
by Ivan Phillips
Just-In-Time compilers provide a way to bring high performance to Java applications by improving the efficiency with which Java bytecodes are converted to native processor instructions before execution. JIT compilation opens the door for Java developers to tackle high performance applications such as image processing, 3D modeling, and encryption.
This chapter looks at the principles behind JIT compilation, and presents an analysis of the types of optimizations that JIT compilers can perform, both today and in future implementations. Use of Just-In-Time compilation also justifies changes to the caching strategy for applets, to minimize the amount of code which needs to be recompiled.
I also present a review of some of the currently available JIT compilers, and highlight the types of operations that they accelerate and those that they do not affect.
Traditional compilers create native code programs for distribution to end users. For example, a word processing program for the Macintosh might be written in C and compiled by the developer into a Macintosh-only executable, then shipped on disk to retail stores.
In contrast, a Java compiler creates Java bytecodes that are architecture-neutral, so your Java programs can run on any platform. The disadvantage of bytecodes is that they must be translated to native processor instructions on the destination machine. This is not an issue for Java processors because, on Java chips, bytecodes are native instructions, but the predominant CPUs in the industry (Intel x86, IBM-Motorola PowerPC, Sun SPARC, MIPS R4000 series, and more) pay a performance penalty for the translation. Minimizing this performance penalty means making tradeoffs between translation time and execution time.
The first implementations of the Java Virtual Machine used an interpreter to translate the bytecodes into something understood by the CPU. Interpreters translate the bytecodes one by one while the program is running, and if an instruction is executed twice, it is translated twice. If a Java program has a loop that iterates over an instruction 1,000 times, that instruction is translated 1,000 times during execution. Of course, this is far from optimal, and has made interpreters a poor choice for computationally intensive tasks in which instructions are executed repeatedly[md]for example, 3D modeling and encryption.
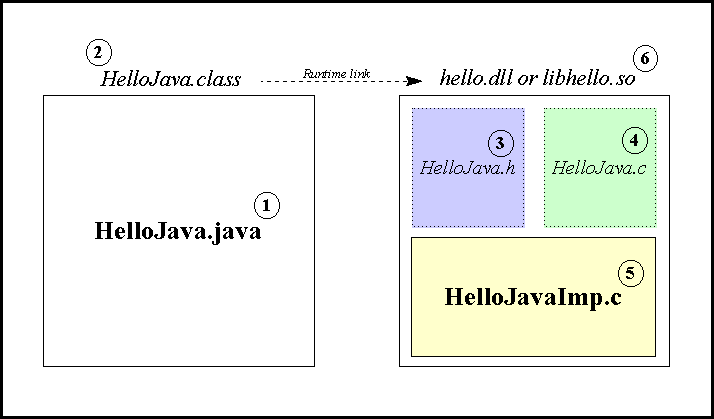
An effective way to improve performance of Java programs is to use Just-In-Time (JIT) compilation. A JIT compiler converts the bytecodes to native processor instructions on the end user’s machine, immediately before execution begins. This can dramatically improve the performance of iterative instruction loops. Figures 39.1 through 39.3 show the processes of traditional compilation, interpretation, and JIT compilation.
Traditional compilation converts source code to native code before distribution to the end user.
Java source code is first compiled to bytecodes for distribution. At the end user’s system, the bytecodes are continuously translated into native processor actions.
A JIT compiler optimizes processing of bytecodes on the end user’s system by converting some or all bytecodes to native code routines that run quickly and are not continuously translated.
Despite the aforementioned inefficiencies of interpreters, there are times when using an interpreter is actually more efficient than using a compiler. For example, startup and shutdown code of an applet probably be executed only once, and the time needed to JIT compile such routines may exceed the total time they would take to execute. For this reason, the most advanced virtual machines probably incorporate both an interpreter and a compiler, using each translator as appropriate.
