![]()
![]()
![]()
After you closely read the earlier chapters of this book, you went out and created your own Web presentation with a pile of pages linked together in a meaningful way, a smattering of images, and a form or two, and you think it's pretty cool. Then you added tables and image alignment, converted several images to JPEG, added some really cool QuickTime video of you and your cat, and set up a script that rings a bell every time someone clicks on a link. It can't get much cooler than this, you think. You're finally done.
I have bad news. You're not done yet. There are two things you have to think about now: testing what you've got, and maintaining what you will have.
Testing is making sure your Web presentation works—not just from the technical side (Are you writing correct HTML? Do all your links work?), but also from the usability side (Can people find what they need to find on your pages?). In addition, you'll want to make sure it's readable in multiple browsers, especially if you're using some of the more recent tags you learned about.
But even after everything is tested and works right, you're still not done. Almost as soon as you publish the initial presentation, you'll want to add stuff to it and change what's already there to keep things interesting and up to date. Trust me on this. On the Web, where the very technology is changing, a Web presentation is never really done. There are just some pages that are less likely to change than others.
After you're done with this chapter, you'll know all about the following topics:
Integrity testing has nothing to do with you or whether you cheated on your taxes. Integrity testing is simply making sure that the pages you've just put together work properly—that they display without errors and that all your links point to real locations. It doesn't say anything about whether your pages are useful or whether people can use them, just that they're technically correct. There are three steps to integrity testing:
The first step is to make sure you've written correct HTML: that all your tags have the proper closing tags, that you haven't overlapped any tags or used tags inside other tags that don't work.
But that's what checking in a browser is for, isn't it? Well, not really. Browsers are designed to try to work around problems in the HTML files they're parsing, to assume they know what the author was trying to do in the first place, and to display something if they can't figure out what you were trying to do. (Remember that example of what tables look like in a browser that doesn't accept tables? That's an example in which the browser tries its very best to figure out what you're trying to do.) Some browsers are more lenient than others in the HTML they accept. A page with errors might work fine in one browser and not work at all in another.
But there is only one true definition of HTML, and that is what is defined by the HTML specification. Some browsers can play fast and loose with the HTML you give them, but if you write correct HTML in the first place, your pages are guaranteed to work without errors in all browsers that support the version of HTML you're writing to.
 Actually, to be technically correct, the one true definition of HTML is defined by what is called the HTML DTD, or Document Type Definition. HTML is defined by a language called SGML, a bigger language for defining other markup languages. The DTD is an SGML definition of a language, so the HTML DTD is the strict technical definition of what HTML looks like.
Actually, to be technically correct, the one true definition of HTML is defined by what is called the HTML DTD, or Document Type Definition. HTML is defined by a language called SGML, a bigger language for defining other markup languages. The DTD is an SGML definition of a language, so the HTML DTD is the strict technical definition of what HTML looks like.
So how can you make sure that you're writing correct HTML? If you've been following the rules and examples I wrote about in earlier chapters, you've been writing correct HTML. But everyone forgets closing tags, puts tags in the wrong places, or drops the closing quotes from the end of an HREF. (I do that all the time, and it breaks quite a few browsers.) The best way to find out whether your pages are correct is to run them through an HTML validator.
HTML validators are written to check HTML and only HTML. The validators don't care what your pages look like—just that you're writing your HTML to the current HTML specification (HTML 2.0 or 3.2, and so on). If you've ever used UNIX programming tools, HTML validators are like the lint tool for finding code problems. In terms of writing portable HTML and HTML that can be read by future generations of authoring tools, making sure you're writing correct HTML is probably a good idea. You don't want to end up hand-fixing thousands of pages when the ultimate HTML authoring tool appears, and you discover that it can't read anything you've already got.
Of course, even if you're writing correct HTML, you should test your pages in multiple browsers anyway to make sure you haven't made any strange design decisions. Using a validator doesn't get you off the hook when designing.
So how do you run these HTML validators? Several are available on the Web, either for downloading and running locally on your own system, or as Web pages in which you can enter your URLs into a form, and the validator tests them over the network. I like two in particular: WebTech's HTML validation service, and Neil Browsers' Weblint.
