 Firewalls: In and Out of the Net
Firewalls: In and Out of the Net

In this chapter, we consider how Java security can be affected when firewall systems are used on the network.
 What Is a
Firewall?
What Is a
Firewall?
By "firewall", we mean any computer system, network hardware or combination of them that links two or more networks, and enforces some access control policy between them. Thus one side of the network is protected from any dangers in the other part of the network, in an analogous way to the solid firewalls in buildings, which prevent a fire spreading from one part of the building to another.

A Firewall
Until recent years, very few organizations thought seriously about the need for firewalls, despite the efforts of firewall vendors. Some well-publicized security breaches, when the content of several public web sites were vandalized, proved to be an ideal marketing opportunity. Almost any type of access control system was called a "firewall." The National Computer Security Association ( NCSA) has subsequently created standard tests to enforce minimum standards for a firewall, but that has not stopped some vendors from using the term creatively.
To add to the complexity, sometimes a single hardware system is called a firewall, while other times a complex collection of multiple routers and servers implement the firewall function. But we only need to be concerned with the policies enforced by the firewall, and what the effect is on the data traffic.
What Does a Firewall Do?
Firewalls can have an effect on any type of network traffic, depending on their configuration. The areas we are especially concerned with are the loading of Java applets to a client from a server, and network accesses by Java applets to a server. Firewalls may be present at the client network, the server network, or both. In order to understand the implications, we shall need to understand the basic functions provided by a firewall.
If you have seen any literature on firewalls, you will be well aware that there are many buzzwords used by firewall specialists, to describe the different software techniques that can be used to create them. Current techniques include packet filtering, application gateways , proxy servers, dynamic filters, bastion hosts, demilitarized zones, and dual-homed gateways. Luckily, for the purpose of this book, we can ignore the details of the software technologies, and simply concentrate on what a firewall does with data packets flowing "through" it.
There are several other functions of firewalls which have no real affect on Java security; for example, logging, reporting and management functions will be required, and these may themselves be written in Java. As an example, the IBM Firewall has a graphical user interface using Java.
The basic security functions of any firewall are to examine data packets sent "through" the firewall, and to accept, reject or modify the packets according to the security policy requirements. Most of today's firewalls only work with TCP/IP data, so it is worth seeing what is inside a TCP/IP data packet, in order to understand the firewall's actions.
Inside a TCP/IP Packet
All network traffic exchange is performed by sending blocks of data between two connected systems. The blocks of data will be encapsulated within a data packet, by adding header fields to control what happens to the data block en route and when it reaches its final destination. Network architectures are constructed of layers of function, each built on the services of the layer beneath it. The most thorough layered architecture is the Open Systems Interconnection ( OSI) model, whereas other architectures, such as TCP/IP use broader layer definitions. On the wire, these layers are translated into a series of headers prepended to the data being sent (see See Mapping the Layered Network Model to Packet Headers ).
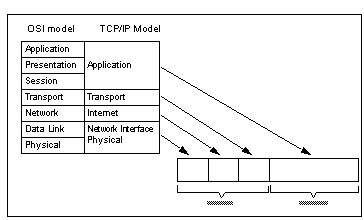
Mapping the Layered Network Model to Packet Headers
The first part of the header, the Data Link/Physical header, is determined by the type of network. Ethernet, token-ring, serial lines, FDDI, and so on, each have their own headers, containing synchronization, start-of-packet identifiers, access control, and physical (MAC) addresses as required by the network type. There may be fields to distinguish Internet Protocol (IP) packets from other types of packets, such as NetBIOS or SNA. We only need to consider IP packets here.
The next part of the header of IP packets is the standard Internet Protocol header, which specifies the originator (source) address and the intended recipient (destination) address, together with fields to control how the packet is forwarded through the Internet. There are two main types of IP headers: the common IPv4 standard, and the new IPv6 standard, which is intended to replace IPv4.
This is followed by the transport layer header, which controls what happens to the packet when it reaches its destination. Almost all the user-level protocols commonly referred to as "TCP/IP" use either a TCP (Transmission Control Protocol) or a UDP (User Datagram Protocol) header at the transport layer.