Another advantage of an interpreter is that it generally makes debugging easier. Debugging interfaces for interpreters are usually superior to native code debuggers because debugging bytecodes running on a virtual machine is akin to debugging native code at the hardware level. This gives the developer more access to the state of the system.
Finally, because interpreters are easier to implement than JIT compilers, an interpreter is more likely to be bug-free than a compiler. Some bugs are so perplexing that it can be difficult to determine whether it is your fault or the a bug in the compiler. With a trustworthy interpreter, it is easy to determine whether the code is broken or the translator is. Of course, as Java technology matures, JIT compilers reliability should improve.
Just-In-Time compilers have a few special constraints that ordinary compilers do not. The first is compilation speed. The applet must compile in a very short time, or Web surfers won’t wait for the applet to begin executing. This means that a typical Java applet should not take more than one or two seconds longer to begin executing with the JIT compiler than it would with an interpreter. Fortunately, existing JIT compilers compile very quickly, and even with medium size applets (3,000 lines of Java source code or 60K of bytecode), the startup time is not obviously longer with the JIT compiler than it is with the interpreter.
The second constraint is that the compiler has to interact closely with a virtual machine that may already be interpreting code. This may restrict the compiled code to using the same data structures and memory references as the interpreter.
Rather than simply converting your program to native code, a good compiler optimizes the code it produces. Most optimization involves making the best use of the special talents of the specific processor on which the program will be run. For example, with Intel x86 processors, when setting an integer to 0, it is in some cases more efficient to XOR the integer with itself than it is to move the value 0 into it.
Other types of optimizations are processor independent. If you declare a variable and assign it a value but never use it, a smart compiler can remove the variable from the program to save space and allocation time. Table 39.1 lists some common compiler optimizations.
Table 39.1 Common Compiler Optimizations
| Optimization | Description |
| Register Variable | Microprocessors typically have 16 or 32 registers in which calculations are performed at high speed. Register variable optimization keeps the most commonly used variables in registers rather than in slower memory so as to reduce the number of memory accesses. |
| Common Subexpression | If the same calculation is hidden in several locations in the same routine, the compiler can save execution time by saving the result of the calculation instead of recalculating it each time. |
| Constant Folding | The compiler should calculate all constant expressions at compile time. This is normally done before executable code is created. |
| Dead Code Elimination | Removal of code and variables which are never used. Typically performed before executable code is produced. |
| Processor Optimization | Rewording the mix of native processor instructions to take best advantage of the processor’s architecture. |
Ideally, a JIT compiler would make the same optimizations as a traditional compiler, but because JIT compilation is performed immediately before execution, there must be a tradeoff between optimization and speed of compilation. For example, if it takes an additional five seconds to do a full optimization on a small Java applet, full optimization will probably be unacceptable to the user. The trivial solution is to do fewer optimizations so that execution can begin sooner. Some compilers allow the end user to control how much optimization is performed during JIT compilation, but ideally the user should be insulated from having to tweak compiler parameters.
Most of the optimizations listed in table 39.1 can be performed by the Java compiler when bytecode is created[md]for example, dead code can be eliminated before the class file is created. To minimize JIT compilation time, as many optimizations as possible should be made before the class file is generated. Register variable and processor specific optimizations need to be performed by the JIT compiler because they depend on the type of hardware being used to run the code.
An interesting future alternative to doing fewer optimizations is to compile in a separate thread. This technique would allow execution to begin immediately using the interpreter. If the compiler thread detects that a function would benefit from compilation, the function could be compiled in the background. When the compilation was complete, the interpreter would call the compiled code for that function for future calls. Such a compiler would provide the best of both worlds: rapid startup and, after a few seconds, high performance.
The problem with caching is that it is difficult to determine whether the remote data has been updated since it was last cached. To ensure that the cached page is not too old, most browsers download the remote HTML again before displaying a Web site that was cached in a previous session. Due to their longer download time, the associated graphics are usually cached blindly (for example, without checking for changes on the server) for a much longer period of time.
