
Copyright ©1996, Que Corporation. All rights reserved. No part of this book may be used or reproduced in any form or by any means, or stored in a database or retrieval system without prior written permission of the publisher except in the case of brief quotations embodied in critical articles and reviews. Making copies of any part of this book for any purpose other than your own personal use is a violation of United States copyright laws. For information, address Que Corporation, 201 West 103rd Street, Indianapolis, IN 46290 or at support@mcp .com.
Notice: This material is excerpted from Special Edition Using CGI, ISBN: 0-7897-0740-3. The electronic version of this material has not been through the final proof reading stage that the book goes through before being published in printed form. Some errors may exist here that are corrected before the book is published. This material is provided "as is" without any warranty of any kind.
This chapter presents information that will make writing your CGI programs in C or C++ easier. Because this book is aimed at intermediate to advanced programmers, I'll assume that you already have a C compiler and are familiar with basic C syntax.
In particular, you'll learn how to accomplish, using C, the common CGI tasks discussed throughout the book. I'll also present some tips along the way to help you avoid the most common pitfalls of CGI programming. You'll also learn about
The first thing your script must do is determine its environment. The server will invoke your script with one of several request methods-GET, POST, PUT, or HEAD, and your script must respond accordingly.
The server tells you which request method is being used via an
environment variable called, appropriately enough, REQUEST_METHOD.
Your script should use getenv("REQUEST_METHOD")
to retrieve the value of this variable. The value will be a character
string spelling out GET, POST, PUT,
or HEAD.
PUT and HEAD are almost never used for CGI (their actions are undefined for CGI), and I won't discuss them here.
However, although you'll probably never encounter a situation where your program is invoked with a request method other than GET or POST, you should always check the value of REQUEST_METHOD carefully. It's not safe to assume that if the method isn't GET that it must be POST, or vice versa.
The code fragment in listing 22.1 demonstrates how to determine the request method.
Listing 22.1 Determining the Request Method
// This code fragment shows how to check the REQUEST_METHOD
// environment variable and respond accordingly. Note that
// the variable might be NULL if the script is executed
// from the command line, or it might be something other
// than the expected GET or POST.
char * pRequestMethod;
pRequestMethod = getenv("REQUEST_METHOD");
if (pRequestMethod==NULL) {
// do error processing
}
else if (stricmp(pRequestMethod,"GET")==0) {
// do GET processing
}
else if (stricmp(pRequestMethod,"POST")==0) {
// do POST processing
}
else {
// do error processing
}
When invoked with the GET method, all your script's input will come from environment variables. In particular, you should look for the QUERY_STRING variable.
If your script is invoked with
the QUERY_STRING variable will contain everything after the question mark, or color=blue&size=10. Use getenv("QUERY_STRING") to retrieve this information.
When invoked with the POST method (that is, from a form), you'll still get some information from environment variables, but the bulk of the input will come via STDIN (Standard Input). The CONTENT_LENGTH variable will tell you how many characters need to be retrieved. Listing 22.2 shows a simple loop to retrieve input from STDIN.
Listing 22.2 Reading STDIN
// This code fragment shows how to retrieve characters from
// STDIN after you've determined that your script was
// invoked with the POST method.
char * pContentLength; // pointer to CONTENT_LENGTH
char InputBuffer[1024]; // local storage for input
int ContentLength; // value of CONTENT_LENGTH string
int i; // local counter
int x; // generic char variable
// First retrieve a pointer to the CONTENT_LENGTH variable
pContentLength = getenv("CONTENT_LENGTH");
// If the variable exists, convert its value to an integer
// with atoi()
if (pContentLength != NULL) {
ContentLength = atoi(pContentLength);
}
else
{
ContentLength = 0;
}
// Make sure specified length isn't greater than the size
// of our staticly-allocated buffer
if (ContentLength > sizeof(InputBuffer)-1) {
ContentLength = sizeof(InputBuffer)-1;
}
// Now read ContentLength bytes from STDIN
i = 0;
while (i < ContentLength) {
x = fgetc(stdin);
if (x==EOF) break;
InputBuffer[i++] = x;
}
// Terminate the string with a zero
InputBuffer[i] = '\0';
// And update ContentLength
ContentLength = i;
***insert security icon
Notice how listing 22.2 verifies that the content length (number of bytes waiting in STDIN to be read) doesn't exceed the size of the preallocated input buffer. This is an extremely important step-not only because it helps you avoid ugly protection violations, but because purposefully overflowing the input buffer is a technique used by hackers to gain unauthorized access to your system. Under some circumstances on some systems, this allows a hacker to place executable instructions on the program stack or heap. Normal program execution then retrieves these instructions instead of what's supposed to be there.