The WebTech HTML validator (previously known as HAL's HTML validator) is a strict HTML 2.0 or 3.2 validator, which tests your HTML document against the SGML definition of HTML. Passing the HTML validator test guarantees that your pages are absolutely HTML compliant. Figure 29.1 shows the HTML validator home page at http://www.webtechs.com/html-val-svc/, where you can interactively test the pages you've already published.
Figure 29.1. The HTML validator home page.
You can test your pages at several levels:
In addition to these basic levels, you can also choose Strict compliance, which points out the following:
Selecting or not selecting Strict will produce different output, so try your pages in both.
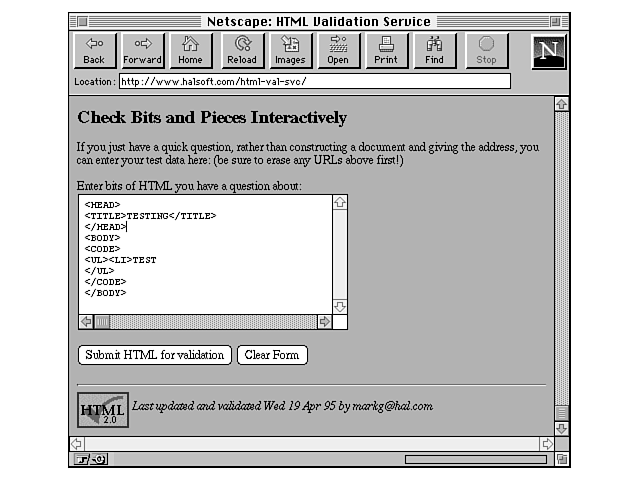
You can specify your pages as URLs (if they've already been published). Or, if you're not sure that a bit of HTML code is correct, you can copy and paste it into the form and test it from there (see Figure 29.2).
Figure 29.2. Testing bits of code in the HTML validator.
If your pages aren't published, but you still want to test them, the validator program is available for several platforms (all UNIX-based, unfortunately). See http://www.webtechs.com/html-tk for details.
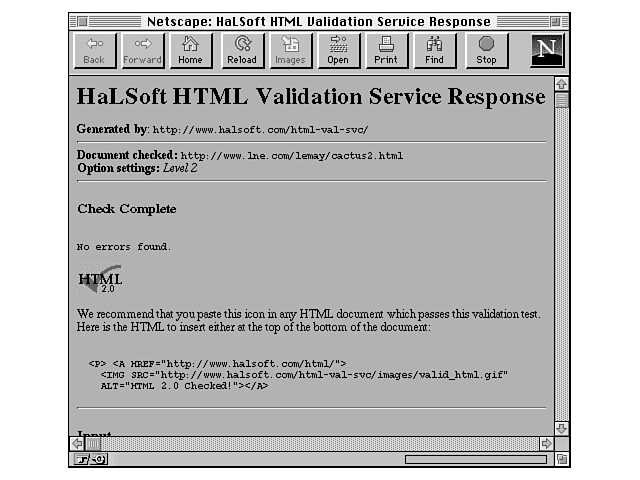
Your HTML page is tested against an SGML parser and the current HTML definition for the level you choose; any errors found are reported (an example is shown in Figure 29.3). If you selected Show Input in the original form, your HTML code with line numbers is also included in the output, which is useful for finding the errors that the validator is complaining about.
Figure 29.3. Errors returned from HTML validator.
In this example, the error returned was about a paragraph in which I had mistakenly left off the <P> tag but remembered to include the </P>, like this:
Every once in a while I get the urge to be funny. Luckily for those around me it usually passes in a few minutes. But sometimes I write things down.</P>
Having a closing tag without a corresponding opening tag won't make much difference to the display of the document, but it might cause the document to have problems in a more strict HTML reader. By having the validator point it out, I can fix it now.
When you've fixed one error in your HTML file, rerun the test. The HTML validator does not keep checking your file when it finds a fatal error, so there might be errors further on in your file.
The error messages that the validator produces are often unclear, to say the least. Strict compliance testing, in particular, seems to result in lots of incomprehensible errors. Test your documents with both, and fix the errors that seem obvious.
