either submit the URL of a page to be verified, or enter HTML directly into a text box. You have the options in the reports of seeing the HTML source file (automatically line-numbered) and to view the page being checked. You also can have either Netscape or Java extensions checked.
Like KGV, Weblint reports from either Web site are easy to understand (fig. 19.12). However, the reports are not as comprehensive as those provided by WebTechs or KGV.
Fig. 19.12
Weblint provides an easy-to-read, brief report.
Wouldn't it be nice if you could do all your verification from one place, instead of having to run from one verification site to another? Well, you nearly can. Harold Driscoll, Webmaster for the Chicago Computer Society, has assembled a page at http://www.ccs.org/validate. This page will save you a lot of work (see fig. 19.13).
Fig. 19.13
The Chicago Computer Society's Suite of HTML Validation Suites.
The ![]() Suite
of HTML Validation Suites page includes forms that check your page using
the three most popular validation services (Kinder-Gentler Validation,
Weblint, and WebTechs). Fill in the URL you want checked, and select the
switch settings you want. The page returns all your reports in the same
format.
Suite
of HTML Validation Suites page includes forms that check your page using
the three most popular validation services (Kinder-Gentler Validation,
Weblint, and WebTechs). Fill in the URL you want checked, and select the
switch settings you want. The page returns all your reports in the same
format.
WeblintIn addition, this one-stop service includes forms for several
other tools. A spell checker (WebSter's Dictionary) returns a list of any
words that it does not recognize on your page. The Lynx-Me Text Browser
Display shows you what your Web page looks like to viewers using the text
browser Lynx. The ![]() HTTP
Head Request Form and a form titled
HTTP
Head Request Form and a form titled ![]() Display
Typical CGI Environment Strings can help when you are writing and debugging
CGI programs and scripts. And finally, another form makes it easy to register
with the URL-Minder service (see the section on URL-Minder in "Using
Other Verification Services on the Web).
Display
Typical CGI Environment Strings can help when you are writing and debugging
CGI programs and scripts. And finally, another form makes it easy to register
with the URL-Minder service (see the section on URL-Minder in "Using
Other Verification Services on the Web).
I notice that each verification service seems to report different problems when I submit the same URL to all of them. What can I do about this?
Always use a combination strategy when checking a URL. That is, use one of the syntax checkers (WebTechs or KGV, but not both) and one of the heuristic checkers (Weblint or its alternate at the U.S. Military Academy, described in the next section). By using both types of checkers, and only one of each, you will cut down on the apparent contradictions. Consistency in the way you do your checks is very important.
Where can I find an explanation of the error messages in WebTechs and KGV reports?
Both of these verifiers use the error messages provided by their
It pays to look for other verification services; a large number of them
are on the ![]() Web.
Perform a search on the
Web.
Perform a search on the ![]() keywords
verification service, or use other search tools besides Yahoo. I found
the services in Table 19.6 this way.
keywords
verification service, or use other search tools besides Yahoo. I found
the services in Table 19.6 this way.
I use these services mainly as a backup. The more popular services are sometimes busy, and you can't get onto them. The Slovenian site for HTMLchek, Brown University, Harbinger Net Services, and the U.S. Military Academy, all discussed in this section, are good alternatives.
Finally, the URL-Minder service can be a true blessing to the person with too many links to maintain. It provides you with a way to know when a change occurs to a page that one of your own pages references.
Table 19.6 - Other verification services on the Web.
| Service Name | URL |
| Slovenian HTMLchek | http://www.ijs.si/cgi-bin/htmlchek |
| U.S.M.A. (West Point) | http://www.usma.edu/cgi-bin/HTMLverify |
| Brown University | http://www.stg.brown.edu/service/url_validate.html |
| Harbinger | http://www.harbinger.net/html-val-svc/ |
| URL-Minder | http://www.netmind.com/URL-minder/example.html |
HTMLchek is an interesting tool put together at the ![]() University
of Texas at Austin. However, the on-Web version is offered by someone at
a site in Slovenia (http://www.ijs.si/cgi-bin/htmlchek).
University
of Texas at Austin. However, the on-Web version is offered by someone at
a site in Slovenia (http://www.ijs.si/cgi-bin/htmlchek).
HTMLchek does syntax and semantic checking of URLs, against HTML 2.0,
HTML 3.0, or Netscape DTDs. It also looks for common errors. It is another
![]() heuristic
verifier and can be used as an alternative to Weblint.
heuristic
verifier and can be used as an alternative to Weblint.
HTMLchek returns reports that are not as well-formatted or easy to read as Weblint's. However, they report approximately the same kinds of problems, to the same level of detail. There is no FAQ file for the Slovenian site, but full documentation is available for download at http://uts.cc.utexas.edu/~churchh/htmlchek.html.
Figure 19.14 shows the ![]() HTMLverify
service offered by
HTMLverify
service offered by ![]() usma.edu
(that's the U.S. Military Academy at West Point, in case you aren't an
alum). The URL for the service is http://www.usma.edu/cgi-bin/HTMLverify.
You can enter the URL of your page, or you can paste HTML source into the
window. The system checks whatever you enter or paste against plain-vanilla
HTML 2.0 standards alone. You can choose to have it include a check against
the Netscape extensions as well.
usma.edu
(that's the U.S. Military Academy at West Point, in case you aren't an
alum). The URL for the service is http://www.usma.edu/cgi-bin/HTMLverify.
You can enter the URL of your page, or you can paste HTML source into the
window. The system checks whatever you enter or paste against plain-vanilla
HTML 2.0 standards alone. You can choose to have it include a check against
the Netscape extensions as well.
Fig. 19.14
HTMLverify is a basic ![]() HTML
verification service, offered by the
HTML
verification service, offered by the ![]() U.S.
Military Academy at
U.S.
Military Academy at ![]() West
Point.
West
Point.
HTMLverify is actually an interface to a modified version of Weblint, so it's another heuristic checker. If you enter a URL in the first text box and then click the Verify button at the bottom of the form, you get a report of any problems Weblint found with the HTML source. This report may look something like the one shown in figure 19.15. As with any automatically generated report, not every error reported is really an error. However, the report does generate a worthwhile list of items.
