 Class of 1.1
Class of 1.1

In this chapter we will explore a number of topics:
- The relationship between Java class files and conventional object and executable files
- The threat presented by the class file format
- How bytecodes aid security
- Describe the contents of a Java class file
- Describe ways in which to reduce the threat of decompilation
 The Traditional Development Life Cycle
The Traditional Development Life Cycle
As you have seen earlier, Java is a compiled language. That is, source code is written in a high-level language and then converted through a process of compilation to a machine-level language, the Java bytecode, which then runs on the Java Virtual Machine. Before we look more closely at Java bytecode, we'll quickly review the differences between high- and low-level languages, the compilation process and runtime behavior of a more traditional environment.
On the PC, program files are recognized in two ways. The first is by the file extension (.EXE, .COM) and the second is by the file format itself. Executable files contain some information in a header which informs the operating system that this file is a program and has certain requirements in order to run. These requirements include such things as the address at which the program should be loaded, other supporting files which will be required and so on.
When DOS or Windows attempts to run a program file, it loads the file and ensures that the header is legitimate, that is, that it describes a real program. The header also indicates where the starting point of the program itself is. The program is stored in the program file as machine code instructions. These instructions are numeric values which are read and interpreted by the processor as it executes. Having validated the header, the operating system starts executing the code at this address.
From the above description, it should be clear that anyone with a good understanding of the header format and of the machine code for a particular operating system could construct a program file using little more than an editor capable of producing binary files. (Such an individual would be well advised to seek urgent medical attention.)
Of course this is not how programs are produced. The closest that anyone gets to this is writing assembly code. Assembly language programming is very low level. Its statements, after macro expansion, usually translate into one or at most two machine language instructions. The assembly source code is then fed through an assembler which converts the (almost) human readable code into machine code, generates the appropriate header and finally outputs an executable file.
Most programs, however, are written in a high-level language such as C, C++, COBOL and so forth. Here it is the task of the compiler to translate high-level instructions into low-level machine code in the most optimal way. The resultant machine code output is generally very efficient, although - depending on the compiler - it may be possible to write more efficient assembler language. Because different compilers manage the translation and optimization process in different ways, they will produce different output for the same source code. In general it is true to say that the higher level the source language, the more scope there is for variation in the resultant executable file since there will be more than one possible translation of each high-level statement into low-level machine code.
During the compilation process, high-level features such as variable and function names are replaced by references to addresses in memory and by machine code instructions, which cause the appropriate address to be accessed (in the case of variables) or jumped to (in the case of functions).
In the case of both assembly language and high-level language programming, the output of the assembly or compilation phase is generally not immediately executable. Instead, an intermediate file (known as an object module or object file 1 ) is produced. One object file is produced for each source file compiled, regardless of the content or structure of the source code. These object modules are then combined using a tool called a linker which is responsible for producing the final executable file (or shared library). The linker ensures that references to a function or variable in one object module from another object module are correctly resolved.
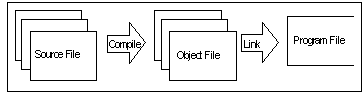
Program Compilation and Linking
- An object file contains the machine code which is the actual program plus some additional information describing any dependencies on other object files.
- An executable file is a collection of object files with all inter-file dependencies resolved, together with some header information which identifies the file as executable.
The Java Development Life Cycle
Moving back to the world of Java, we see that it is a high-level programming language and that bytecode is the low-level machine language of the Java Virtual Machine. Java is an object-oriented language; that is, it deals primarily with objects and their interrelationships. Objects are best thought of in this context as a collection of data (fields in Java parlance) and the functions (methods) which operate on that data. Objects are created at runtime based on templates (classes) defined by the programmer.
A Java source file may contain definitions for one or more classes. During compilation each of these classes results in the generation of a single class file. In some respects, the class file is the Java equivalent of an object module rather than an executable program file; that is, it contains compiled machine code, but may also contain references to methods and fields which exist in other classes and hence in other class files.