Finally, application protocol headers and data are contained in the payload portion of the packet, and are passed from the sending process to the receiving process.
Each of these packet headers contain a number of data fields, which may be examined by a firewall, and used to decide whether to accept or reject the data packet.
Each header has a number of data fields. For current purposes, the most important ones are:
Source IP address a 32-bit address (IPv4) or a 128-bit address (IPv6)
Destination IP address a 32-bit address (IPv4) or a 128-bit address (IPv6)
Source port number a 16-bit value
Destination port number a 16-bit value
The source and destination IP addresses identify the machines at each end of the connection, and are used by intermediate machines to route the packet through the network. Strictly speaking, an IP address identifies a physical or logical network interface on the machine, which allows a single machine to have several IP addresses.
The source and destination port numbers are used by the TCP/IP networking software at each end, to send the packets to the appropriate program running on the machines. Standard port numbers are defined for the common network services; for example, an FTP server expects to receive TCP requests addressed to port 21, and an HTTP Web server expects to receive TCP requests to port 80.
However, non-standard ports may be used. It is quite possible to put a Web server on port 21, and access it with an URL of http://server:21/. Because of this possibility, some firewall systems will examine the inside details of the protocol data, not just headers, to ensure that only valid data can flow through.
As an elementary security precaution, port numbers less than 1024 are "privileged" ports. On some systems, such as UNIX, programs are prevented from listening to these ports, unless they have the appropriate privileges. On less secure operating systems, a program can listen on any port, although it may require extra code to be written. HTTP Web servers, in particular, are often run on non-standard ports such as 8000 or 8080 to avoid using the privileged standard port 80.
The non-privileged ports of 1024 and above can be used by any program; when a connection is created, a free port number will be allocated to the program. For example, a Web browser opening a connection to a web server might be allocated port 1044 to communicate with server port 80. But what happens, you may ask, if a Web browser from another client also gets allocated port 1044? The two connections are distinguished by looking at all four values (source IP address, source port, destination IP address, destination port), as this group of values is guaranteed to be unique by the TCP standards.
How Can Programs Communicate through a Firewall?
Simple packet-filtering firewalls use the source and destination IP addresses and ports to determine whether packets may pass through the firewall. Packets going to a Web server on destination port 80, and the replies on source port 80, may be permitted, while packets to other port numbers might be rejected by the firewall. This may be allowed in one direction only and it may be further restricted by only allowing packets to and from a particular group of Web servers (see See Asymmetric Firewall Behavior ).

Asymmetric Firewall Behavior
There may be more than one firewall through which data needs to pass. Users in a corporate network will often have a firewall between them and the Internet, in order to protect the entire corporate network. And at the other end of the connection, the remote server will often have a firewall to protect it and its networks.
These firewalls may enforce different rules on what types of data are allowed to flow through, which can have consequences for Java (or any other) programs. It is not uncommon to find Java-enabled Web pages that work over a home Internet connection, simply fail to run on a corporate network.
There are two problem areas: can the Java program be downloaded from a remote server, and can it create the network connections that it requires?
The HTTP protocol is normally used for downloading. In order to understand the restrictions that firewalls put on HTTP, especially with regard to proxy servers and SOCKS servers (discussed in See Proxy Servers and SOCKS ), we describe this protocol in detail in the next section.
Detailed Example of
TCP/IP Protocol
Let us consider the simple case of a browser requesting a Web page using HTTP. There are two steps to this: first the browser must translate a host name (for example, www.ibm.com) into its IP address (204.146.17.33 in this case). The normal way to do this in the Internet is to use the domain name service ( DNS). The second step is when the browser sends the HTTP request and receives a page of HTML in response.
DNS Flow (UDP Example)
DNS uses the UDP protocol at the transport layer, sending application data to the Domain Name Service (udp/53) port of a nameserver. The packet header for UDP is shown in See IP V4 and UDP Headers )
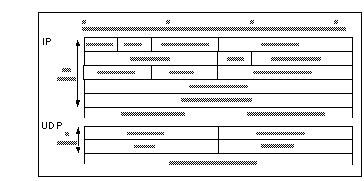
IP V4 and UDP Headers
If the newer IPv6 is used, the header is simpler, but with 128-bit long addresses, instead of 32-bit.