Fig. 19.15
The ![]() HTML
Verification Output from HTMLverify for the
HTML
Verification Output from HTMLverify for the ![]() Macmillan
Superlibrary Web Page indicates a few problems with the source.
Macmillan
Superlibrary Web Page indicates a few problems with the source.
Brown University's Scholarly Technology Group (STG) maintains a verification service at http://www.stg.brown.edu/service/url_validate.html. This is about as simple an interface as you will see anywhere. It consists of a text box, where you enter the URL to verify. You select the DTD to use from a pull-down list; this includes Netscape 1.1 (default), HTML 2.0, HTML 3.0, and TEI Lite. You can check a box to ask for a parse outline, and then you click the Validate button.
The output is similar to WebTechs for the level of obscurity, but it seems to be complete. It is very fast. Like WebTechs, the STG's service is a parser. It would be a good alternative to WebTechs or to KGV. There is no FAQ.
This is a site where ![]() WebTechs
HTML Check Toolkit has been installed and made available to the
WebTechs
HTML Check Toolkit has been installed and made available to the ![]() Web.
The interface is an exact duplicate of the
Web.
The interface is an exact duplicate of the ![]() WebTechs
site. The use of the tool and the reports it returns are also exactly the
same in every respect.
WebTechs
site. The use of the tool and the reports it returns are also exactly the
same in every respect.
This service was formerly located at Georgia Tech, but moved with Kipp Jones to Harbinger Net Services. You will find the verifier at http://www.harbinger.net/html-val-svc/.
This isn't exactly a verification service, but it can be a great help to you in keeping your links updated and the dead links pruned. The URL-Minder service notifies you whenever there is a change to URLs to which you have embedded links on your page. You register your email address and the other pages with URL-Minder at http://www.netmind.com/URL-minder/example.html. (This address also takes you to a complete description of the service.) The service sends you email within a week of any changes to the pages you specify.
You can also embed a form on your page that readers can use to request notification from URL-Minder whenever your page changes. You can set this up so that customers get either a generic message or a tailored one.
I get so many errors from some of these verification services, where should I begin fixing problems?
Most of the verifiers will return more than one error statement for each actual error. In addition, if there are a lot of errors, the verifier may become confused. The best strategy is to fix the first few problems in the report, then resubmit the URL or source code for checking. This tends to very quickly reduce the number of errors reported.
I'm really having trouble understanding these terse error statements. Where can I get help?
If the verifier offers the option, try running in "pedantic" mode. This will give you longer explanations.
The ![]() WebTechs
Validation Service is the definitive HTML-checker on the
WebTechs
Validation Service is the definitive HTML-checker on the ![]() Web.
A version of the software has always been available for installation on
local servers, but it wasn't always easy to obtain. It was also not easy
to install successfully.
Web.
A version of the software has always been available for installation on
local servers, but it wasn't always easy to obtain. It was also not easy
to install successfully.
WebTechs has solved these problems with its ![]() HTML
Check Toolkit. WebTechs now offers an interactive on-line service whereby
you specify the type of operating system you are running, the directories
in which the software is to be installed, and the type of compressed tar
file you require. WebTechs server will build a toolkit tailored to these
specifications and download it to you. It also builds a set of installation
and testing instructions tailored to your system.
HTML
Check Toolkit. WebTechs now offers an interactive on-line service whereby
you specify the type of operating system you are running, the directories
in which the software is to be installed, and the type of compressed tar
file you require. WebTechs server will build a toolkit tailored to these
specifications and download it to you. It also builds a set of installation
and testing instructions tailored to your system.
To install and use the toolkit, you need about 500 KB of disk space, and one of the following twenty-four operating systems (others are being added):
To obtain the toolkit, go to the WebTechs home page at http://www.webtechs.com
and choose the link "HTML Check Toolkit." From that page, after
reading any updates to the information you see in this book, choose "Downloading
and Configuration." You're on your way to HTML verification from the
comfort and convenience of your own server. When you are finished, you
will be able to type html-check *.![]() html
and get a complete validation of your
html
and get a complete validation of your ![]() HTML
files.
HTML
files.
You can download three of the other tools discussed in this chapter and install them on your own server. There are a number of others tools available as well. Several of these are listed in Table 19.7.
Table 19.7 - Verification tools available from ![]() Web
sites to be run on your server.
Web
sites to be run on your server.
| Tool | Function | Source |
| Weblint | Checks syntax and style | http://www.khoros.unm.edu/staff/neilb/weblint.html |
| HTMLChek | Syntax checker; | http://uts.cc.utexas.edu/~churchh/htmlchek.html |
| HTMLverify | Weblint interface | http://www.usma.edu/cgi-bin/HTMLverify |
| MOMspider | Robot link maintainer | http://www.ics.uci.edu/WebSoft/MOMspider |
| Webxref | Cross-references links | http://www.sara.nl/cgi-bin/rick_acc_webxref |
| Verify Web Links | Checks validity of links | http://wsk.eit.com/wsk/dist/doc/admin/webtest/verify_links.html |
| Ivrfy | HTML link verifier | http://www.cs.dartmouth.edu/~crow/lvrfy.html |

In most cases,
Nearly all of these are ![]() perl
scripts but not all require that your server be running under
perl
scripts but not all require that your server be running under ![]() Unix.
For example, HTMLchek will run on any platform for which perl and awk are
available, including the Mac and MS-DOS.
Unix.
For example, HTMLchek will run on any platform for which perl and awk are
available, including the Mac and MS-DOS.
After you download and install the script for the program of your choice, your server can run your maintenance program for you. Most of programs run from the command line and report directly back. Some of the tools will e-mail the reports to you or to whomever you designate.
