
Notice: This material is excerpted from Special Edition Using CGI, ISBN: 0-7897-0740-3. The electronic version of this material has not been through the final proof reading stage that the book goes through before being published in printed form. Some errors may exist here that are corrected before the book is published. This material is provided "as is" without any warranty of any kind.
Now that you've debugged and tested your CGI script, you've probably discovered several places where you want to return errors rather than output to the user. You may want to send these error messages because a user has entered information incorrectly, a resource on your system is unavailable, or your script has a bug. As in any program, an infinite number of errors can occur. But how you detect these errors and return information about them is almost as important as what caused them, and thoughtfully managing your error handling is an important final touch to your CGI scripts and your Web site.
Error handling is a vital part of any application, but because the Web has perhaps more inexperienced users than any other province of the online world, you must be delicate about not only what you return as an error to your surfers, but how you do it. Inconsistent, too-general, or too-technical error messages may not only confuse your users, but alienate them as well.
Think of your error handling and error messages as you think of any other aspect of your program. The ideal system is easy to use, comprehensible, and thorough-in short, everything your users expect from the rest of your site.
In this chapter, you learn the following:
You can divide error handling into two halves, and although each is
important, the halves have differing purposes. Discovering errors is vitally
important to you, the programmer, whereas the presentation of error information
is probably more important to your users.
As a programmer, you may find that your goals and the goals of your users differ. Consider both carefully, but always remember that you're writing your program for the users.
The first half of handling an error is detecting it. Although the user never sees how your CGI program catches a mistake, doing it well is vitally important for the integrity and safety of your server (and the safety and integrity of your job and reputation). If an error goes undetected, not only will it go unreported and unfixed, but it may easily lead to further problems-even security breaches.
See "Trust No One," p. xxx, for more information on CGI security issues.
But more important from your users' perspective is the second half of error handling-how errors are reported, how they're explained, and how they may be corrected. Although you and a few fellow programmers may care very much that your script has suffered Error 42, your average user probably won't. He won't even know what it means. What he will care about is that no instructions about how to correct the problem are presented. Faced with an inscrutable error message, the user likely will simply leave your site.
As mentioned in the preceding section, the first half of handling an error correctly is actually detecting it. Although this point may seem obvious, you can accomplish this feat in three ways. Which method you choose not only affects how you finish handling the error, but how friendly and usable your CGI script becomes.
How you detect errors in your code can be a good reflection about how you approach life:
When you're programming CGI scripts, the worse your outlook is, the better your code will be.
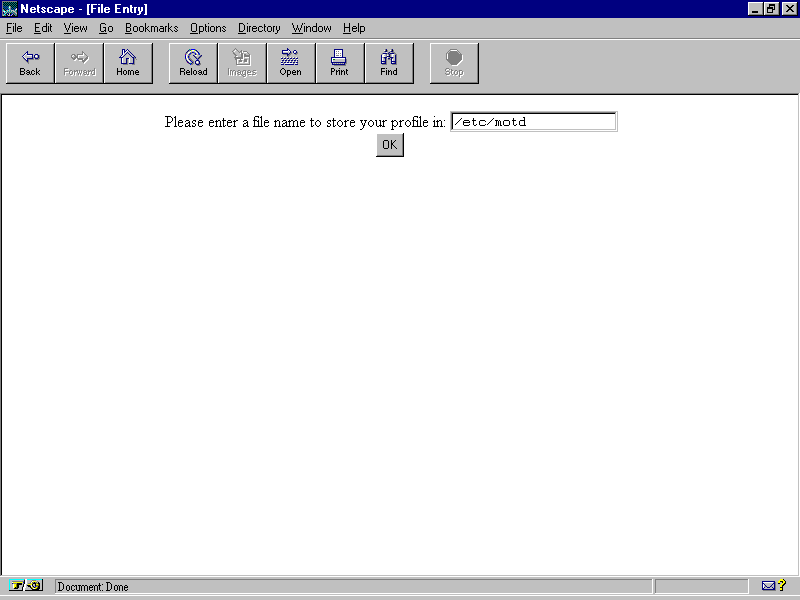
Of course, the simplest type of error detection you can put into your CGI script is none at all. By simply not checking for errors, you free yourself from having to handle them. This approach sounds great, but it can be tremendously dangerous-because, eventually, something will fail, and your program won't be able to anything about it. Listing 26.1, for example, does no error checking.