Now for the actual DNS request. It is a simple request and response sequence (see See Client Requests Name Resolution and See DNS Name Resolution Response ).


HTTP Flow (TCP Example)
Now the client can request the URL of
http://www.ibm.com/example1.html, because it knows the real IP address of www.ibm.com (204.146.17.33). Requests such as this use TCP at the transport layer, to carry the HTTP application data. HTTP is a very simple protocol, where the client requests a particular item of data from the server, and the server returns the item, preceded by a short descriptive header.
TCP headers are similar to UDP, but have more control fields to provide a guaranteed 1 delivery service:



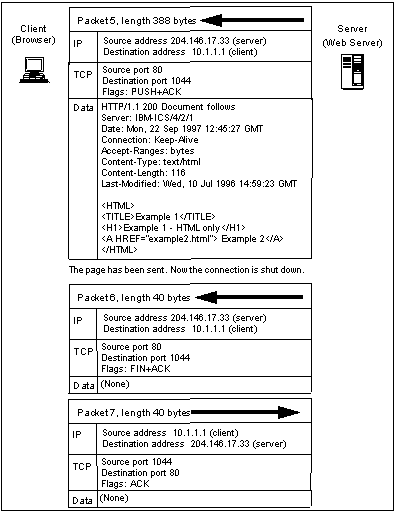
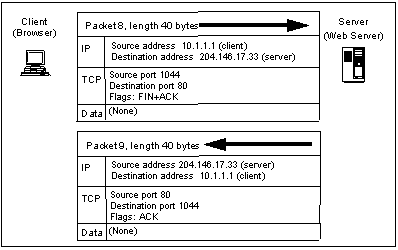
Web Page Request (4 of 4)
- Packets 1, 2 and 3 establish the TCP connection with a " three-way handshake."
- Packet 4 contains the HTTP request from the browser; you can see the GET request itself, together with other data being passed to the server.
- Packet 5 contains the reply from the server, with the page data preceded by page information. You can see this information using "view document source" and "view document info" from a Web browser. Larger replies would need to be sent in more than one packet, and the client would periodically send TCP acknowledgment packets back to the server. But only a single item of data is returned, so that the page data, images, applets and other components are returned separately. Using JAR files, several items can now be sent in a single TCP connection, which is more efficient.
- Packets 6 and 7 close the connection from the server end, and packets 8 and 9 close it from the client.
Although at first sight this seems quite complicated, on closer inspection it can be seen to be simply sending a request (in readable ASCII text) and receiving a reply, surrounded by packets to open and close the TCP connection.
Proxy Servers and SOCKS
Proxy Servers and SOCKS Gateways are two common approaches used to provide Internet access through corporate firewalls. The primary goal is to allow people within the company network the ability to access the world-wide Internet, but prevent people from outside from accessing the company internal networks.
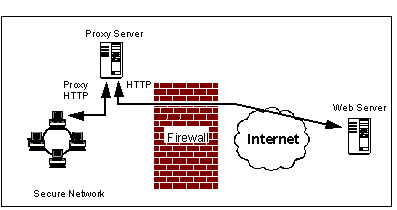
Proxy Servers
A proxy server's function is to receive a request from a web browser, to perform that request (possibly after authorization checks), and return the results to the browser.
What actually happens is that, instead of sending a request directly to server www.company.com of:
a browser will send a request to proxy.mycompany.com, asking:
GET http://www.company.com/page.html
proxy.mycompany.com will then contact www.company.com with the request
There are several advantages to this indirect approach:
- All external web access can be forced to go through the proxy server, so creating a single control point. This is achieved by blocking all HTTP protocol data, except for that from the proxy server itself.
- All pages being transferred can be logged, together with the address of the requesting machine.
- Requests for certain sites can be restricted or banned.