Weblint is available at no charge via anonymous ![]() ftp
from ftp://ftp.khoral.com/pub/weblint/,
as a gzip tar file or a ZIP archive for PC users. The tar file (weblint-1.014.tar.gz)
is 46K, the ZIP file (weblint.zip) is 53K. Neil Bowers <neilb@khoral.com>
is the owner of the program and welcomes your comments, suggestions and
bug reports.
ftp
from ftp://ftp.khoral.com/pub/weblint/,
as a gzip tar file or a ZIP archive for PC users. The tar file (weblint-1.014.tar.gz)
is 46K, the ZIP file (weblint.zip) is 53K. Neil Bowers <neilb@khoral.com>
is the owner of the program and welcomes your comments, suggestions and
bug reports.
The program is also supported by two ![]() email
lists. Announcements for new versions are made via
email
lists. Announcements for new versions are made via ![]() weblint-announce@khoral.com.
Discussions related to weblint and pre-release testing are carried on via
weblint-victims@khoral.com. Email Neil Bowers to be added to either list,
or to obtain details of system requirements for Weblint.
weblint-announce@khoral.com.
Discussions related to weblint and pre-release testing are carried on via
weblint-victims@khoral.com. Email Neil Bowers to be added to either list,
or to obtain details of system requirements for Weblint.
HTMLchek when run on your own server will perform more functions than
the version available over the ![]() Web.
Specifically, it will check the syntax of HTML 2.0 or 3.0 files for errors,
do local link cross-reference checking, and generate a basic reference-dependency
map. It also includes utilities to process HTML files; examples include
an HTML-aware search-and-replace program, a program to remove HTML so that
a file can be spell-checked, and a program that makes menus and tables
of contents within HTML files.
Web.
Specifically, it will check the syntax of HTML 2.0 or 3.0 files for errors,
do local link cross-reference checking, and generate a basic reference-dependency
map. It also includes utilities to process HTML files; examples include
an HTML-aware search-and-replace program, a program to remove HTML so that
a file can be spell-checked, and a program that makes menus and tables
of contents within HTML files.
![]() HTMLchek
runs under
HTMLchek
runs under ![]() perl
and
perl
and ![]() awk
but is not Unix-dependent; it can be run under any operating system for
which awk and perl are available. This would include MS-DOS, Macintosh,
Windows NT, VMS, Amiga, OS/2, Atari and MVS platforms.
awk
but is not Unix-dependent; it can be run under any operating system for
which awk and perl are available. This would include MS-DOS, Macintosh,
Windows NT, VMS, Amiga, OS/2, Atari and MVS platforms.
HTMLchek is available at no charge via anonymous ![]() ftp
(use your email address as password) from ftp://ftp.cs.buffalo.edu/pub/htmlchek/.
The files are available as htmlchek.tar.Z, htmlchek.tar.gz, or htmlchek.zip.
Download the one that suits your platform. The documentation can be browsed
on line over the Web from http://uts.cc.utexas.edu/~churchh/htmlchek.html.
Other
ftp
(use your email address as password) from ftp://ftp.cs.buffalo.edu/pub/htmlchek/.
The files are available as htmlchek.tar.Z, htmlchek.tar.gz, or htmlchek.zip.
Download the one that suits your platform. The documentation can be browsed
on line over the Web from http://uts.cc.utexas.edu/~churchh/htmlchek.html.
Other ![]() ftp
sites from which the
ftp
sites from which the ![]() proram
can be obtained are listed in the documentation, under the heading, "Obtaining
HTMLchek." These alternates include the Usenet (comp.sources.misc
archives), Uunet, and one site in Germany.
proram
can be obtained are listed in the documentation, under the heading, "Obtaining
HTMLchek." These alternates include the Usenet (comp.sources.misc
archives), Uunet, and one site in Germany.
HTMLchek is supported by the author, H. Churchyard, at <churchh@uts.cc.utexas.edu>.
Erich Markert, the webmaster at the Academy, has authorized downloading
of the perl CGI script for HTMLverify. All you need do is click the button
marked "Source" at the bottom of the ![]() HTMLverify
form (http://www.usma.edu/cgi-bin/HTMLverify)
to obtain the perl script. Clicking the "About" button will bring
you the details of installation.
HTMLverify
form (http://www.usma.edu/cgi-bin/HTMLverify)
to obtain the perl script. Clicking the "About" button will bring
you the details of installation.
In addition to the source code for HTMLverify, you will need perl 5,
Lynx version 2.3.7, Weblint (Markert offers his modified version), Lincoln
Stein's CGI Module, and Markert's HTML module. All of these except for
![]() Lynx
are available from the
Lynx
are available from the ![]() USMA
site.
USMA
site.
HTMLverify may be the easiest of all the verification checkers to obtain and install.
MOMspider is a ![]() freeware
robot designed to assist in the
freeware
robot designed to assist in the ![]() maintenance
of distributed hypertext infostructures. When installed, MOMspider will
periodically search a list of webs provided by you. It looks for four types
of document change: moved documents, broken links, recently modified documents,
and documents about to expire. MOMspider builds a special index document
that lists these problems when found, plus other information you requested.
MOMspider will report directly to you or by email to any address you provide.
maintenance
of distributed hypertext infostructures. When installed, MOMspider will
periodically search a list of webs provided by you. It looks for four types
of document change: moved documents, broken links, recently modified documents,
and documents about to expire. MOMspider builds a special index document
that lists these problems when found, plus other information you requested.
MOMspider will report directly to you or by email to any address you provide.
MOMspider requires ![]() perl
4.036 and runs on
perl
4.036 and runs on ![]() Unix-based
systems. You will need to customize the perl script for your site. You
obtain MOMspider, with installation notes, configuration options, and instruction
files, from http://www.ics.uci.edu/WebSoft/MOMspider.
You can also obtain it via anonymous ftp from ftp://liege.ics.uci.edu/pub/arcadia/MOMspider.
A paper describing the MOMspider and its use can be obtained from http://cgl.ucsf.edu/home/MOMspider/MOMspider-1.00/docs/usage.html.
Unix-based
systems. You will need to customize the perl script for your site. You
obtain MOMspider, with installation notes, configuration options, and instruction
files, from http://www.ics.uci.edu/WebSoft/MOMspider.
You can also obtain it via anonymous ftp from ftp://liege.ics.uci.edu/pub/arcadia/MOMspider.