The Weblint program is a more general HTML checker. In addition to making sure your syntax is correct, it also checks for some of the more common mistakes: mismatched closing tags, putting TITLE outside of HEAD, multiple elements that should appear only once, and points out other hints (have you included ALT text in your <IMG> tags?). Its output is considerably friendlier than the HTML validator, but it is less picky about true HTML compliance (and, in fact, it might complain about more recent tags such as tables and other HTML additions).
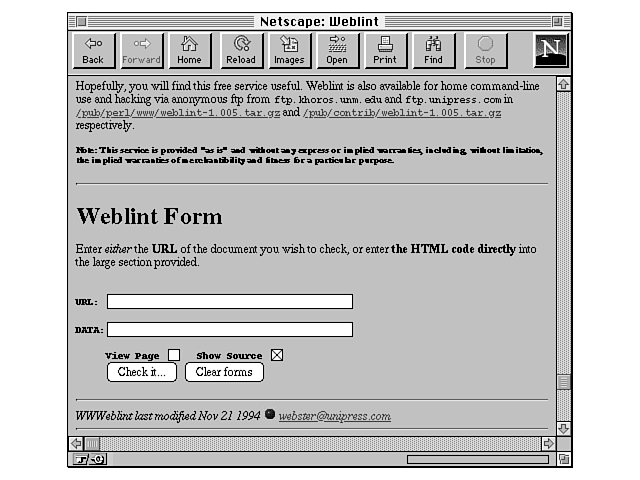
Figure 29.4 shows the Weblint page at http://www.unipress.com/weblint/. In particular, it shows the form you can use to submit pages for checking.
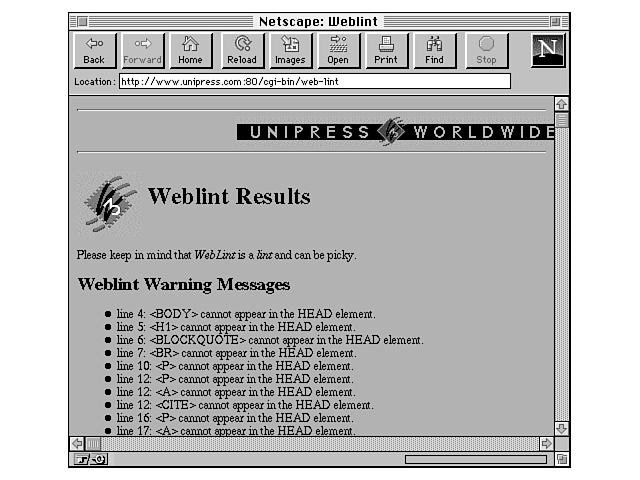
Figure 29.5 shows the output of a sample test I did, with the same page that produced the missing <P> tag error.
Figure 29.4. Weblint HTML checker.
Interestingly enough, Weblint pointed out that I was missing a closing </HEAD> tag, which the validator missed, but skipped over the fact that I had a </P> without a corresponding <P>. These were on the same page, but each program produced different errors.
If you'd rather use Weblint on your own system, you can get the code (written in Perl) at ftp://ftp.unipress.com/pub/contrib/weblint-1.005.tar.gz.
Just to show the kinds of errors that Weblint and the validator pick up, let's put together a sample file with some errors in it that you might commonly make.
One example is Susan's Cactus Gardens home page, as shown in Figure 29.6.
Figure 29.6. Susan's Cactus Gardens.
In Netscape, the page looks and behaves fine. But here's the code. It's riddled with errors. See if you can find them here before we run it through a validator.