Listing 26.1 Code That Assumes Nothing Will Ever Go Wrong
#!/usr/bin/perl
# Set up the file to dump
$dump_File = "/etc/motd";
# Print the header
print("Content-type: text/html\n\n");
# Open, read and dump the file
open(DUMP_FILE,$dump_File);
read(DUMP_FILE,$dump_Text,4096);
print("<HTML><HEAD><TITLE>Message of the Day</TITLE></HEAD>\n");
print("<BODY><PRE>\n");
print("$dump_Text\n");
print("</PRE></BODY></HTML>\n");
This CGI program runs perfectly-usually. But if, for instance, the /etc/motd file can't be opened or can't be read, the script either produces an error and aborts, or worse-it simply continues to execute with inaccurate or incomplete results.
Actually bothering to detect errors is an important part of your CGI coding, and to make the wildly unrealistic assumption that things will always work is as foolish on the Web as it is in any other aspect of computing.
After you make the decision to check for errors, there are two ways to go about writing the actual detection code, and which way you choose is largely a function of how confident you are that a particular subroutine will be free from problems. Just as leaving error checking out because you're optimistic that things will go right is a mistake, so is being too positive about the checks you do include.
Listing 26.2 is a small Perl CGI script that makes positive assumptions. It's written so that flow continues if everything works as expected. In this respect, it's badly coded.
Listing 26.2 Code That Assumes the Best
#!/usr/bin/perl
# Set up the file to dump
$dump_File = "/etc/motd";
# Print the header
print("Content-type: text/html\n\n");
# Try to open the dump file
if (open(DUMP_FILE,$dump_File) == 0)
{
# Try to read the dump file
if (read(DUMP_FILE,$dump_Text,4096) > 0)
{
# Send the dump file
print("<HTML><HEAD>");
print("<TITLE>Message of the Day</TITLE>");
print("</HEAD><BODY><PRE>\n");
print("$dump_Text\n");
print("</PRE></BODY></HTML>\n");
exit(0);
}
}
# If we reached here, something went wrong
print("<HTML><HEAD><TITLE>MOTD Error</TITLE></HEAD><BODY>\n");
print("The Message of the Day could not be read!\n");
print("</BODY></HTML>\n");
exit(-1);
The error that listing 26.2 makes is to assume that each call will succeed. Although the calls to open() and read() are tested, and a different code path is followed if they fail, the basic outlook behind this program assumes that the calls will function as planned. Although these calls work the vast majority of the time, when they do fail, the code is structured in such a way as to tell you almost nothing about why.
Because the flow of the program continually expects each call to work-because the code makes optimistic assumptions-the error reporting is included almost as an afterthought, as something tacked onto the end in the unlikely event that things don't go exactly as planned. CGI programs written in this manner are harder to understand when they fail because all the possible errors the script can produce are lumped into a single, universal message.
But there's a better way.
Although not a terribly cheery outlook to carry around, assuming that things will go wrong can be very valuable while you're coding CGI scripts. If, rather than assume that each function call will work, you assume that it will fail, you'll be much more likely to include detailed, specific error messages that explain which particular call went wrong and what went wrong with it. Listing 26.3 is listing 26.2 rewritten in this manner.