- The IP addresses or names of the internal systems never appear on the Internet, just the address of the proxy server. So attackers cannot use the addresses to gain information about your internal system names and network structure.
- The proxy can be configured as a caching proxy server, and will save local copies of Web pages retrieved. Subsequent requests will return the cached copies, thus providing faster access and reducing the load on the connection to the Internet.
- Web proxy servers usually support several protocols, including HTTP, FTP, Gopher, HTTPS (HTTP wit h SSL), a nd WAIS.
- Proxy servers can themselves use the SOCKS protocol to provide additional security. This does not affect the browser configuration.
The disadvantages are that browser configuration is more complex, the added data transfers can add an extra delay to page access, and sometimes proxies impose additional restrictions such as a time-out on the length of a connection, preventing very large downloads.
What Is SOCKS?
The SOCKS protocol is mentioned several times in this section. It is a simple but elegant way of allowing users within a corporate firewall to access almost any TCP service outside the firewall, but without allowing outsiders to get back inside.
It works through a new TCP protocol, SOCKS, together with a SOCKS server program running in the firewall system. (SOCKS, incidentally, is a shortened version of "sockets," the term used for the data structures which describe a TCP connection.)
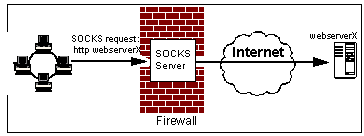
A SOCKS Connection
In basic terms, SOCKS is a means of encapsulating any TCP protocol within the SOCKS protocol. On the client system, within the corporate network, the data packets to be sent to or from an external system will be put inside a SOCKS packet and sent to a SOCKS server. For example, a request for http://server.company.com/page.html would, if sent directly, be contained in a packet with the following characteristics:
Destination address: server.company.com
If SOCKS were used, the packet sent would be (effectively):
Destination address: socks_server.mycompany.com
Destination port: TCP 1080 (SOCKS)
Data: Destination address = server.company.com,
Destination port = TCP 80 (HTTP),
When the SOCKS server receives this, it extracts the required destination address, port and data and sends this packet; naturally, the source IP address will be that of the SOCKS server itself. The firewall will have been configured to allow these packets from the SOCKS server program, so they won't be blocked. Returning packets will be sent to the SOCKS server, which will encapsulate them similarly, and pass on to the original client, which in turn strips off the SOCKS encapsulation, giving the required data.
(This description is simplified; in reality, requests between the client and the SOCKS server are in a socket API format, rather than the pure protocol data as shown above. Details!)
The advantage of all this is that the firewall can be very simply configured, to allow any TCP/IP connection on any port, from the SOCKS server to the non-secure Internet, trusting it to disallow any connections which are initiated from the Internet.

SOCKS Flexibility
The disadvantage is that the client software must be modified to use SOCKS. The original approach was to recompile the network client code with a new SOCKS header file, which translated TCP system calls (connect, getsockname, bind, accept, listen, select) into new names (Rconnect, Rgetsockname, Rbind, Raccept, Rlisten, Rselect). When linked with the libsocks library, these new names will access the SOCKS version, rather than the standard system version. This, therefore, creates a new " SOCKSified" version of the client software.
This approach is still used for clients running on UNIX. However, a new approach has become available for OS/2 and Windows operating systems, where the dynamically linked libraries which implement the TCP calls above are replaced by a SOCKSified version, usually termed a " SOCKSified TCP stack." This SOCKSified stack can then be used with any client code, without the need to modify the client. It just requires the SOCKS configuration to be specified, giving the address of the SOCKS server, and information on whether to use SOCKS protocol or to make a direct connection.
The SOCKSified stack comes as standard with OS/2 Warp Version 4 (add-on versions have been produced for OS/2 Warp Version 3), or can be purchased for Windows 95 or Windows NT.
Using Proxy Servers or SOCKS Gateways
We have described three options:
- Using a proxy server
- Using a SOCKS gateway with a "SOCKSified" client application
- Using a SOCKS gateway with a "SOCKSified" TCP/IP stack
Each of these options has its own advantages and disadvantages, for the company network security manager to evaluate for the company's particular environment. But what does the end user need to do to use these options?