A paper describing the MOMspider and its use can be obtained from http://cgl.ucsf.edu/home/MOMspider/MOMspider-1.00/docs/usage.html.
Webxref is a ![]() perl
program that makes cross references from an
perl
program that makes cross references from an ![]() HTML
document and the
HTML
document and the ![]() HTML
documents linked from it. It is designed to provide a quick and easy check
of a local set of HTML documents. It will also check the first level of
external URLs referenced by the original document.
HTML
documents linked from it. It is designed to provide a quick and easy check
of a local set of HTML documents. It will also check the first level of
external URLs referenced by the original document.
When the program has run, it prints a list, with direct and indirect references, of items it found in the file in seventeen different categories, including:
You can download Webxref directly from the author at http://www.sara.nl/cgi-bin/ric_acc_webxref. The author is Rick Jansen and you can contact him by email at <rick@sara.nl>.
Ivrfy is a ![]() freeware
shell script that verifies all the internal links in
freeware
shell script that verifies all the internal links in ![]() HTML
pages on your server. It also checks the inline images in the documents.
Ivrfy is slow; the author reports that it can process 10000 links to 4000
pages in an hour and a half on a Sparc 1000 with dual 75MHz CPU's.
HTML
pages on your server. It also checks the inline images in the documents.
Ivrfy is slow; the author reports that it can process 10000 links to 4000
pages in an hour and a half on a Sparc 1000 with dual 75MHz CPU's.
Ivrfy assumes that you have five programs in your path: sed, awk, chs, touch, and rm. Obviously this means this is a Unix-only program. Ivrfy is not secure and should not be run as root. The script requires customization, to specify the name of the server in use, the server's root directory, and three other variables. These are all identified in the README found on the Ivrfy Web page.
Ivrfy is executed from the command line. It reports back the links for which pages were successfully found, those for which the links are broken, and those for which the link was an HTTP link to another server. Broken links include non-existent pages, unreadable pages, and server-generated index pages. There are a few known bugs and these are all listed in the README.
Download the Ivrfy script from http://www.cs.dartmouth.edu/~crow/Ivrfy.html. The author, Preston Crow, can be reached by email at <crow@cs.dartmouth.edu>.
![]() Enterprise
Integration Technologies Corporation is in the process of developing a
Enterprise
Integration Technologies Corporation is in the process of developing a
![]() Webtest
tool suite for its
Webtest
tool suite for its ![]() Web
Starter Kit. One part of this suite is a link verifier for use by server
administrators. It will aid in maintaining links within documents managed
at a site. The link verifier tool starts from a given URL and traverses
links outward to a specified limit. The verifier then produces a report
on the state of the discovered links.
Web
Starter Kit. One part of this suite is a link verifier for use by server
administrators. It will aid in maintaining links within documents managed
at a site. The link verifier tool starts from a given URL and traverses
links outward to a specified limit. The verifier then produces a report
on the state of the discovered links.
In its present form, the link verifier verifies only http: HREFs in
SRC, A, FORM, LINK and BASE tags. It does not verify non-HTTP links (gopher,
ftp, file, and so on). This is planned for the future. The verifier will
exercise links to remote servers, but it does not attempt to examine the
contents of the documents on those servers. Among other interesting features,
the verifier can send reports to the administrator by ![]() email,
and will verify form
email,
and will verify form ![]() POST
actions. The tool does try to use bandwidth well; it uses HEAD requests
on image data and remote documents.
POST
actions. The tool does try to use bandwidth well; it uses HEAD requests
on image data and remote documents.
The link verifier tool can be downloaded by anonymous ![]() ftp
from ftp://ftp.eit.com/pub/eit/wsk/<OS_TYPE>/webtest/verify_links.tar.
The <OS_TYPE must be one of the following: sunos (for 4.1.3), solaris
(for 2.3), irix, aix, or osfi. No other platforms are supported at this
time. A description of the tool is available at http://wsk.eit.com/wsk/dist/doc/admin/webtest/verify_links.html.
ftp
from ftp://ftp.eit.com/pub/eit/wsk/<OS_TYPE>/webtest/verify_links.tar.
The <OS_TYPE must be one of the following: sunos (for 4.1.3), solaris
(for 2.3), irix, aix, or osfi. No other platforms are supported at this
time. A description of the tool is available at http://wsk.eit.com/wsk/dist/doc/admin/webtest/verify_links.html.
All the verification services discussed to this point in this chapter
ensure that your ![]() Web
page makes sense to the
Web
page makes sense to the ![]() Web
browsers. Using valid
Web
browsers. Using valid ![]() HTML
is only one of several factors in creating a quality
HTML
is only one of several factors in creating a quality ![]() Web
page. What makes a great page is valid
Web
page. What makes a great page is valid ![]() HTML
plus outstanding content, attractive presentation, elegant layout and style,
and a certain
HTML
plus outstanding content, attractive presentation, elegant layout and style,
and a certain ![]() je
ne sais quoi. To master these elements, considering what other Webmasters
have done to create exemplary
je
ne sais quoi. To master these elements, considering what other Webmasters
have done to create exemplary ![]() Web
pages is very useful. The various recognition services can be of great
use in this area.
Web
pages is very useful. The various recognition services can be of great
use in this area.
Several recognition services appear on the Web. Many of them seem to
focus on identifying the "cool" sites. Some of the "cool"
sites have so many awards, plaques, badges, and other meritorious ![]() graphics
displayed that they appear to have had a plate of fruit salad spilled on
them.
graphics
displayed that they appear to have had a plate of fruit salad spilled on
them.
Being cool is fine, but not necessarily a sign of quality that endures and attracts customers with money to spend (if that is your aim). Being cool is a fashion statement for the day, and perhaps you are looking for something a little more enduring. Finally, being cool and being worth a second read may be different concepts.
So how does a ![]() Web
author who aspires to quality, like yourself, find the paragons of taste
and utility? Two awards have distinguished themselves for their ability
to pick enduring winners. They are High Five and Point Top Five. You can
and should study sites that have received these honors, with the confidence
that such sites had to meet extraordinarily stringent standards.