Listing 26.3 Code That Assumes the Worst
#!/usr/bin/perl
# Set up the file to dump
$dump_File = "/etc/motd";
# Print a fatal error and exit
sub error_Fatal
{
print("<HTML><HEAD><TITLE>MOTD Error!</TITLE></HEAD><BODY>\n");
print("<H1>Error!</H1>Please report the following to the ");
print("Webmaster of this site:<P>\n");
print("<I>@_</I>\n");
print("</BODY></HTML>\n");
exit(-1);
}
# Print the header
print("Content-type: text/html\n\n");
# Try to open the dump file
if (open(DUMP_FILE,$dump_File) != 0)
{
print("<HTML><HEAD><TITLE>MOTD Error!</TITLE></HEAD><BODY>\n");
print("<H1>Error!</H1>\n");
print("<HR><I>Could not open MOTD file!</I><HR>\n");
print("</BODY></HTML>\n");
exit(-1);
}
# Try to read the dump file
if (read(DUMP_FILE,$dump_Text,4096) < 1)
{
print("<HTML><HEAD><TITLE>MOTD Error!</TITLE></HEAD><BODY>\n");
print("<H1>Error!</H1>\n");
print("<HR><I>Could not read MOTD file!</I><HR>\n");
print("</BODY></HTML>\n");
exit(-1);
}
# Send the dump file
print("<HTML><HEAD>");
print("<TITLE>Message of the Day</TITLE>");
print("</HEAD><BODY><PRE>\n");
print("$dump_Text\n");
print("</PRE></BODY></HTML>\n");
exit(0);
Notice a few things about listing 26.3. The most important is that this listing assumes each call will fail; because of that, it makes certain to provide more detailed information about which call bombed out than listing 26.2 does. This information is invaluable when you're trying to determine what went wrong and is the single biggest way you can improve your error-detection code.

When you're checking for errors in your CGI script, be sure to check for all possible conditions you may consider an error. For instance, listing 26.3 checks whether read() returns less than one. Although 0 is a legitimate return value (the file might be empty), you don't want the script to act as though it succeeded and print nothing to the screen. Therefore, both -1 (an error occurred) and 0 (nothing was read) are treated as errors.
But also notice that, because only negative comparisons continue the main flow of code, the program shown in listing 26.3 lines up along the left-hand margin much better. If you have to nest 15 or 20 comparisons before you're ready to send a response to the users, you would have to indent your code so far that it would expand beyond the right side of the screen. Although alignment is seemingly a small matter, it can make large programs much easier to read.
Many people claim that the easiest code to read contains no error detection at all, that the overwhelming number of if statements in heavily error-checked code is distracting. And it's true. Often, small, simple routines can balloon enormously after error detection is added to it.
This code, however, is always worth the extra typing and aesthetic unpleasantness. Although only you and a few other programmers have to put up with what the code actually looks like, each one of your users has to put up with the seemingly random and unpredictable output produced by a script that does no error checking.
Although the attitude you adopt about the success or failure of each particular function call in your CGI script seems a small matter, it can greatly affect how you approach your error handling. If you assume that things will go wrong-by always testing for the failure of a call-your scripts can deliver more detailed error messages, both to you and to your users.
Of such small matters are the great CGI programs separated from the merely adequate.
After you successfully detect errors, you must let the users know what has gone wrong and how they can correct the situation. At the very least, you should tell them who to contact about having things fixed, if they can't fix the errors by themselves.
Reporting errors is important, but many CGI programmers skimp on such niceties. They simply detect errors and offer obscure, possibly meaningless, error messages to the users who-more often than not-will shrug and move on to a less confusing site. Figure 26.1 shows an example of such a message.
Error messages like this one don't help much.
How you report your errors is critical. Although a good argument could be made that actually detecting the errors is the more important of the two halves of error handling-errors don't really exist until they're discovered-how you return error messages to the user isn't to be ignored.
When you begin coding your CGI script, your initial impulse might be simply to throw a response at the user when something goes wrong. After all, when you code, you're not concentrating on what will happen when your program doesn't work, but what will happen when it does.
This approach, however, will ultimately lessen the effectiveness of your script. By dumping any number of differing messages out to your users, you only confuse them. And if they receive errors, they're probably already pretty confused.
The consistency of your error messages is just as important as the consistency of any other aspect of your user interface and its ease of use. You should display error messages as consistently as possible so that they're easily recognizable.