Unlike graphics files, Java applets are supposed to use the latest versions of their class files each time they are executed. This means that in current implementations of the class loader, applets are downloaded once per browser session to guarantee that the latest version of the applets’ classes are being used. Unfortunately, a Java applet is usually much larger than an HTML file, and for large applets, this is a serious weakness because it can take minutes to download an applet each time it is used.
A solution to this problem is to change the file format used by the browser to read in class files. The ZIP archive format is a popular compressed file format, and is likely to be supported in upcoming implementations of the class loader. Class files are quite compressible, and downloading compressed class files can more than double download speeds.
Another strategy is to use some sort of version control system to determine if the cache has been invalidated by changes on the remote system (for example, a new version of a class file is on the remote server). Currently, there’s no standard way to quickly determine the version number of a Java applet, though it is likely that this function will be implemented as part of a new class loading file format. Archive file formats like the ZIP file typically incorporate a directory block that contains the list of files in the archive and their modification dates. Directory blocks could be used to determine class file version information.
While the ZIP format has excellent compression, the directory block of a ZIP file is at the end of the ZIP file, not the beginning. This means that the class loader cannot determine if it needs to download the classes in the archive until it has already done so. Microsoft has suggested using its Cabinet archive format (CAB) instead of ZIP format. CAB archives are compressed archives, similar to ZIP files, but the directory block is at the start of the file, not the end. This permits the browser to cancel the CAB file transfer and begin execution of cached applets as soon as it determines that the local cache is still valid.
CONNECT! Corporation has already devised a proprietary scheme for serving up Java applets that incorporates both compression and version change notification. The CONNECT! Quick system, as it is known, relies on special server side and client side software to make it work.
JIT compilers will benefit from another type of caching mechanism. By caching recently JIT compiled code, a JIT compiler can save time by reusing native code that resulted from earlier compilations instead of recompiling the bytecodes. A native code cache refresh would occur whenever the bytecode cache was refreshed.
Asymetrix Corporation has developed a variant of JIT compilation which it has named Flash compilation. The Asymetrix SuperCede JVM compiles bytecodes at the class level into relocatable native code modules. Under Microsoft Windows, these modules take the form of standard dynamic link libraries, so that compiled classes can easily be cached for reuse. SuperCede is optimized to create the fastest possible executables and applies optimizations at the class level, not just at the function level. Because SuperCede does not include an interpreter, all bytecodes must be compiled. Of course, making the decision to compile all classes to native code generally results in slower startup times, but the improved ability to cache compiled code makes this type of architecture an excellent choice for larger applications.
Asymetrix chose to implement the VM as a Netscape plug-in, so it could be used with today’s industry standard browsers. Unfortunately, this means that applets must be referenced in the HTML file using the <EMBED> (plug-in) tag rather than the <APPLET> tag, making the applets unusable by standard VMs. As of this writing, the SuperCede VM is in beta, so the full potential of flash compilation has yet to be demonstrated.
A benchmark is a program that outputs a number proportional to the performance of the computer system on which it is running. A benchmark works by performing a set of operations and checking the real-time clock to determine how fast those operations are executing. The purpose of a benchmark is to compare the performance hardware and software configurations. The results of such testing can be used for several purposes, including:
Ideally, a benchmark tests the specific function or application in which you are interested. For example, if you’re shopping for a system to solve mathematical problems, you will want to use a mathematically intensive benchmark such as the Linpack benchmark, which tests the floating-point capability of the system and measures the time it takes to solve matrix equations. On the other hand, if you’re looking for a system to run your database application, you would want to compare systems on the basis of a database benchmark.