Class files are the last stage of the development process in Java. There is no separate link phase as linking is performed at runtime by the Java Virtual Machine. If a reference is found within one class file to another, then the JVM loads the referenced class file and resolves the references as needed.
The astute reader will deduce that this demand loading and linking requires the class file to contain information about other class files, methods and fields which it references, and in particular, the names of these files, fields and methods. This is in fact the case as we shall see in the next section.
Even more astute readers may be pondering some of the following questions.
- Is it possible to compile Java source code to some machine language other than that of the JVM?
- Is it possible to compile some other high-level language to bytecode for the JVM?
- Is there such a thing as an assembler for Java?
- What is the relationship between the Java language and bytecode?
The simple answer to the first three questions is yes.
It is possible with the appropriate compiler (generally referred to as a native code compiler) to translate Java source code to any other low- level machine code, although this rather defeats the "write once run anywhere" proposition for Java programs since the resultant executable program will only run on the platform for which it has been compiled.
It is also possible to compile other high-level languages into Java bytecode, possibly via an interim step in which the source code is translated into Java source code which is in turn compiled. Bytecode compilers already exist for Ada, COBOL, BASIC and NetREXX (a dialect of the popular REXX programming language).
Finally, Jasmin is a freely available Java assembler which allows serious geeks to write Java code at a level one step removed from bytecode.
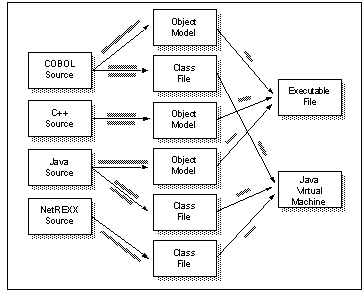
The Java Class File Format
The class file contains a lot more information than its cousin, the executable file. Of course, it still contains the same type of information, program requirements, an identifier indicating that this is a program and executable code (bytecode) but it also contains some very rich information about the original source code.
The high level structure of a class file is shown in See Class File Contents .
Class File Contents
Much here is as we would expect. There is information to identify the file as a Java class file, as well as the virtual machine on which it was compiled to run. In addition, there is information describing the dependencies of this class in terms of classes, interfaces (a special type of Java class file), fields, and methods. There is much more information than this however, buried within the constant pool: information which includes variable and method names within both this class file and those on which it depends.
In addition to managing dynamic linking, the JVM must also ensure that class files contain only legal bytecode and do not attempt to subvert the runtime environment, and to do this, still more information is required in the class. More details of how this works are in See The Class Loader and Class File Verifier .
The main thing to understand at this point is that the inclusion of all of this information makes the job of a hacker much simpler in many ways.
Decompilation Attacks
One of the areas seldom discussed when considering security implications of deploying Java is that of securing Java assets. Often considerable effort is put into developing software and the resultant intellectual property can be very valuable to a company.
Hackers are a clever (if misguided) bunch and there are many reasons why they might want to get "inside" your code. Here are a few:
- To steal a valuable algorithm for use in their own code
- To understand how a security function works to enable them to bypass it
- To extract confidential information (such as hard-coded passwords and keys)
- To enable them to alter the code so that it behaves in a malicious way (such as installing Trojan horses or viruses)
- To demonstrate their prowess
- For their entertainment (much as other people might solve crosswords)
The chief tool in the arsenal of the hacker in these cases is the decompiler. A decompiler, as its name suggests, undoes the work performed by a compiler. That is, it takes an executable file and attempts to re-create the original source code.
Advances in compiler technology now make it effectively impossible to go from machine code to a high-level language such as C. Modern compilers remove all variable and function names, move code about to optimize its execution profile and, as was discussed previously, there are many possible ways to translate a high-level statement into a low- level machine code representation. For a decompiler to produce the original source code is impossible without a lot of additional information which simply isn't shipped in an executable file.
It is, however, very easy to recover an assembly language version of the program. On the other hand, the amount of effort required to actually understand what such a program is doing makes it far less worthwhile to the hacker to do. (Nevertheless, it is done. Much pirated software is distributed in a "cracked" format, that is, with software protection disabled or removed.) So, it is fair to say that it is impossible to completely protect any program from tampering.