<HTML> <HEAD> <TITLE>Susan's Cactus Gardens: A Catalog</TITLE> <HEAD> <BODY> <IMG SRC="cactus.gif" ALIGN=MIDDLE> <STRONG>Susan's Cactus Gardens</STRONG> <H1>Choosing and Ordering Plants</H3> <UL> <H3> <LI><A HREF="browse.html">Browse Our Catalog <LI><A HREF="order.html>How To Order</A> <LI><A HREF="form.html">Order Form</A> </UL> </H3> <HR WIDTH=70% ALIGN=CENTER> <H1>Information about Cacti and Succulents</H1> <UL> <LI><A HREF="succulent.html">What does succulent Mean?</A> <LI><A HREF="caring.html">How do I care for my cactus or succulent?</A> <LI><A HREF="propogation.html">How can I propagate my Cactus or succulent?</A> </UL> <HR> <ADDRESS>Copyright © 1994 Susan's Cactus Gardens susan@catus.com</ADDRESS>
Let's try it in Weblint first. I've found that because Weblint's error messages are easier to figure out, it's easier to pick up the more obvious errors there first. Weblint's response (or at least, some of it) is shown in Figure 29.7.
Figure 29.7. Weblint's response to the file with errors.
Let's start at the top with the first error:
line 4: tag <HEAD> should only appear once. I saw one on line 2!
Here's that code again, lines 1 through 4:
<HTML> <HEAD> <TITLE>Susan's Cactus Gardens: A Catalog</TITLE> <HEAD> <BODY>
There's a <HEAD> tag on the fourth line that should be a </HEAD>. Some browsers have difficulties with the body of the document if you forget to close the head, so make sure this gets fixed.
When that error is fixed, a lot of the other errors in the list from Weblint that refer to X cannot appear in the HEAD element should go away. Let's move on to the next error:
line 6: IMG does not have ALT text defined.
This one is self-explanatory. There's no value for ALT in the <IMG> tag. Remember, in text-based browsers, all images that don't have ALT will appear as the marker [IMAGE], which looks awful. Here's how I've modified that tag:
<IMG SRC="cactus.gif" ALIGN=MIDDLE ALT="">
Because the picture here is purely decorative, it really doesn't matter if there's a text version or not. We'll put in just an empty string so that if the page is viewed in a text-based browser, nothing shows up to indicate that the image was there:
line 8: unmatched </H3> (no matching <H3> seen).
Let's take a look at line 8:
<H1>Choosing and Ordering Plants</H3>
This one's easy to figure out. We've accidentally closed an H1 with an H3. The opening and closing tags should match, so change the </H3> to <H1>.
The next error points out an odd number of quotes in line 12:
line 12: odd number of quotes in element <A HREF="order.html>.
Here's the full line:
<LI><A HREF="order.html>How To Order</A>
You'll note that there is not a closing quotation mark for that filename. This will work in older versions of Netscape but in not too many other browsers, and it's one of the most common errors.
Line 12 contains the next error:
line 12: <A> cannot be nested-</A> not yet seen for <A> on line 11.
Actually, this is an error on line 11:
<LI><A HREF="browse.html">Browse Our Catalog
There's no </A> tag on the end of that line, which explains the complaint. You can't put an <A> tag inside another <A> tag, so Weblint gets confused (there are several instances of this error in the report). Always remember to close all <A> tags at the end of the link text.
The last of the errors are all similar and refer to missing closing tags:
line 0: No closing </HTML> seen for <HTML> on line 1. line 0: No closing </HEAD> seen for <HEAD> on line 2. line 0: No closing </HEAD> seen for <HEAD> on line 4. line 0: No closing </BODY> seen for <BODY> on line 5. line 0: No closing </H1> seen for <H1> on line 8. line 0: No closing </UL> seen for <UL> on line 9. line 0: No closing </H3> seen for <H3> on line 10. line 0: No closing </A> seen for <A> on line 11.
A quick check shows that </BODY> and </HTML> are missing from the end of the file, which clears up that problem. Changing the second <HEAD> to be </HEAD> and the </H3> to be </H1> clears up that error as well.
But what about the next two? There's a complaint that <UL> and <H3> don't have closing tags, but there they are at the end of the list. Look at the order they are in, however. We've overlapped the UL and H3 tags here, closing the UL before we close the H3. By simply reversing the order of the tags, we can fix those two errors.
The last error is that missing </A> tag, which we've already fixed.