Web
author who aspires to quality, like yourself, find the paragons of taste
and utility? Two awards have distinguished themselves for their ability
to pick enduring winners. They are High Five and Point Top Five. You can
and should study sites that have received these honors, with the confidence
that such sites had to meet extraordinarily stringent standards.
You may have seen this icon  on
a few especially elegant pages on the Web. The High Five Awards Committee
gives this plaque to one well-designed site a week. Any site that displays
this icon has been selected on the basis of design, conception, execution,
and content, with an emphasis on clear information design and aesthetics.
High Five (http://www.highfive.com)
is sponsored by David Siegel and sustained by the efforts of his six interns.
They reside in Palo Alto, California.
on
a few especially elegant pages on the Web. The High Five Awards Committee
gives this plaque to one well-designed site a week. Any site that displays
this icon has been selected on the basis of design, conception, execution,
and content, with an emphasis on clear information design and aesthetics.
High Five (http://www.highfive.com)
is sponsored by David Siegel and sustained by the efforts of his six interns.
They reside in Palo Alto, California.
No matter who the other person or persons on the High Five Awards Committee
may be, the guiding light is David Siegel. David is a type designer, ![]() typographer,
writer, and
typographer,
writer, and ![]() Web
site designer. He has some very definite ideas about what is good in Web
site design and what is not.
Web
site designer. He has some very definite ideas about what is good in Web
site design and what is not.
Because David is a graphic designer, you will find that his ideas about
quality are different from what many ![]() HTML
mavens define as quality. For example, many SGML and HTML purists don't
much care for Netscape. David believes that Netscape lets him do more of
the things he wants to do. He does not feel obligated to make pages that
are optimized for all browsers.
HTML
mavens define as quality. For example, many SGML and HTML purists don't
much care for Netscape. David believes that Netscape lets him do more of
the things he wants to do. He does not feel obligated to make pages that
are optimized for all browsers.
As a technical person who has also been a calligrapher for many years,
I like what David Siegel does in his page designs. Before you make up your
mind about Siegel's philosophy, take a look at the pages that receive the
High Five. Let your eyes tell you what they like instead of being guided
solely by what the ![]() HTML
rulebook says.
HTML
rulebook says.
Spending some time on David Siegel's Web site, the Casbah at http://www.dsiegel.com/, would be well worth your while. David provides an informative set of Tips for Writers and Designers, which includes some invaluable help with layout via the "single-pixel GIF trick." You will also like his tip on using images well.
If you look through David Siegel's gallery of past winners, you are
going to see some beautiful, effective Web pages. To understand why they
work and how to make yours look like them, consider the three High Five
criteria. ![]() High
Five awards a perfect page five points in each of the following categories:
Degree of Difficulty, Execution, and Aesthetics.
High
Five awards a perfect page five points in each of the following categories:
Degree of Difficulty, Execution, and Aesthetics.
These three criteria have equal weight (in theory), and they are all subjective. You may want to read the critiques of past winners to get a handle on the meaning of each term and what each one contributes to the final appearance of a page. Reading Siegel's essays, "Severe Tire Damage" and "The Balkanization of the Web," may also help.
The High Five page itself also provides some further hints. It is pretty clear that four things will rule out a page from consideration: table borders, Netscape backgrounds, GIFs that interfere with the message, and general ugliness.
The whole point to High Five and Siegel's Web site is that you, as a designer, should not just accept the way HTML tries to get you to make your pages look. You are designing pages to be read by human beings, not by Web browsers. What a human being sees and how a human being responds to what is seen is informed by thousands of years of culture and individual experience with books and art. You aren't going to change or get past that human bias with one more example of default layout. To be successful and rise above the gray mass of most cyber-publishing, appeal to the aesthetics and culture of your reader.
You can submit your Web page to the High Five Awards Committee for consideration.
The instructions are in ![]() David
Siegel's Frequently Asked Questions file, and guidelines appear on the
David
Siegel's Frequently Asked Questions file, and guidelines appear on the
![]() High
Five page. Read them thoroughly, along with the rest of the information
on the Casbah and High Five sites.
High
Five page. Read them thoroughly, along with the rest of the information
on the Casbah and High Five sites.
As Siegel reminds you several times, ![]() High
Five is the
High
Five is the ![]() Carnegie
Hall of Web page awards. You won't get there overnight. But when you think
your site is ready, submit it by sending e-mail to submissions@highfive.com.
David's interns will review your site first, and if it passes their scrutiny,
they will bring it to David's attention. If also passes David's scrutiny,
he will work with you to polish your page to meet his standards.
Carnegie
Hall of Web page awards. You won't get there overnight. But when you think
your site is ready, submit it by sending e-mail to submissions@highfive.com.
David's interns will review your site first, and if it passes their scrutiny,
they will bring it to David's attention. If also passes David's scrutiny,
he will work with you to polish your page to meet his standards.
Siegel also responds to e-mail questions about page design. Read the FAQ to find out what will catch his attention.
Another, more difficult, way to be recognized is to send up to three URLs to interns@highfive.com, along with a message about yourself. If one of the sites you submit is good enough to qualify as a High Five, Siegel will also take a look at your site.
You've probably seen this icon  also,
but on a larger number of Web sites. This icon indicates the Point Top
Five Survey award. Point also maintains a set of lists of "top tens"
in a number of fields.
also,
but on a larger number of Web sites. This icon indicates the Point Top
Five Survey award. Point also maintains a set of lists of "top tens"
in a number of fields.
The HTML verification services and High Five measure Web pages against
particular set standards of perfection. Point takes a different approach
and tries to measure ![]() Web
sites with a
Web
sites with a ![]() utilitarian
scale: how good is a site from the user's point of view?
utilitarian
scale: how good is a site from the user's point of view?
Point is a fairly large ![]() Internet
communications company located in New York. ("Fairly large" is
a relative term; in this case it means large enough to maintain a staff
of up to 24 Web site reviewers.)
Internet
communications company located in New York. ("Fairly large" is
a relative term; in this case it means large enough to maintain a staff
of up to 24 Web site reviewers.) ![]() Point's
Web Reviews give descriptions and ratings of the top 5 percent of all
Point's
Web Reviews give descriptions and ratings of the top 5 percent of all ![]() World
Wide Web sites. They consider it their mission to be a guide to the "good
stuff."