When JDK 1.02 was shipped, a decompiler named Mocha was quickly available which performed excellently. It was able to recover Java source code from a class file. It was so successful that at least one person used it as a way of formatting his source code! In fact the only information lost in the compilation process and unrecoverable using Mocha are the comments. If meaningful variable names are used (such as "accountNumber", or "password") then it is readily possible to understand the function of the code, even without the comments.
The current version of Mocha is unable to decompile Java 1.1 class files but this is not because the class files contain any less information, merely because the format has changed slightly. It is only a matter of time before a functional decompiler for Java 1.1 class files is developed.

The
Constant Pool
We said earlier that the constant pool contained a great deal of information. In fact it contains a strange mixture of items. The constant pool combines the function of a symbol table for linking purposes as well as a repository for constant values and string literals present in the source code. It may be considered as an array of heterogeneous data types which are referenced by index number from other sections of the class file such as the Field and Method sections. In addition, many Java bytecode instructions take as arguments numbers which are in turn used as indexes into the constant pool. See Constant Pool Entry Types shows the types of entries in the constant pool, as defined by the current JVM.
Constant Pool Entry Types
|
String in UTF8 format (a shorthand for writing Unicode strings) |
||
|
Reference to a ClassRef for the class in which the field occurs and a NameAndType for this field |
||
|
Reference to a ClassRef for the class in which the method occurs and a NameAndType for this method |
||
|
Reference to a ClassRef for the interface in which the field occurs and a NameAndType for this method |
||
|
Shorthand representation of a field or method signature and name |
Reference to a UTF8 representation of the name and another to the signature 2 |
As an example of a constant pool, let's take a look at the PointlessButton example we met earlier. See Constant Pool Example shows a dump of the constant pool for the PointlessButton class. The information in this table was generated using the DumpConstantPool application, which is on the CD accompanying this book.
Constant Pool Example
The full table has 83 entries, not bad for such a simple program. Looking at this data you can see that there is a wealth of information here. As an example of how a method is represented, let's look at entry number 56. This is a MethodRef entry and as such it has two further references to track down. The first is the Class entry, (4) which in turn references a UTF8 entry (3) for the class name: java.applet.Applet.
The second is the NameAndType entry, which surprisingly enough identifies the method name and the type of the method. The NameAndType entry (55) references a UTF8 entry (25) for the method name: <init>, and another UTF8 entry (54) for the type: ()V.
The name used here is a little special; <init> is not a valid name in itself, but it is used by the JVM to represent a constructor for a class. The type entry ()V indicates a method which takes no parameters (empty parentheses) and returns no value (V following the parentheses indicates a return type of void - Java's term for no value).
From this little jaunt through the constant pool we see that the pointlessButton class calls the java.applet.Applet default constructor. Following a similar process, we can identify all of the other fields and methods utilized in this class. Furthermore, by finding where entry number 56 is referenced in the bytecode, we can build a clear picture of what this code does.
This is precisely what the javap utility shipped with the JDK does. By examining the constant pool and other parts of the class file structure, it is able to produce a high-level picture of the class file. Here's the output of javap when run against pointlessButton:
Compiled from PointlessButton.java
public class PointlessButton extends java.applet.Applet implements java.awt.event.ActionListener
jamjar.examples.Button donowt;
public void actionPerformed(java.awt.event.ActionEvent);
As we already knew, pointlessButton extends java.applet.Applet and as such it must call the Applet constructor - the method reference we saw by tracing through the constant pool.
If this were all that javap did then it would still be a useful tool for examining class files for which we didn't have the source code in an attempt to reuse them or work out what they were doing. But it's not all. By using additional option switches it is possible to get richer information, including even the disassembled bytecode. The following is the result of running javap with the c (disassemble) and p (include private fields) options enabled.