One excellent way to gain consistency in your error reporting is to have one subroutine display all your errors. By accepting specific information about each error, a subroutine can wrap each in a common and distinct appearance. Listing 26.4 is a Perl example of a subroutine for displaying consistent errors.
Listing 26.4 Displaying Consistently Appearing Errors
sub error_Fatal
{
# Print the error
print("<HTML><HEAD><TITLE>Error!</TITLE></HEAD><BODY>\n");
print("<H1>Error!</H1>\n");
print("<HR><I>@_</I><HR>\n");
print("</BODY></HTML>\n");
# And exit
exit(-1);
}
When your CGI script reaches a point that it can't continue, it calls error_Fatal() with the reason as a parameter. error_Fatal(), from there, displays title and header information, and then the error.

When you're writing error subroutines, you must be sure to conclude them with code that exits the CGI script. If you leave out this obvious but easy-to-forget step, your subroutine returns and your program continues to execute-causing any number of other problems.
No matter how many different errors are reported by a program that uses error_Fatal(), they all appear the same, giving the user a reference point for instantly recognizing when something has gone wrong.
Although figure 26.2 and figure 26.3 report entirely different conditions, they're both quickly distinguishable as errors because they appear in a common format.
error appears similar to all other errors produced by a script that uses a common error-reporting subroutine.
The common appearance of errors lets users identify them easily, such as this Input message
After you create your subroutine, you can add several things to it to improve its content, or what you actually send users beyond a common layout.
The simplest error you can give to users is a rejection, to just tell them that something went wrong and that your CGI script can't continue. The code in listing 26.5 reports this kind of error. And as figure 26.4 shows, the error message from listing 26.5 isn't very helpful.
Listing 26.5 A Simple Rejection
sub error_Fatal
{
# Print the error
print("<HTML><HEAD><TITLE>Error!</TITLE></HEAD><BODY>\n");
print("<H1>Error!</H1>\n");
print("Something went wrong! I didn't expect <I>that</I> ");
print("to happen! Huh!\n");
print("</BODY></HTML>\n"):
# Exit the program
exit(-1);
}
This error report isn't very helpful.
Although you may be tempted to simply hand users the message that a problem occurred and walk away, you leave your users confused and possibly angry. If something does go wrong, they want to know what and how they can fix it. At the very least, your error messages should offer your users an explanation.
When users encounter error messages, they should instantly be able to tell that they (or the machine) have made a mistake. Consistent error screens can help accomplish this goal.
But what may not be obvious to users is the reason that the screen appeared. If your users realized that they were making errors, they likely wouldn't have made those errors in the first place, and your CGI script wouldn't have to reject them. This is the fundamental problem of having a single error response for your entire script.
Rather than simply tossing users a general error and letting them puzzle out the cause on their own, you should provide some sort of explanation of the error-its cause, its possible effects, and how it can be corrected. Providing an explanation for error conditions not only helps users fix their faulty input more easily-if that's the cause of the abort-but it can also be a benefit to you, to track down difficult bugs. A single, descriptive error message can point you to a problem that might have required hours of debugging otherwise.
Listing 26.6 is an improved version of listing 26.5. The subroutine accepts, as a parameter, a reason for the failure and then displays it as part of the message. When called, listing 26.6 produces the output shown in figure 26.5.
Listing 26.6 An Error Routine That Displays an Explanation
sub error_Fatal
{
# Print the error
print("<HTML><HEAD><TITLE>Error!</TITLE></HEAD><BODY>\n");
print("<H1>Error!</H1>\n");
print("<HR><I>@_</I><HR>\n");
print("</BODY></HTML>\n"):
# Exit the program
exit(-1);
}
A good error response includes the reason for the error.
And although an explanation of the cause of the error is a good addition to the subroutine, adding ways to provide even more detail is better. For instance, listing 26.6 doesn't offer a very descriptive title. You could rewrite the subroutine to accept not only an explanation for the error, but also a title that better explains the problem in broad terms. Listing 26.7 is one possible approach.