World
Wide Web sites. They consider it their mission to be a guide to the "good
stuff."
The ![]() home
page for Point is at http://www.pointcom.com/;
from there you can get to their Top Ten list and other features. One of
the first things you should grab is the FAQ file, which gives all the details
about Point's award system.
home
page for Point is at http://www.pointcom.com/;
from there you can get to their Top Ten list and other features. One of
the first things you should grab is the FAQ file, which gives all the details
about Point's award system.
Unlike High Five, Point never offers a critique of your page and does not work with award winners to help improve their products. You submit your page and wait. If the page isn't reviewed and awarded, wait a few months and notify the editors when you have added new material on your page.
Although High-Five looks for aesthetic perfection, Point works hard at identifying "the best, smartest, and most entertaining sites around." In addition to the large staff of reviewers, Point considers self-nominations and nominations that they receive from Web surfers to locate sites for review.
![]() Web
sites are rated on 50-point scales against three criteria: Content, Presentation,
and Experience. To be more specific, here are the official descriptions:
Web
sites are rated on 50-point scales against three criteria: Content, Presentation,
and Experience. To be more specific, here are the official descriptions:
Point reviews each page at least four times a year, and it removes sites that have fallen to lower standards. The reviewers give the Top Five award to any page that meets the excellence criteria, whether the page is commercial, private, or student-run.
You can submit your own page for review by using the ![]() Write
Us form on the
Write
Us form on the ![]() home
page, or you can e-mail the URL and a description of the site to submit@pointcom.com.
You are notified only if you are awarded a Top Five. If you don't hear
from Point, resubmit your page at a later time.
home
page, or you can e-mail the URL and a description of the site to submit@pointcom.com.
You are notified only if you are awarded a Top Five. If you don't hear
from Point, resubmit your page at a later time.
Once a page is recognized, Point places it among the other winners in its category. Newly reviewed sites also appear in "New & Noteworthy," a daily feature on Point's home page. Finally, the best of the best are added to the Top Ten lists; they are the top ten sites in each category in the Point review catalog.
One of the best resources you could ever hope for comes in the form
of other Web developers. Many other people have been through the process
of developing a ![]() Web
site into a thing of beauty, value, or usefulness. When you see a Web site
or a page that you really like, drop the Webmaster or the page owner a
note to say how much you enjoy the creation. If you ask a polite question
or two about how that author did something, you'll most likely get an answer.
Web
site into a thing of beauty, value, or usefulness. When you see a Web site