All right, we've made the first pass in Weblint, now let's try the result in the validator and see what it can find. We'll do a level-2 conformance and see what we find. The first error it comes up with is this one:
sgmls: SGML error at -, line 7 at ">":
Out-of-context IMG start-tag ended HTML document element
That error comes from these lines:
<IMG SRC="cactus.gif" ALIGN=MIDDLE> <STRONG>Susan's Cactus Gardens</STRONG>
What does out-of-context mean? It means that there's nothing in these lines that says what kind of document element the image and the text belong to. Are they a paragraph, or a heading, or something else? The <IMG> tag has to be inside a document element of some sort (a normal paragraph, a heading, a blockquote, and so on). Most browsers assume that floating text is a paragraph, but we should add a paragraph tag to the beginning and end of these lines to be sure:
<P><IMG SRC="cactus.gif" ALIGN=MIDDLE> <STRONG>Susan's Cactus Gardens</STRONG></P>
When the changes have been made, run it through the HTML validator again. (Remember, it might stop reporting errors before it gets to the end of the file.) This time we get a whole bunch of errors:
sgmls: SGML error at -, line 11 at ">":
LI start-tag implied by H3 start-tag; not minimizable
sgmls: SGML error at -, line 11 at ">":
Start-tag omitted from LI with empty content
sgmls: SGML error at -, line 11 at ">":
UL end-tag implied by H3 start-tag; not minimizable
sgmls: SGML error at -, line 12 at ">":
H3 end-tag implied by LI start-tag; not minimizable
sgmls: SGML error at -, line 12 at ">":
Out-of-context LI start-tag ended HTML document element
All of these errors are occurring at lines 11 and 12, which indicates that something is seriously wrong there. The code in question looks like this:
<UL> <H3> <LI><A HREF="browse.html">Browse Our Catalog <LI><A HREF="order.html>How To Order</A>
The first three errors indicate that the HTML validator is really confused by the H3 being inside an unordered list (the errors LI start tag implied by H3 and UL end tag implied by H3 being the prime indicators). A quick look at the HTML 2.0 specification shows that if you want to be truly HTML compliant, you cannot put a heading tag inside a list, or vice versa. Surprise, surprise. What worked fine in Netscape, and what is often a common practice for emphasizing bulleted items, is actually illegal HTML. So we'll need another way to emphasize those bulleted items, perhaps boldface instead:
<UL> <LI><B><A HREF="browse.html">Browse Our Catalog</A></B> <LI><B><A HREF="order.html">How To Order</A></B> <LI><B><A HREF="form.html">Order Form</A></B> </UL>
We've still got errors in the third pass:
sgmls: SGML error at -, line 15 at "W":
Possible attributes treated as data because none were defined
sgmls: SGML error at -, line 15 at ">":
Out-of-context data ended HTML document element (and parse)
Line 15 is the rule line:
<HR WIDTH=70% ALIGN=CENTER>
What's wrong with that? Remember that the validator is testing for HTML 2.0 compliance. The WIDTH and ALIGN tags are part of the Netscape extensions, not part of HTML 2.0. So now your choices are either to remove the extensions, as I'll do here, or to switch the HTML validator test to Mozilla so it'll skip over any Netscape extensions. Which one you want to choose depends on the goals of your pages.
One more test. Figure 29.8 shows the result.
Figure 29.8. The HTML validator result.
Congratulations! The cactus page is now HTML compliant. And it took only two programs and five iterations.
Of course, this example was an extreme one. Most of the time your pages aren't going to have nearly as many problems as this one had (and if you're using an HTML editor, many of these mistakes might never show up). But keep in mind that Netscape blithely skipped over all those errors without so much as a peep. Are all the browsers that read your files going to be that accepting?
As I noted before, all that HTML validators do is make sure your HTML is correct. They won't tell you anything about your design. After you finish the validation tests, you should still test your pages in as many browsers as you can find to make sure that the design is working and that you haven't done anything that looks fine in one browser but awful in another. Because most browsers are free and easily downloaded, you should be able to collect at least two or three for your platform.
Ideally, you should test each of your pages in at least three browsers:
Using these three, you should get an idea for how different browsers will view your pages. If you use the Netscape extensions in your pages, you might want to test those pages in both Netscape and Mosaic to make sure.
The third and final test is to make sure your links work. The most obvious way to do this, of course, is to sit with a browser and follow them yourself. This might be fine for small presentations, but with large presentations it can be a long and tedious task. Also, after you've checked it the first time, the sites you've linked to might move or rename their pages. Because the Web is always changing, even if your pages stay constant, your links might break anyway.