Compiled from PointlessButton.java
public class PointlessButton extends java.applet.Applet implements java.awt.event.ActionListener
jamjar.examples.Button donowt;
public void actionPerformed(java.awt.event.ActionEvent);
Method void actionPerformed(java.awt.event.ActionEvent)
1 getfield #14 <Field PointlessButton.donowt Ljamjar/examples/Button;>
4 new #16 <Class java.lang.StringBuffer>
8 ldc #18 <String "Did Nothing ">
10 invokestatic #24 <Method java.lang.String.valueOf(Ljava/lang/Object;)Ljava/lang/String;>
13 invokespecial #28 <Method java.lang.StringBuffer.<init>(Ljava/lang/String;)V>
18 getfield #30 <Field PointlessButton.count I>
24 putfield #30 <Field PointlessButton.count I>
27 invokevirtual #34 <Method java.lang.StringBuffer.append(I)Ljava/lang/StringBuffer;>
32 invokevirtual #39 <Method java.lang.StringBuffer.append(Ljava/lang/String;)Ljava/lang/StringBuffer;>
36 getfield #30 <Field PointlessButton.count I>
50 invokevirtual #39 <Method java.lang.StringBuffer.append(Ljava/lang/String;)Ljava/lang/StringBuffer;>
53 invokevirtual #47 <Method java.lang.StringBuffer.toString()Ljava/lang/String;>
56 invokevirtual #52 <Method java.awt.Button.setLabel(Ljava/lang/String;)V>
1 invokespecial #56 <Method java.applet.Applet.<init>()V>
5 new #58 <Class jamjar.examples.Button>
9 ldc #60 <String "Do Nothing">
11 invokespecial #61 <Method jamjar.examples.Button.<init>(Ljava/lang/String;)V>
14 putfield #14 <Field PointlessButton.donowt Ljamjar/examples/Button;>
19 putfield #30 <Field PointlessButton.count I>
1 new #64 <Class java.awt.BorderLayout>
5 invokespecial #65 <Method java.awt.BorderLayout.<init>()V>
8 invokevirtual #71 <Method java.awt.Container.setLayout(Ljava/awt/LayoutManager;)V>
15 getfield #14 <Field PointlessButton.donowt Ljamjar/examples/Button;>
18 invokevirtual #77 <Method java.awt.Container.add(Ljava/lang/String;Ljava/awt/Component;)Ljava/awt/Component;>
23 getfield #14 <Field PointlessButton.donowt Ljamjar/examples/Button;>
27 invokevirtual #81 <Method java.awt.Button.addActionListener(Ljava/awt/event/ActionListener;)V>
Here we have the complete code for all of the methods albeit in Java "assembly" language. By appropriate use of a binary editor it would be a relatively simple matter for a hacker to subvert the function of this code. For example, simply changing the value of String (3) "Did Nothing" in the constant pool we could cause the button to print a rude message when pressed. This is a trivial example but hopefully illustrates the vulnerability of class files.
Beating the Decompilation Threat
The very real threat of decompilation is not going to go away. Decompilers work by recognizing patterns in the generated bytecode which can be translated back into Java source code statements. The field and method names required to make this source code more readable are readily available in the constant pool as we have seen.
To date, there have been two main approaches to thwarting would-be decompilers, code obfuscation and bytecode hosing. 3
The principle of obscuring (or obfuscating) source code to make it more difficult to read is not new. In the UNIX world - where incompatibilities between platforms and implementations make it necessary to distribute many applications in source format - "shrouding" is common. This is the process of replacing variable names with meaningless symbols, removing comments and white space and generally leaving as little human readable content in the source code without impacting its compilability.
After the release of Mocha, the author released Crema, a further appalling coffee pun, which was designed to thwart Mocha. It did this by replacing names in the constant pool with illegal Java variable names and reserved words (such as "if" and "class"). This had no affect on the JVM, which merely used the names as tags to resolve references without attributing any meaning to them. Nor did it actually prevent decompilation. It did however mean that the decompiled code was more difficult to read and understand and also would not recompile as the Java compiler would object to the illegal names.