Both Netscape Navigator and Microsoft Internet Explorer Web browsers have built-in support for both proxy servers and for the SOCKS protocol. Options are provided to select either a proxy server, or a SOCKS server (don't select both, or requests will be sent via the SOCKS server to the proxy server, causing unnecessary network traffic). But currently, support for SOCKS is limited to specifying the server name; all page requests will be passed to that server, whether or not direct access is possible (as in the case of internal Web servers).
The advantage in using the SOCKSified stack is that it provides better support for deciding whether to use SOCKS or not, rather than sending all requests to the SOCKS server (which may overload it), as well as supporting other clients. This is controlled by a configuration file, which specifies which range of addresses are internal and can be handled directly, and which must go through the SOCKS server. Of course, if you use a SOCKSified stack, you should not enable SOCKS in the browser configuration. Then again, a SOCKSified stack is not available for all platforms, so you may be forced to use the browser's SOCKS configuration.
The SOCKsified stack approach will also work with Java applets run from a Web browser, as the normal Java.net classes will use the underlying TCP protocol stack, so this provides a simple way of running Java applets through a SOCKS server through a firewall. But if a SOCKSified stack is not available, you will need to SOCKSify the library classes yourself, if you have source code, or look for a vendor who supports SOCKS.
The Effect of
Firewalls on Java
We now consider the effect of firewalls on Java applets, first from the point of view of loading them, then on the network connections that the applets themselves may create.
Downloading an Applet Using HTTP
Java applets within a Web page are transferred using HTTP, when the browser fetches the class files referred to by the <APPLET> tag. So, if a Web page contains a tag of:
<APPLET code="Example.class" width=300 height=300>
<PARAM NAME=pname VALUE="example1">
the browser would transfer the Web page itself first, then the file example.class, then any class files referred to in example.class. Each HTTP transfer would be performed separately (unless HTTP 1.1 is used).
JDK 1.1 allows a more efficient transfer, where all the classes are combined into a compressed Java Archive (JAR) file. In this case the Web page contains a tag of:
<APPLET archive="example.jar" code="Example.class" width=300 height=300>
If there are problems finding example.jar, or if an older browser (Java 1.0) is used, the archive option is ignored, and the code option is used instead as in the previous example.
Stopping Java Downloads with a Firewall
But what effect do firewalls have on the downloading of Java class files? If the security policy is to allow HTTP traffic to flow through the firewall, then Java applets and JAR files will simply be treated like any other component of a Web page, and transferred. On the other hand, if HTTP is prohibited, then it is going to be very difficult to obtain the applet class files, unless there is another way of getting them, such as using FTP. Quite frequently, Web servers using non-standard TCP ports such as 81, 8000, 8080 may be blocked by the firewall, so if you are running a Web server, stick to the standard port 80 if you want as many people as possible to see your Web pages and applets.
Now since Java is transferred using HTTP, the IP and TCP headers are indistinguishable from any other element of a Web page. Simple packet filtering based on IP addresses and port numbers will therefore not be able to block just Java. If you require more selective filtering, you will need to go one step beyond basic packet filtering and examine the packet payload: the HTTP data itself. This can be done with a suitable Web proxy server or an HTTP gateway which scans the data transferred.
If a Web proxy server is used, a common arrangement is to force all clients to go through the proxy server (inside the firewall), by preventing all HTTP access through the firewall, unless it came from the proxy server itself. If you don't have an arrangement like this, a user could bypass the checking by connecting directly.
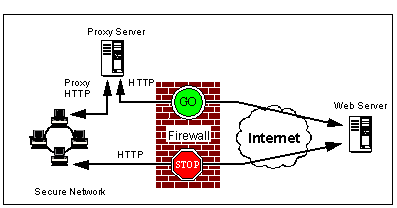
Forcing Connections through a Proxy
So what can we look for, inside the HTTP packet, to identify a Java class file? In an ideal world, there would be a standard MIME ( Multipurpose Internet Mail Extensions) data type for Java classes, so that a Web browser might request:
Accept: application/java, application/jar
and firewalls could quite easily check for these requests and the Web server "Content-Type:" replies.