or a page that you really like, drop the Webmaster or the page owner a
note to say how much you enjoy the creation. If you ask a polite question
or two about how that author did something, you'll most likely get an answer.
You can find other ![]() Web
developers in many
Web
developers in many ![]() Usenet
newsgroups and mailing lists. Here are some of the best:
Usenet
newsgroups and mailing lists. Here are some of the best:
Newsgroups
alt.fan.mozilla
alt.hypertext
comp.infosystems.www.authoring.cgi
comp.infosystems.www.authoring.html
comp.infosystems.www.authoring.images
comp.text.sgml
Mailing Lists
HTML Authoring Mailing List (see http://www.netcentral.net/lists/html-list.html)
NETTRAIN Mailing List
You can also find plenty of pages and other features that give you good advice about page design. Here are three of the best:


|


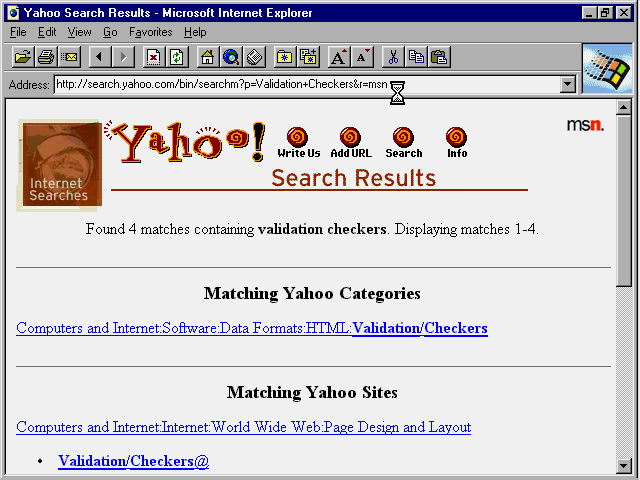{kind=link}
{kind=link}
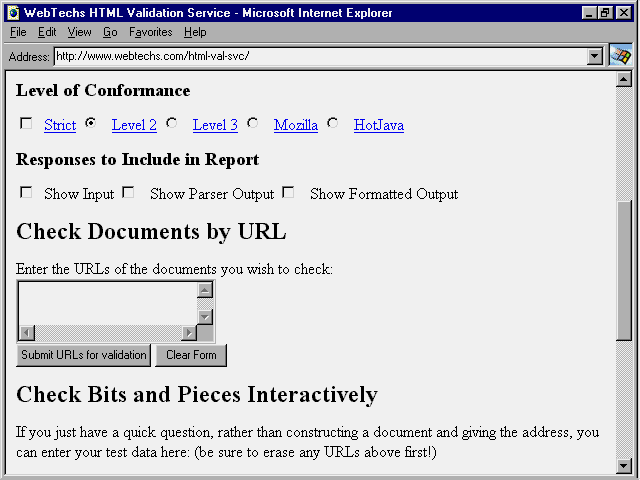{kind=link}
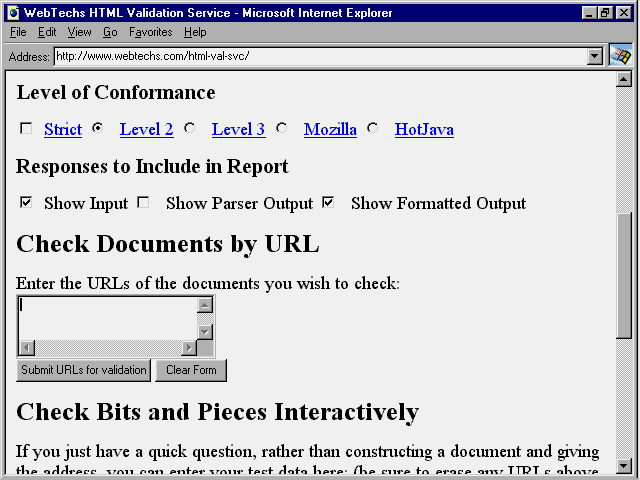{kind=link}
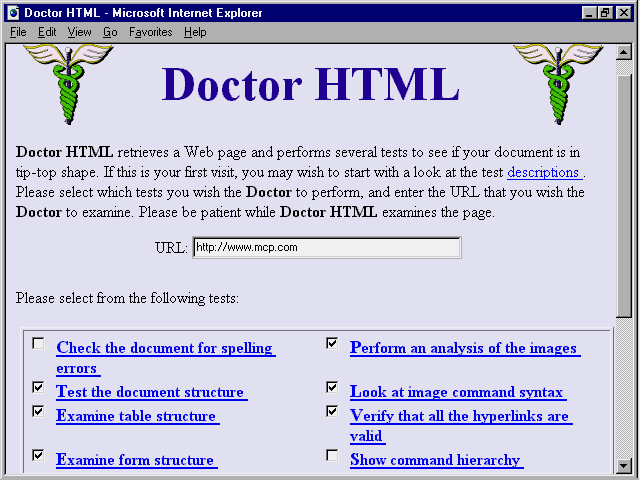{kind=link}
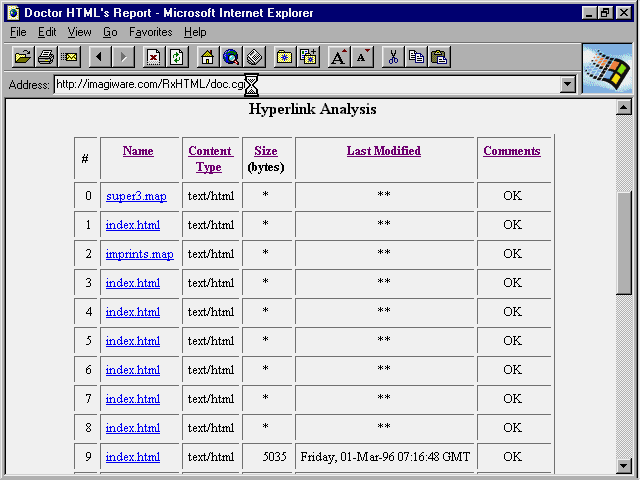{kind=link}
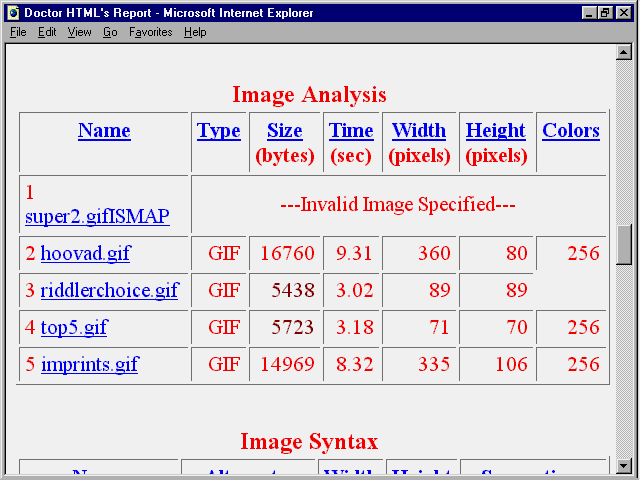{kind=link}
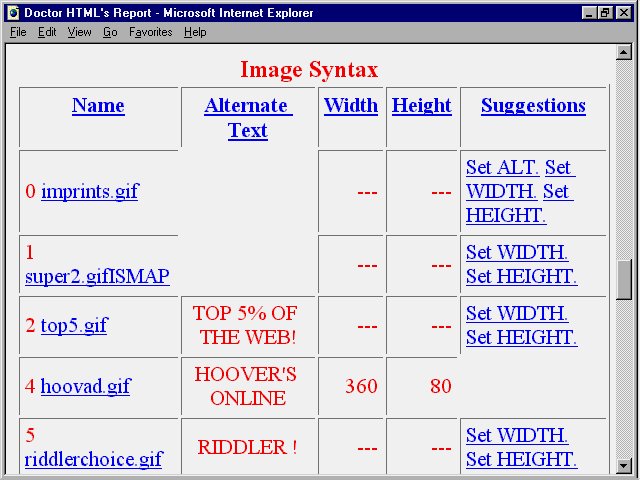{kind=link}
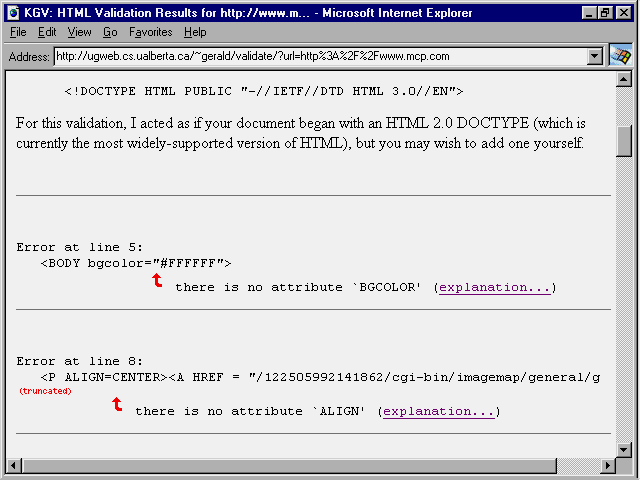{kind=link}
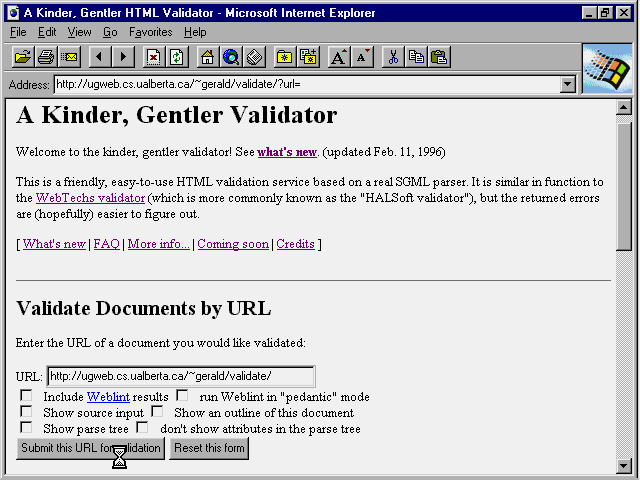{kind=link}
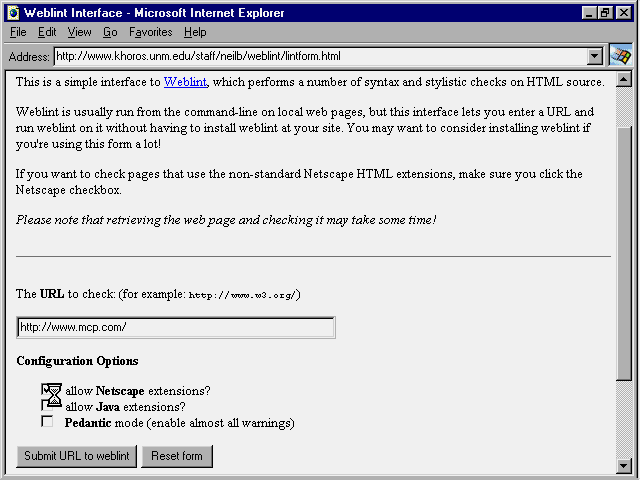{kind=link}
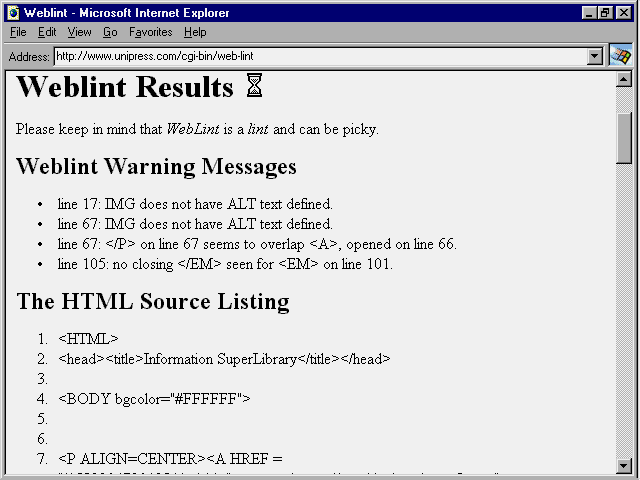{kind=link}
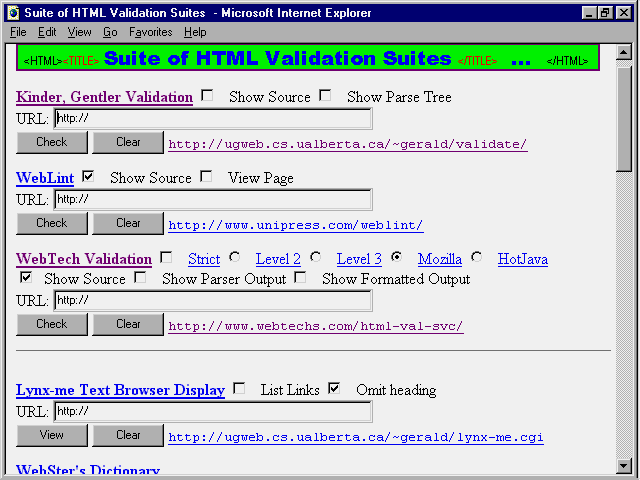{kind=link}
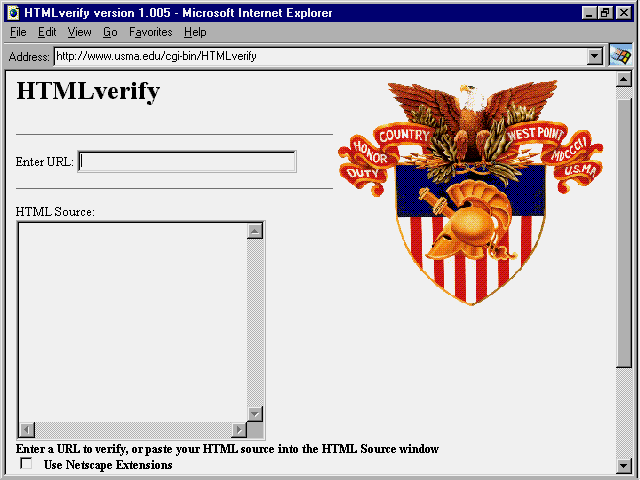{kind=link}
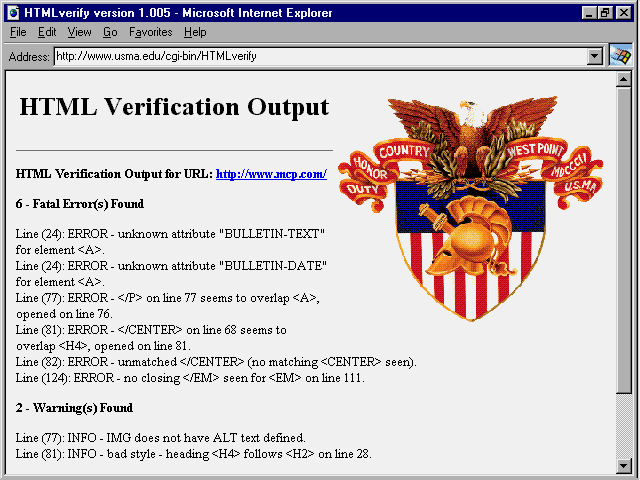{kind=link}