Listing 26.7 An Error Routine That Displays Even More Information
sub error_Fatal
{
local($error_Title);
# Get the specifics
$error_Title = "General" unless $error_Title = $_[0];
# Print the error
print("<HTML><HEAD>");
print("<TITLE>Error: $error_Title</TITLE>");
print("</HEAD><BODY>\n");
print("<H1>Error: $error_Title</H1>\n");
print("<HR><I>@_[1..@_]</I><HR>\n");
print("</BODY></HTML>\n"):
# Exit the program
exit(-1);
}
This code accepts, in addition to an error's explanation, a title for the error page. This page gives you even more flexibility in reporting why your script aborted. Note that you can also pass an empty string for the title, and a general default is then used. If possible, having defaults is always handy. Figure 26.6 is an example of the subroutine in action.
A title can be just as descriptive (and important) as the explanatory text on an error page.
Of course, there's no limit to the amount of information you can pass to the users. The current time, the machine's load average, the size of important databases-all are possible additions, some of which may be helpful, some of which may not. In the end, what you should pass back is everything the users will need to figure out what they did wrong-if, in fact, the error is their fault. Too much information may confuse them, and too little leaves them guessing and annoyed.
You should also remember that you aren't limited to passing back only English either; you can just as easily send HTML to an error routine. Your error routine can include links, for instance, to other parts of your site, or you can underline important phrases. Anything that you can display in a normal Web page can also be part of your error page. Use that capability to your advantage.
Perhaps the best way to create error explanations is to try to put yourself in your users' shoes, to try to figure out how you would react if you came across a particular error on somebody else's site. Be descriptive and detailed, but not too technical. It's a fine balance.
You might want to consider making two more additions to your error pages: administrative contacts and help pointers.
Often, when something goes wrong with your Web site, your users are the first to notice. Unless you can afford to monitor your computer 24 hours a day, seven days a week, the people who surf onto your pages are likely to find out about missing files, broken databases, or CGI errors before you do. They can help you when they discover something wrong, but only if you help them do it.
Imagine that you're browsing the Web, and after filling out a form, the site responds with the message shown in figure 26.7.
This CGI program has had some sort of internal trouble.
"Okay," you're liable to think, and move on, abandoning the site and forgetting all about it. Thousands of people who follow you might do exactly the same thing, with the computer's administrator none the wiser that something is seriously wrong.
But now imagine that the message in figure 26.8 appears instead. In all likelihood, you would take the few seconds you would need to mail the Webmaster about the problem. Because the link is readily available and an explanation of the problem is immediately at hand, this particular error message makes it easy for you to help out the computer's owner, who will learn about the problem the next time he or she reads mail.
The same error happened again, but now there's an easy way to report
it.
Alternatively (or in addition), you can have your error subroutine mail the problem report to the Webmaster.
Always make it easy for your users to do you a favor. If you have to return an error, something has gone wrong. If the cause of the problem isn't the users' input, you should make it as simple as possible for them to let you know. Listing 26.8 adds this improvement to the evolving routine.
Listing 26.8 An Error Routine That Allows for Easy Feedback
sub error_Fatal
{
local($error_Title);
local($error_Mail);
# Get the specifics
$error_Title = "General" unless $error_Title = $_[0];
$error_Mail = "webmaster@www.server.com" unless
$error_Mail = $_[1];
# Print the error
print("<HTML><HEAD>");
print("<TITLE>Error: $error_Title</TITLE>");
print("</HEAD><BODY>\n");
print("<H1>Error: $error_Title</H1>\n");
print("<HR><I>@_[2..@_]</I><HR>\n");
print("Please inform ");
print("<A HREF=\"mailto:$error_Mail\">$error_Mail</A> ");
print("of this problem. Thank you.\n");
print("</BODY></HTML>\n"):
# Exit the program
exit(-1);
}
Note that again you've allowed information to be sent to the subroutine that's then passed on to the users. Now the routine accepts an error title, a mail address for reporting problems, and the description of the actual error itself.
Remember, your users really owe you nothing, so you must make it as easy as possible for them to report problems with your site. Having an administrative contact on your error page can make a huge difference.