Bytecode hosing is more subtle and is aimed at preventing the decompiler from recognizing patterns within the bytecode from which it could recover valid source. It does this by breaking up recognizable patterns of bytecodes with "do nothing" instruction sequences (such as the NOP code or a PUSH followed by a POP). A good example of a bytecode hoser is HoseMocha.
Of course, this approach can be defeated since once a hacker has established what types of do-nothing sequences are being generated by a bytecode hoser, he or she can modify the behavior of the decompiler to ignore such sequences. Furthermore, attempts to decompile hosed bytecode will generally result in broadly readable code interspersed with unintelligible passages rather than completely unreadable code.
In addition to this, bytecode hosers present a more insidious problem to Java users. As we have already seen, the principal method of optimizing Java performance is in the JVM and in particular through the use of just in time (or JIT) compilation. And how do JITs work ? Yup, you guessed it, they recognize patterns in the generated bytecode which can be optimized into native code. Breaking up these patterns through the use of a bytecode hoser can seriously impact the performance of JIT compilers.
For this reason, it is safe to assume that Java compilers will not follow the same evolutionary path as their native compiler cousins in terms of generating wildly differing output for the same source code since this too would thwart JIT compilers.
This is a well understood dilemma in security circles, the trade off between security and performance/price/ease of use.
The only safe course of action is to assume that ALL Java code will at some point be decompiled.
For developers this means ensuring that no sensitive information is distributed in the class file either algorithmically or as hard-coded values. This can be accomplished by building client/server type applications with a Java presentation layer which can be run anywhere and a secured server side where sensitive information or algorithms can be stored. This may also involve extending the development and testing process to ensure that distributed Java code is "safe".
Finally you may decide that the existing method of protecting distributed code, that of legal sanction under copyright laws, is sufficient to deal with any serious threat to Java-based intellectual property...in which case we have some real estate you may be interested in buying.
Java Bytecode
In the next chapter we look at how the Java class loader and class file verifier provide a level of security against rogue class files. This section prepares us for that chapter by looking more closely at bytecode.
A Bytecode Example
Though you may not realize it, you have already seen an example of bytecode or at least the human readable format. The output generated by the javap command when we ran it with the -c flag contained a disassembly of each of the methods in the class file. The code snippet in See Decompiled Method (Part 1 of 2) was taken from the actionPerformed method of our pointlessButton class. It was compiled from three lines of Java source code:
public void actionPerformed(java.awt.event.ActionEvent e) {
donowt.setLabel( "Did Nothing " + ++count + " time" + ( count == 1? "": "s" ) );


Decompiled Method (Part 2 of 2)
Notice the #nn references in the bytecode such as instruction 30:
The #36 here refers to entry number 36 in the constant pool, the text after the #36 is a comment for the benefit of the reader showing that entry #36 in the constant pool is a String with value " times".
The next thing that you should notice about this code is that even at this level, there are still references made to Methods and Fields. From this you may infer that Java is object-oriented even at the bytecode level and you would be correct.
We are not going to analyze all of this code, there are other books which serve to teach bytecode. Instead we will compare this code fragment with 80x86 equivalent code and draw some conclusions about the measures that exist within bytecode itself to protect the JVM against subversion.
Let's look at the following fragment :
15 getfield #30 <Field pointlessButton.count I>
21 putfield #30 <Field pointlessButton.count I>
See Bytecode Byte-by-Byte explains what each of these instructions does.
Bytecode Byte-by-Byte
The net of this sequence of operations is to have incremented the count field of the current object by one and left a copy of it on the stack (for use in the next instruction which prints the count).
The equivalent 80x86 code looks like this:
MOV BX, thisPointlessButton ; Set BX to the base address of this button
MOV SI, count_field ; Set SI to the offset of the count in button class
MOV CX, [ BX + SI ] ; Get the count field in register CX
INC CX ; increment the CX register
MOV [ BX + SI ], CX ; Store the result in BX+SI (the count field)
There are a few differences here which we'll examine in turn.
The JVM has a stack-based architecture. This means that its instructions deal with pushing values onto, popping values from, and manipulating values on a stack.