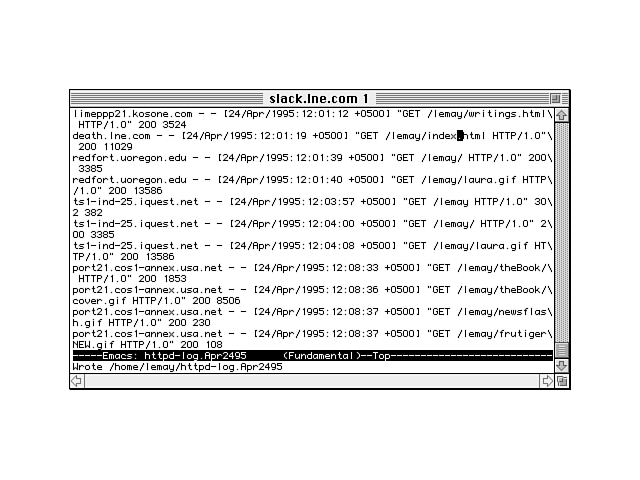
You can find out about some broken links on your own pages, which you might have caused when moving things around, by checking the error logs that your server keeps. Those logs note those pages that could not be found: both the missing page and the page that contained the link to that page. Of course, to appear in the error logs, someone must have already tried to follow the link—and failed. It would be a better plan to catch the broken link before one of your readers tries it.
The best way of checking for broken links is to use an automatic link checker, a tool that will range over your pages and make sure the links you have in those pages point to real files or real sites elsewhere on the Web. Several link checkers exist, including the following:
Usability testing is making sure that your documents are usable, even after they've been tested for simple technical correctness. You can put up a set of Web pages easily, but are your readers going to be able to find what they need? Is your organization satisfying the goals you originally planned for your pages? Do people get confused easily when they explore your site, or frustrated because it's difficult to navigate?
Usability testing is a concept that many industries have been using for years. The theory behind usability testing is that the designers who are creating the product (be it a software application, a VCR, a car, or anything) can't determine whether it's easy to use because they're too closely involved in it. They know how it is designed, so of course, they know how to use it. The only way you can find out how easy a product is to use is to watch people who have never seen it before as they use it and note the places they have trouble. Then, based on the feedback, you can make changes to the product, retest it, make more changes, and so on.
Web presentations are an excellent example of a product that benefits from usability testing. Even getting a friend to look at your pages for a while might teach you a lot about how you've organized things and whether people who are not familiar with the structure you've created can find their way around.
Here are some tasks you might want your testers to try out on your pages:
Sit with your testers and take notes. The results might surprise you and give you new ideas for organizing your pages.
Another method of usability testing your documents after they've been published on the Web is to keep track of your server logs, which you learned about in Chapter 27, "Web Server Hints, Tricks, and Tips." Your Web server or provider keeps logs of each hit on your page (each time a browser retrieves that document), and where it came from (see Figure 29.9). Examining your Web logs can teach you several things:
Figure 29.9. A sample log file.
Of course, even after you've published your pages and tested them extensively both for integrity and usability, your presentation isn't done. In fact, one could argue that your presentation is never done. Even if you manage to make it as usable as it could possibly be, there's always new information and new pages to add, updates to make, new advances in HTML that must be experimented with, and so on.
So how do you maintain Web presentations? Easy. You create new pages and link them to the old pages, right? Well, maybe. Before you do, however, read this section, and get some hints on the best way to proceed.
I'd like to start this section with a story.
In San Jose, California, there's a tourist attraction called the Winchester Mystery House, which was originally owned by the heiress to the Winchester Rifles fortune. The story goes that she was told by a fortune teller that the spirits of the men who had died from Winchester rifles were haunting her and her family. From that, she decided that if she continually added rooms onto the Winchester mansion, the spirits would be appeased. The result was that all the new additions were built onto the existing house or onto previous additions with no plan for making the additions livable or even coherent—as long as the work never stopped. The result is over 160 rooms, stairways that lead nowhere, doors that open onto walls, secret passageways, and a floor plan that is nearly impossible to navigate without a map.