There are two broad categories of benchmarks:
![]()
![]()
Several benchmarks have been written in Java, and these benchmarks test the combination of the VM and the hardware. Java benchmarks are exciting because they can be run directly over the Internet, and can also be run by a wide range of platforms. When Java becomes an integral part of common operating systems, and Java becomes more widespread as an application programming language, Java benchmarks will be a useful test of cross platform performance. For now, the performance variations between VM implementations overwhelms performance differences due to hardware. Due to the dearth of sophisticated Java applications, few[md]if any[md]application-based benchmarks exist. Today’s Java benchmarks are synthetic tests of processor performance.
The most popular Java benchmark is the CaffeineMark 2.01 applet from Pendragon Software. The CaffeineMark runs in your Web browser or your Appletviewer, and tests nine aspects of VM performance. These tests are listed in table 39.2.
Table 39.2 Individual Tests Performed by the CaffeineMark 2.01 Java Benchmark
| Test | Description |
| Sieve | A prime number sieve test. The sieve locates all the prime numbers less than 2048. |
| Loop | Runs several types of integer loops. The loops are sensitive to common compiler optimizations such as inline substitution, register variable, and constant subexpression optimization. |
| String | Tests string concatenation and search. It also stress tests the memory management system. |
| Method | Tests how fast the VM performs method calls. |
| Floating-Point | Floating-point tests simulate the calculations needed to rotate 50 3D points through 90 degrees, five degrees at a time. This tests primarily matrix multiplication, but also does some trigonometric function evaluation and division. |
| Logic | Executes loops containing decision trees. |
| Image | Tests the speed of the drawImage() call. A very small part of the Java system, but a very important part for animation. |
| Graphics | Tests the speed of the drawLine(), setColor(), and fillRect() calls. Again, a small, yet important part of the Java class library. |
| Dialog | Measures access time for components properties on a dialog box. |
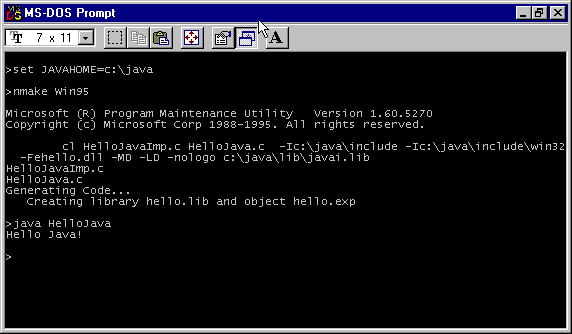
Figure 39.4 shows the CaffeineMark Java applet in action.
The CaffeineMark 2.01 Java benchmark executes in Microsoft Internet Explorer.
The CaffeineMark scores are used to make a comparative analysis between two systems[md]that is, the scores are used to determine if one system is faster than another and by how much.
By using the CaffeineMark, you can identify operations that are speeded up by the various compilers. This in turn may lead you to identify coding techniques which improve Java program performance.
To date, two Web browsers incorporate JIT compilers: Microsoft Internet Explorer and Netscape Navigator. Both JIT-enabled browsers are in beta test, and both run under 32-bit Windows platforms. Several Java development environments also feature JIT compilers. These products and their manufacturers are listed in table 39.3.
Table 39.3JIT Compiler Availability (as of August 1996)
| Product | Availability | Manufacturer |
| Asymetrix SuperCede | In beta July 1996 | Asymetrix Corporation http://www.asymetrix.com |
| Borland Latte | Available | Borland http://www.borland.com |
| Microsoft Internet Explorer 3.0 | Available | Microsoft Corporation http://www.microsoft.com |
| Microsoft Visual J++ | In beta July 1996 | Microsoft Corporation |
| Netscape Communications Navigator 3.0 | Available | Netscape Corporation http://home.netscape.com |
| Symantec Café 1.2 | Available | Symantec Corporation http://café.symantec.com |
It is instructive to look at CaffeineMark results from interpreters before looking at JIT compiler results. The scores from three Web browsers with interpreters are shown in figure 39.5.