However, in practice servers respond with a variety of MIME types, such as:
application/octet-stream (for class files)
multipart/x-zip (for JAR files)
This means it is necessary to examine the actual data being transferred, to see if it might be Java bytecode or JAR files. Bytecode files must start with hexadecimal values " CAFEBABE" in the first four bytes (see See Java Bytecode ). This string will also be found in JAR files, but as a JAR file may be compressed, a scanner has to work harder to find the signature. Commercial products are available which can perform this inspection. They usually work as, or with, an HTTP proxy server, and check all HTTP requests passing through.
Searching for the class file signature in this way is an effective way to stop Java, but it indiscriminately chops out good code and bad. A more subtle scanner could extend the principle to other types of "signature". For example, it would theoretically be possible to filter out any applet that overrode the stop() method (see See Malicious Applets ), by analyzing the bytecode in detail.
Of course, in these restrictive environments, you would also want to filter out any other types of executable content which are less secure than Java, such as ActiveX, and maybe JavaScript, .EXE files, and so on. You would also have to consider other protocols such as FTP, HTTP or FTP encapsulated in SOCKS, HTTP encapsulated in SSL (which adds the problem of decoding the type of encrypted data).
We have been focussing on scanning for Java at a single point for the enterprise: the firewall or proxy server. Recent developments by the browser manufacturers and by systems management specialists, such as Tivoli Systems, point to an alternative strategy. They have developed mechanisms for installing and configuring browsers on multiple user systems from a single point. This certainly offers cost savings: a single administrator can be responsible for hundreds of workstations. However, as a security measure it can only work if it is backed up by controls and monitors that prevent individual users from overriding the "official" configuration.
The cleanest solution to the problem of selectively stopping Java is in the use of signed applets. As certificates become used more frequently, it will be possible to permit Java bytecode from sites where you trust the signer (maybe your own company sites), and disallow other sites.

Java Network Connections through the Firewall
When a Java applet or application wishes to create its own network connections through a firewall, it faces all the difficulties above, and also, for applets, the default security manager restriction of only being able to contact the server it was downloaded from.
There are three approaches that an applet can take:
- Use the URL classes from the java.net package to request data from a Web server using HTTP. JDK 1.1 adds a new class to this package - HttpURLConnection - as a specialization of the URLConnection class.
- Use other classes from the java.net package to create socket connections to a dedicated server application.
- Use remote object access mechanisms, such as RMI or CORBA.
The first of these is the easiest to implement (look at the never-ending fortune cookie applet in See Never Ending Fortune Cookie Applet (Part 1 of 2) for an example). It is also likely to be the most reliable, because the JVM passes the URL request to the normal browser connection routines to process. This means that, if a proxy is defined, the Java code will automatically use it. However, URL connections suffer from the fact that the server side of the connection has limited capability; it can only be a simple file retrieval or a CGI (or similar) program.
For the second approach - socket connection to the server - the applet will need to choose a port number to connect to, but many will not be allowed through firewall. Some types of applets have no real choice as to port number. For example IBM Host-on-Demand is a Java applet which is a 3270 terminal emulator, hence needs to use the tn3270 protocol to telnet port 23. It is quite likely that this standard port would be allowed through the firewall; otherwise, encapsulation of tn3270 inside the SOCKS protocol may be the only answer.
Other applets need to make a connection to the server, but don't need any special port. It may be that they can use a non-privileged server port of 1024 or greater, but often these, too, are blocked by simple packet filtering firewalls. A flexible approach is to let the applet be configurable to allow direct connections (if allowed), otherwise to use the SOCKS protocol to pass through the firewall.

Many HTTP proxy servers implement the Connect Method . This allows a client to send an HTTP request to the proxy which includes a header telling it to connect to a specific port on the real target system. The connect method was originally developed to allow SSL connections to be handled by a proxy server, but it has since been extended to other applications. For example, Lotus Notes servers can use it. The connect method operates in a very similar way to SOCKS and you can implement Java applet connections with it in much the same way as you would with SOCKS.