But what should you do if the cause of the error is the user's fault? It doesn't make sense to ask a user to contact a site's Webmaster if he or she has simply left an input field blank or included an exclamation point in an e-mail address. One solution is to replace the request for the report of errors with a reference to a help file that might let the user understand the mistake he or she has made. In other words, if the user has made a mistake, show him or her how to fix it.
Listing 26.9 is a further modification to error_Fatal(). It accepts an URL instead of an e-mail address and treats it as a help link. Figure 26.9 shows what listing 26.9 looks like in action.
Listing 26.9 An Error Routine That Allows for Easy Access to Help
sub error_Fatal
{
local($error_Title);
local($error_Url);
# Get the specifics
$error_Title = "General" unless $error_Title = $_[0];
$error_Url = "http://www.server.com/help.html" unless
$error_Url = $_[1];
# Print the error
print("<HTML><HEAD>");
print("<TITLE>Error: $error_Title</TITLE>");
print("</HEAD><BODY>\n");
print("<H1>Error: $error_Title</H1>\n");
print("<HR><I>@_[2..@_]</I><HR>\n");
print("For help, click <A HREF=\"$error_Url\">here</A>.\n");
print("</BODY></HTML>\n"):
# Exit the program
exit(-1);
}
When the user is responsible for an error, offering help is polite.
And, of course, you can combine these two techniques into a single routine. Or, perhaps better, you can split the single error_Fatal() routine into two, one for system errors (say, error_System()) and one for user errors (error_User()).
But whatever you choose to do, keep in mind that both administrative contacts and pointers to help are tools that make your error screens less annoying to encounter. By giving your users some obvious steps to take next, you can keep them engaged and using your site.
Both a MAILTO to the Webmaster and an HREF to a help page are examples of navigational aids. Rather than present users with a brick wall when they encounter errors, allow them an easy route to take-a next step.
But neither of these next steps really addresses the error itself or allows users to jump back instantly to where they were before the errors occurred. If, for instance, user input was the cause of the error-and your explanatory text was so clear that the user instantly understood the problem-a link that would allow him or her to jump back and correct the mistake would be handy and much appreciated.
Of course, almost all browsers have a "Back" button that lets surfers return to the previous page. But this button can be hidden away and awkward to reach. Adding a link makes backing up and trying again not only convenient, but it also adds that final touch of polish. Figure 26.10 shows an example of such a page.
An easily accessible link allows users to back up and try again.
Listing 26.10 is the user-error reporting subroutine you can use to produce the page shown in figure 26.10.
Listing 26.10 An Error Routine with a Backlink
sub error_User
{
local($error_Title);
local($error_UrlHelp);
local($error_UrlBack);
# Get the specifics
$error_Title = "General" unless $error_Title = $_[0];
$error_UrlHelp = "http://www.server.com/help.html" unless
$error_UrlHelp = $_[1];
$error_UrlBack = $ENV{"HTTP_REFERER"};
# Print the error
print("<HTML><HEAD>");
print("<TITLE>Error: $error_Title</TITLE>");
print("</HEAD><BODY>\n");
print("<H1>Error: $error_Title</H1>\n");
print("<HR><I>@_[2..@_]</I><HR>\n");
if ($error_UrlBack)
{
print("To try again, click ");
print("<A HREF=\"$error_UrlBack\">here</A>. ");
}
print("For help, click <A HREF=\"$error_UrlHelp\">here</A>.\n");
print("</BODY></HTML>\n"):
# Exit the program
exit(-1);
}
This routine still accepts a title and a help URL, but it also uses the HTTP_REFERER environment variable to get the URL of the previous page. This URL is used to allow the users a simple way to back up and try again. If, however, HTTP_REFERER isn't set-if the server doesn't provide that information to the CGI script-the line is left off so that you don't give the users a useless link.
When writing CGI scripts, take care never to offer users an empty, do-nothing link. Although these links look normal, nothing happens when users click them, and this may confuse or annoy your visitors. Always verify your data before presenting it.