A benchmark results comparison of Hot Java PreBeta 1, Microsoft Internet Explorer 3.0 Beta 1, and Netscape Navigator 2.02, all of which use interpreters.
The individual CaffeineMark test results for the interpreters hover around 100 for each test. This is because the reference system for the CaffeineMark[md]that is, the system which scores 100 on each test and 100 overall[md]uses Symantec Café’s interpreter. Notice that there’s little difference between available interpreters, except with respect to the Image test.
Looking at the results for Netscape Navigator 3.0 Beta 5A and Microsoft Internet Explorer 3.0 Beta 2 in figure 39.6, notice the dramatic difference their JIT compilers make in the browser performance profiles. In particular, the loop scores are accelerated by as much as a factor of 84.
A benchmark results comparison of Microsoft Internet Explorer 3.0 Beta 2 and Netscape Navigator 3.0 Beta 5A, both of which have JIT compilers. Notice the similar profiles.
The profiles of the two JIT compilers are actually very similar. Indeed, this profile is characteristic of all the JIT compilers: dramatically improved performance for iterative computations, and marginal performance gains for graphics, image, dialog, and memory-intensive operations.
With such a disparity between test scores, it is clear that the overall CaffeineMark result is of marginal value; the overall CaffeineMark scores are up by a factor of 13 to 15 with the JIT compiler, yet the String test scores were unaffected. The real performance gain with a JIT depends on what kind of operations your program performs.
How can you use the information in figure 39.6 to write better code? The first item you learn from the benchmark is that, to see significant acceleration, graphics, image, and dialog (awt) operations should be avoided within iterative code. For example, if you create a graphical progress meter to display the progress of an iterative computation, update the progress meter only occasionally to minimize the number of graphics operations required.
The String test measures garbage collection and virtual memory management as much as text processing. If your code allocates and garbage collects large amounts of memory, JIT compilation may be of little or no benefit.
Another opportunity for better Java performance can be found in text processing itself. The java.lang.String class is not optimized for concatenation (addition of Strings). Suppose you concatenate the word World onto the a string s that contains the word Hello:
String s;
s = “Hello “;
s = s + “World”;
System.out.println(s);
The concatenation operation creates a new string of length 11, then copies the word Hello into it, followed by the word World. It then turns the previous version of the string pointed to by s into garbage, and points s to the new string. This is inefficient because each concatenation implies making a copy of the original and throwing the original away. This excessive allocation, copying, and garbage collection is what results in the poor String processing efficiency, an effect which is more evident when using JIT compilers.
As an alternative to the use of String, you could use java.lang.StringBuffer when doing concatenations. The StringBuffer class still needs to do allocation and recopying, but it maintains a larger array of characters, so copies are less frequent. Each time you convert a StringBuffer to a String, a copy is made, so avoid frequent conversions from StringBuffer to String. The only downside to StringBuffer is the fact that it does not use the + operator, and calls to toString() are required every time an actual String object is needed. However, use of StringBuffer for string concatenation is considerably faster than using pure Strings. The alternative is:
StringBuffer sb;
sb = new StringBuffer(“Hello “);
sb.append(“World”);
System.out.println(sb.toString());
![]()
![]()
The aforementioned optimizations for graphics and text-processing are applicable to interpreters as well as JIT compilers. However, the effect of these optimizations on JIT compilers is more significant.
Even if you do not use any special coding practices, you will probably see an increase in the performance of your applets when using JIT compilation. That is, code which is efficient for the interpreter is generally efficient for the JIT compiler.
![]()
![]()
![]()
| Previous Chapter | Next Chapter |
|Table of Contents | Book Home Page |
| Que Home Page | Digital Bookshelf | Disclaimer |
To order books from QUE, call us at 800-716-0044 or 317-361-5400.
For comments or technical support for our books and software, select Talk to Us.
© 1996, QUE Corporation, an imprint of Macmillan Publishing USA, a Simon and Schuster Company
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}