Some Web presentations look a lot like this. They might have had a basic structure to begin with that was well-planned and organized and usable. But, as more pages got added and tacked onto the edges of the presentation, the structure began to break down, the original goals of the presentation got lost, and eventually the result was a mess of interlinked pages in which it's easy to get lost and impossible to find what you need (see Figure 29.10).
Figure 29.10. A confused set of Web pages.
Avoid the Winchester Mystery House school of Web page design. When you add new pages to an existing presentation, keep the following hints in mind:
Sometimes you might find that your presentation has grown to the point where the original structure doesn't work or that your goals have changed, and the original organization is making it difficult to easily get to the new material. Or maybe you didn't have a structure to begin with, and you've found that now you need one.
Web presentations are organic things, and it's likely that if you change your presentation a lot, you'll need to revise your original plan or structure. Hopefully, you won't have to start from scratch. Often there's a way to modify parts of the presentation so that the new material fits in and the overall presentation hangs together.
Sometimes it helps to go back to your original plan for the presentation (you did do one, didn't you?) and revise it first so that you know what you're aiming for. In particular, try these suggestions:
When you have a new plan in place, you can usually see areas in which moving pages around or moving the contents of pages to other pages can help make things clearer. Keep your new plan in mind as you make your changes, and try to make them slowly. You run a risk of breaking links and losing track of what you're doing if you try to make too many changes at once. If you've done usability testing on your pages, take the comments you received from that experience into account as you work.
Planning, writing, testing, and maintenance are the four horsemen of Web page design. You learned about planning and writing—which entail coming up with a structure, creating your pages, linking them together, and then refining what you have—all thoughout this book. In this chapter, you've learned about the other half of the process, the half that goes on even after you've published everything and people are flocking to your site.
Testing is making sure your pages work. You might have done some rudimentary testing by checking your pages in a browser or two, testing your links, and making sure all your CGI scripts were installed and called from the right place. But here you've learned how to do real testing—integrity testing with HTML validators and automatic link checkers, and usability testing to see whether people can actually find your pages useful.
Maintenance is what happens when you add new stuff to your presentation and you make sure that everything still fits together and still works despite the new information. Maintenance is what you do to keep your original planning from going to waste by obscuring what you had with what you've got now. And, if it means starting over from scratch with a new structure and a new set of original pages as well, sometimes that's what it takes. In this chapter, you learned some ideas for maintenance and revising what you've got.
Now you are done. Or at least you're done until it's time to change everything again.
Q: I still don't understand why HTML validation is important. I test my pages in lots of browsers. Why should I go through all this extra work to make them truly HTML compliant? Why does it matter?
A: Well, look at it this way. Imagine that, sometime next year, Web Company Z comes out with a super-hot HTML authoring tool that will enable you to create Web pages quickly and easily, link them together, build hierarchies that you can move around visually, and do all the really nifty stuff with Web pages that has always been difficult to do. And, they'll read your old HTML files so you don't have to write everything from scratch.
Great, you say. You purchase the program and try to read your HTML files into it. But your HTML files have errors. They never showed up in browsers, but they are errors nonetheless. Because the authoring tool is more strict about what it can read than browsers are (and it has to be with this nifty front-end), you can't read all your original files in without modifying them all—by hand. Doing that, if you've made several errors in each of the files, can mount up to a lot of time spent fixing errors that you could easily have avoided by writing the pages right in the first place.
Q: Do I have to run all my files through both Weblint and the WebTechs HTML Validator? That's an awful lot of work.
A: You don't have to do both if you don't have the time or the inclination. But I can't really recommend one over the other because both provide different capabilities that are equally important. Weblint points out the most obvious errors in your pages and does other nifty things, such as pointing out missing ALT text. HTML Validator is more complete but also more strict. It points out structural errors in your document, but the error messages are extremely cryptic and difficult to understand.
Keep in mind that if you download these programs and run them locally, doing a whole directory full of files won't take that much time. And, when you get the hang of writing good HTML code, you'll get fewer errors. So perhaps using both programs won't be that much of a hassle.
![]()
![]()
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}