The subroutine in listing 26.10 is named error_User() because it was designed to be called when an error is a user's fault. If the system produced the error-say, a required file is missing-you may not want to offer users a chance to return to the previous page. If a file isn't available, and you give users any easy path to repeat the action that dropped them into your error routine in the first place, they've gained nothing. Usually, you should limit backlinks to error screens that are caused by mistaken user input.
Although literally millions of different errors can occur in your CGI script, a much smaller set of problems occurs commonly. By being aware of these problems, you can be sure to always check for them, and by expanding on their basics, you can invent methods for catching others as well.
Because users can interact with your CGI script in a limited number of ways-forms, image maps, and paths-you should concentrate your tests for user errors in these areas. If a user is responsible for something going wrong, you can always trace the problem back to one of these methods of input.
The first thing you must do when you accept user input is validate it. Although people surfing your site may not have any malicious intent, they can drop subtle problems into their input in an infinite number of ways.
See "Where Bad Data Comes From," p. xxx, for more information on illegal user input.
When you receive data from users, you must always perform some sort of test on it to make sure that it's what you expected. Users can (intentionally or accidentally) wreak an untold amount of havoc on your Web site if they submit data in one form and you expect another.
For instance, figure 26.11 is a common page, simply requesting information from users. It seems that not much can go wrong here. But for every field in your form, users may enter something incorrectly: they may leave a name field blank, exclude a digit from the phone number, or type an illegal character in their e-mail address.
This CGI script requests contact information from surfers.
Rather than just accept this data and store it away, correct or not, your CGI script should validate it as well as it can and only then act on it. You can even check the data further, after you verify that each field is in the correct format. Figure 26.12 shows, for example, one way to handle a duplicate entry in a database.
Fig 26.12
Although a user entered correct information, further checking revealed that an error still occurred.
After you verify that all the users' input is correct (or verified as well as you can), you should be sure to handle any errors the system itself produces. Each function call that's included as part of a language has a possible error return because each can fail in a unique way.
You should diligently check each and every system call you make to see whether something has gone wrong. To open a file and not make sure that everything went as expected is foolhardy and will eventually cause you and your users a lot of trouble. To read from, write to, seek through, copy, delete, or move that file and not check whether the action succeeded or failed is also foolhardy. To do anything to that file, to any other file, or any other part of the system and not check whether something went wrong is-you may see this coming-foolhardy.
That said, however, there are exceptions. The only time you generally won't care when something has gone wrong is when you can do nothing about the problem. Ignoring the return status of the close() call, for instance, is common practice because you have no recourse if the function fails. Even the routine that sends text to the screen-print(), printf(), echo, whatever-returns a succeeded-or-failed value, but almost nobody has a reason to check it. What would you do if it didn't work? Print something?
But in general, checking each and every system call that you make for errors is vital. After the bugs are worked out of your CGI script and users' mistaken input is filtered, the only time your program can fail is when it's interacting with the system. And letting problems slip through when you're so close to being done would be a shame.
Of course, you must remember that your own subroutines form a part of the "system." The routine you write to average a list of numbers might encounter an error just as easily as open(), and this routine should be just as steadfast in reporting the error as the system function is.
And, as with system functions, you should check for the errors that your own subroutines can return. To expect your own routines to always work is just as overly optimistic as expecting the OS-provided routines to work, and can cause just as much trouble. Be sure to include your own subroutines in your error-checking thoroughness.
Beyond specific errors to check for, both from the system and from your users, the most important thing to keep in mind while handling errors is to maintain an awareness of what you're doing. Often, you can easily slip into bad habits or carelessness simply because error handling isn't the main focus of your CGI script.
You should constantly be on alert for this slippage; do everything you can to fight it. Question your assumptions as you write code. Review your program after you write it. Even set up your testing environment to cause specific errors, just to make sure that they report back as expected.
See "Testing Your Script," p. xxx, for more information on creating and running test suites.
In short, adopt the philosophy that error handling-how you detect and report mistakes-is as important as any other part of your program. All the features in the world will do your users no good if they're broken.
When checking for errors, don't become too positive about how a particular function will perform. Assume that something will go wrong, and check to see whether this is the case-in as many different places and in as many different ways as you can.