See "CGI Script Structure," p. xxx, for an in-depth discussion on URL encoding.
Now that you've retrieved the input, either from the QUERY_STRING environment variable or by reading STDIN, you need to parse it. As you saw in Chapter 3, "Designing CGI Applications," the information will almost certainly need to be decoded, too.
If your script was invoked with the POST method, you need to check one more environment variable before starting to parse: CONTENT_TYPE. This variable is set by the server to tell your script how the information is encoded. You'll probably encounter only two values for CONTENT_TYPE-either NULL or application/x-www-form-urlencoded. If CONTENT_TYPE is NULL, your script should treat the input as though it weren't encoded at all. If CONTENT_TYPE is application/x-www-form-urlencoded, you need to parse and decode the input.
Information passed to your script (through the QUERY_STRING variable or through STDIN) will take the form var1=value1&var2=value2, and so forth, for each variable name/value pair.
Variables are separated by an ampersand (&). If you
want to send a real ampersand, it must be escaped-that
is, encoded as a two-digit hexadecimal value representing the
character. Escapes are indicated in URL-encoded strings by the
percent sign (%). Thus, %25 represents the percent
sign itself. (25 is the hexadecimal, or base 16, representation
of the ASCII value for the percent sign.) All characters above
127 (7F hex) or below 33 (21 hex) are escaped. This includes the
space character, which is escaped as %20. Also, the plus sign
(+) needs to be interpreted as a space character.

It's important that you scan through the input linearly rather than recursively because the characters you decode may be plus signs or percent signs.
There are as many ways of decoding URL-encoded data as there are programmers. You can use any of several public-domain libraries to do this for you (see "Helpful Libraries" later in this chapter), or you can roll your own code. Listings 22.3, 22.4, and 22.5 demonstrate the basic steps you'll need to take. You can use this code in your own projects, or just study it to see the techniques.
Listing 22.3 Splitting Out Each Variable Name and Value
// This code fragment demonstrates how to search through the input
// to find each delimiting token. It assumes you've already read
// the input into InputBuffer, and are ready to parse out the
// individual var=val pairs.
char * pToken; // pointer to token separator
char InputBuffer[1024]; // local storage for input
pToken = strtok(InputBuffer,"&");
while (pToken != NULL) { // While any tokens left in string
PrintOut (pToken); // Do something with var=val pair
pToken = strtok(NULL,"&"); // Find the next token
}
Listing 22.4 Printing Each Variable Name and Value
// This code fragment shows how to split out an individual var=val
// pair after you've located it within the input stream. This
// routine makes use of the URLDecode() routine in Listing 22.5
void PrintOut (char * VarVal) {
char * pEquals; // pointer to equals sign
int i; // generic counter
pEquals = strchr(VarVal, '='); // find the equals sign
if (pEquals != NULL) {
*pEquals++ = '\0'; // terminate the Var name
URLDecode(VarVal); // decode the Var name
// Convert the Var name to upper case
i = 0;
while (VarVal[i]) {
VarVal[i] = toupper(VarVal[i]);
i++;
}
// decode the Value associated with this Var name
URLDecode(pEquals);
// print out the var=val pair
printf("%s=%s\n",VarVal,pEquals);
}
}
Listing 22.5 Decoding URL-Encoded strings
// This code fragment shows how to un-URL-encode a given string.