The 80x86 processor range from Intel are register-based. They have a number of temporary storage areas (registers) some of which are general purpose, others of which have a particular function.
The advantage of making the JVM stack based is that it is easier to implement a stack-based architecture using registers than vice versa. Thus, porting the JVM to Intel platforms is easy compared with porting a register-based virtual machine to a stack-based hardware platform.
In addition, there are benefits in a stack-based architecture when it comes to establishing what code actually does - more of this in the next chapter.
As we have already mentioned, the Java bytecode is object-oriented. This makes for safer code since the JVM checks at runtime that the type of fields being accessed or methods invoked for an object are genuinely applicable to that object.
In the 80x86 code snippet, we have variable names to make it clearer what the code is doing but, there are no checks to make sure that the value loaded into the base register really is a pointer to an object of type pointlessButton and that the offset loaded into SI represents the count field of that object.
There is no object-level information at all stored in 80x86 machine code, regardless of the high-level language from which it was compiled!
This is so important we'll restate it: even if you write programs in Java, once you compile them to 80x86 machine code, all object information is lost and with it a degree of security since the runtime engine cannot test for the validity of method and/or field accesses.
While on the subject of type information, another difference to notice is the inclusion of type information in JVM bytecode instructions. The instruction iadd, for example, pops the top two values from the stack, adds them and pushes the return value. The i- prefix indicates that the instruction operates on and returns an integer value. The JVM will actually check that the stack contains two integers when the iadd instruction is to be executed. In fact this check is performed by the bytecode verifier, prior to runtime execution.
Contrast this with the 80x86 instructions which contain no type information. In this case, it is possible that the data loaded into the CX register for incrementing is an integer. It is also possible that it is part of a telephone number, an address, or a recipe for apple pie. There are simply no checks performed on data type. This is fine if you can trust your compiler and there is no likelihood of programs being attacked en route to their execution environment. As we have seen, however, in a networked environment, these assumptions cannot be made so lightly.
Not all bytecodes are typed; with a maximum of 256 distinct bytecode values there simply aren't enough to go around. Where a bytecode instruction is typed, the type on which it can operate is indicated by the prefix of the instruction. See Type Prefixes for Bytecodes lists the type prefixes and See Bytecode Table shows the bytecodes in detail.
Bytecode Table
There are a few seeming anomalies about this table. For example, the ?cmp and ?newarray instructions are typed and yet only apply to a single type (long in the case of ?cmp and object references in the case of ?newarray). Interestingly enough there is no equivalent of the ?cmp instruction for integers. These oddities can be explained away in terms of future expansions to the instruction set. However there are other peculiarities which are not as easily explained.
Consider the fact that there are no typed arithmetic instructions for byte or short values. This, coupled with the lack of support for short and byte values in the constant pool, might lead you to believe that the underlying support in the JVM for these types is less than full. You would be right.
The JVM's processor stack is 32 bits wide. Values which are longer (doubles or longs) or shorter (bytes or shorts) than this are treated specially within the JVM. Double and long values occupy two spaces each on the stack and thus require special instructions to deal with them. Bytes and shorts on the other hand are treated as integers within the JVM for arithmetic and logical operations. If you are dealing with pure Java source code then this is not a problem as the Java compiler will take care of generating the appropriate instructions on your behalf. If you start to work with bytecode which has not been generated from the Java compiler then things become a little different and it is quite possible that variables of byte or short types may end up containing values larger than their maximum permissible ones.
This is a symptom of one of the general difficulties with the JVM. There is no one-to-one relationship between Java source code and bytecode. On the one hand, the lack of a tight binding between the source language and bytecode enables cross-compilation from other source languages as we discussed previously.
On the other hand it does mean that there has to be a lot more work performed to ensure that the bytecode being executed is safe. There is some concern that the lack of a rigid relationship between the Java language and Java bytecode may be the source of some as yet undiscovered nastiness which could emerge to overthrow the entire Java security model. The next chapter looks at some of the measures which have been taken to prevent this type of nastiness.