Computers are persnickety beasts and don't hesitate to return an error to your program at the slightest provocation. If even the smallest detail isn't exactly the way it was expected, your entire CGI script could bomb. If you check for the error, you present the users with an informative error message and an obvious next step to follow.
Remember Murphy's Law. The place in your code where you don't check for errors will end up producing the most. So check everywhere.
When your program does detect an error-and eventually it will-be sure to describe it in as much detail as you have available. Failing to provide enough detail makes an error message almost as useless as if it didn't exist.
Although the programmer who wrote the program that produced the error shown in figure 26.13 went to the trouble to detect a specific error, he or she didn't bother to take the extra 30 seconds required to compose a detailed and relevant error message. The result doesn't do the programmer-or the users-any good.
Fig 26.13
Too-vague error messages are almost as bad as none at all.
Now compare the message in figure 26.14 to the one in figure 26.13. This figure uses the exact same error reporting subroutine but gives a detailed, informative error message. With the information provided, users can correct their errors and continue to enjoy the site. Perhaps the best thing to keep in mind when reporting errors to users is to actually explain the problem. They can't correct what they don't understand.
Fig 26.14
Specific information in error messages is often helpful to users
who make mistakes.
After you finish your program, it's often a good idea to go back and reread your error messages. What seemed to make sense while you were coding may be a meaningless jumble now that you're in a less technical state of mind.
Remember, your users will probably be less technically sophisticated than you. Don't speak down to them when explaining problems, but make sure that they'll be able to understand you. Be plain; be specific; avoid jargon and tech-speak.
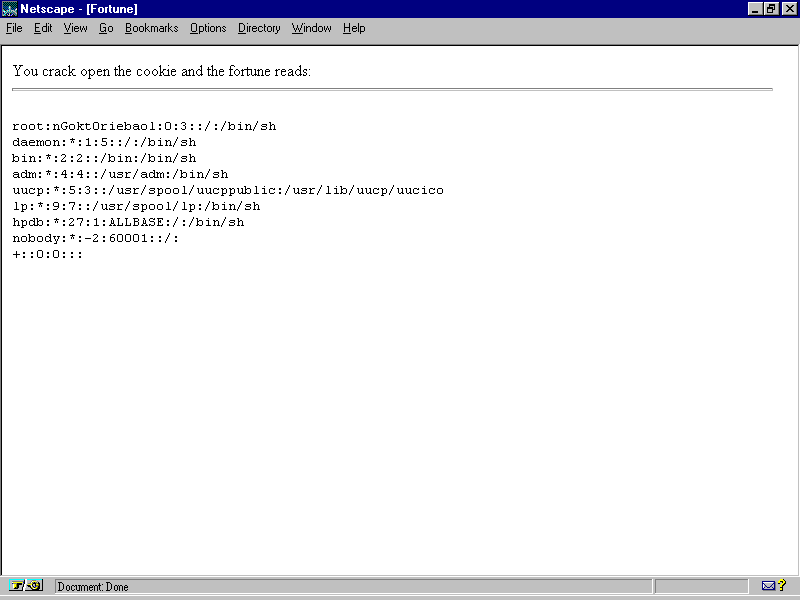
Of course, if an error isn't the users' fault, if it was produced by a problem with your script or your Web server, don't hesitate to have the error message give as much information to you as it can. Detailed data about not only what went wrong, but where and the surrounding context can be tremendously helpful when you're ready to debug the problem. In fact, many languages provide you with tools so that you can easily report the context of an error. Modern C compilers allow you to use the macros __LINE__, __FILE__, and __DATE__ to identify the line and file that produced the error, and the time and date that it was compiled. The errno global variable contains information about the reason that a system call failed, and you can use perror() to translate these codes into English. You can use all this information to produce a system-error page like the one shown in figure 26.15.
Fig 26.15
When an error is the system's fault, make your error message as detailed as possible.
For technical support for our books and software contact support@mcp.com
Copyright ©1996, Que Corporation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}