Another approach is to disguise the packets in another protocol, most likely HTTP, as this will have been allowed through the firewall. This will allow two-way transfer of data between applet and server, but will require a special type of Web server. The server will need to act as a normal Web server, to supply the Web pages and applets in the first place, but must be able to communicate with the applets to process their disguised network traffic.
RMI Remote Method Invocation
Java's RMI allows developers to distribute Java objects seamlessly across the Internet. But RMI needs to be able to cross firewalls too.
The normal approach that RMI uses, in the absence of firewalls, is that the client applet will attempt to open a direct network connection to the RMI port (default is port 1099) on the server. The client will send its request to the server, and receive its reply, over this network connection.
The designers of RMI have made provision for two firewall scenarios, both using RMI calls embedded in HTTP requests, under the reasonable assumption that HTTP will be allowed through the firewall (as the applet was delivered that way). The RMI server itself will accept either type of request, and format its reply accordingly. The client actually sends an HTTP POST request, with the RMI call data sent as the body of the POST request, and the server returns the result in the body of an HTTP response.

Proxy Configuration for RMI (1)
In the first scenario, we assume that the proxy server is permitted by the firewall to connect directly to the remote server's RMI port (1099). The client applet will make an HTTP POST request to http://rmi.server:1099/. This passes across the Internet to the remote server, where it is found to be an encapsulated RMI call. Therefore the reply is sent back as an HTML response. In theory this method could also be used with a SOCKS server, instead of a proxy server, if run by a SOCKS-enabled browser.
As well as assuming that the firewall on the client passes the RMI port, this assumes that the remote firewall also accepts incoming requests directly to the RMI port. But in some organizations, the firewall manager may be reluctant to permit traffic to additional ports such as the RMI port. So an alternative configuration is available, in case RMI data is blocked by either firewall.
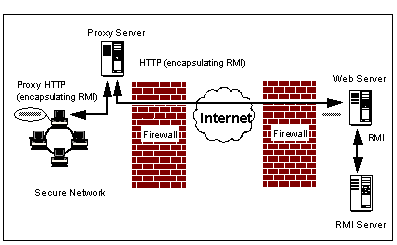
Proxy Configuration for RMI (2)
In the second scenario, the proxy server cannot use the RMI port directly, so the remote Web server (which supplied the applet) has a cgi-bin program configured, to forward HTTP on the normal port (80) into HTTP to the RMI server's port 1099. An example cgi-bin program is provided in the development kit, and needs to be installed on the Web server. This cgi-bin program invokes the Java interpreter on the server, to forward the request to the appropriate RMI server port. It also copies the standard CGI environment variables to Java properties.
So, the client code sends a POST request to http://rmi.server/cgi-bin/java-rmi.cgi?forward=1099. The cgi-bin program passes it on to the RMI port specified in the ?forward parameter. The reply will be passed back to the Web server, which adds the HTML header line, and returns the response to the client. In principle, this would allow the RMI server to reside on a different system than the remote Web server, in a three-tier model.
Fortunately, all the work above is performed automatically in the java.rmi package, so the software developer need not be concerned about the detailed mechanism. It is only necessary to configure the RMI server correctly, and to ensure the client uses the automatic mechanism for encapsulating RMI.
In the current version of RMI, the client stub code checks for the presence (not value) of system properties proxyHost or http.proxyHost, in order to decide whether to try using the HTTP encapsulation. If you are using a Web browser and encapsulated RMI does not seem to work, try explicitly setting these properties, as the browser may be using its own proxy HTTP, without setting proxyHost.
All this automatic encapsulation is not free, of course. Encapsulated RMI calls are at least an order of magnitude slower than direct requests, and proxy servers may add extra delays to the process as they receive and forward requests.
Summary
We've shown how firewalls provide added security to an organization's network, at the expense of some restrictions on what client users can do. Firewalls use a variety of techniques to provide this security, including packet filtering, proxy servers and SOCKS servers. We've described approaches which can be used with these techniques to allow secure access through the firewalls.