// First, a subroutine that substitutes any instance of cBad with
// cGood in a string. This is used to replace the plus sign with
// a space character.
void SwapChar(char * pOriginal, char cBad, char cGood) {
int i; // generic counter variable
// Loop through the input string (cOriginal), character by
// character, replacing each instance of cBad with cGood
i = 0;
while (pOriginal[i]) {
if (pOriginal[i] == cBad) pOriginal[i] = cGood;
i++;
}
}
// Now, a subroutine that unescapes escaped characters.
static int IntFromHex(char *pChars) {
int Hi; // holds high byte
int Lo; // holds low byte
int Result; // holds result
// Get the value of the first byte to Hi
Hi = pChars[0];
if ('0' <= Hi && Hi <= '9') {
Hi -= '0';
} else
if ('a' <= Hi && Hi <= 'f') {
Hi -= ('a'-10);
} else
if ('A' <= Hi && Hi <= 'F') {
Hi -= ('A'-10);
}
// Get the value of the second byte to Lo
Lo = pChars[1];
if ('0' <= Lo && Lo <= '9') {
Lo -= '0';
} else
if ('a' <= Lo && Lo <= 'f') {
Lo -= ('a'-10);
} else
if ('A' <= Lo && Lo <= 'F') {
Lo -= ('A'-10);
}
Result = Lo + (16 * Hi);
return (Result);
}
// And now, the main URLDecode() routine. The routine loops
// through the string pEncoded, and decodes it in place. It checks
// for escaped values, and changes all plus signs to spaces. The
// result is a normalized string. It calls the two subroutines
// directly above in this listing.
void URLDecode(unsigned char *pEncoded) {
char *pDecoded; // generic pointer
// First, change those pesky plusses to spaces
SwapChar (pEncoded, '+', ' ');
// Now, loop through looking for escapes
pDecoded = pEncoded;
while (*pEncoded) {
if (*pEncoded=='%') {
// A percent sign followed by two hex digits means
// that the digits represent an escaped character.
// We must decode it.
pEncoded++;
if (isxdigit(pEncoded[0]) && isxdigit(pEncoded[1])) {
*pDecoded++ = (char) IntFromHex(pEncoded);
pEncoded += 2;
}
} else {
*pDecoded ++ = *pEncoded++;
}
}
*pDecoded = '\0';
}
Only a few tricky bits are involved in CGI output. Most of the time, you'll use printf() to write to STDOUT, just as if you were writing a console program that printed to the screen.
See "Processing," p. xxx, for more information about CGI headers. See "Understanding MIME Headers," p. xxx, for more details about MIME headers.
The very first thing your script needs to output, however, is the proper MIME header for the type of data your script will be sending. In most cases, this will be text/html or text/plain. The most common header is simply
printf("Content-type: text/html\n\n");
which tells the server to expect a content type of HTML text.
Note that your header must be terminated by a blank line.
The most common error for beginners to make is forgetting to terminate the header correctly. CGI headers can be multiline, so the only way the server knows the header is finished is when it sees a blank line. In C, you use \n\n to terminate the header. Failure to do so will almost certainly result in a Document contains no data or other error message.
It's also a good idea to turn off buffering on the STDOUT (Standard Output) stream. If you mix methods of writing to STDOUT while buffering is turned on, you may end up with jumbled output. Use
setvbuf(stdout,NULL,_IONBF,0);
to turn off buffering before you output anything else. Thus, the two lines most often found at the very top of a CGI script are
setvbuf(stdout,NULL,_IONBF,0);
printf("Content-type: text/html\n\n");
***begin xref; put next to following paragraph
[lbr] See "Row, Row, Row Your Script...," p. xxx, for a detailed explanation of STDOUT modes and buffering. (sidebar in Ch 3)
***end xref
If your script will output something other than plain HTML, be sure to use the content type header appropriate to the output. Also, if your script will be sending binary data, you need to switch output modes for STDOUT. By default, STDOUT is set to text mode (cooked). To send binary data over STDOUT, you need to change to binary mode (raw). This call will change modes for you:
setmode(fileno(stdout), O_BINARY);
After your script writes the header, it can immediately write its own output (whatever that may be). It's considered good form to flush the STDOUT stream just before terminating. Use
fflush(stdout);
to ensure that all your output is written properly.
Now let's take all the information in this chapter so far and make it into a complete, working program. You'll use all the code in the preceding listings, and add a few bits here and there to glue it all together.
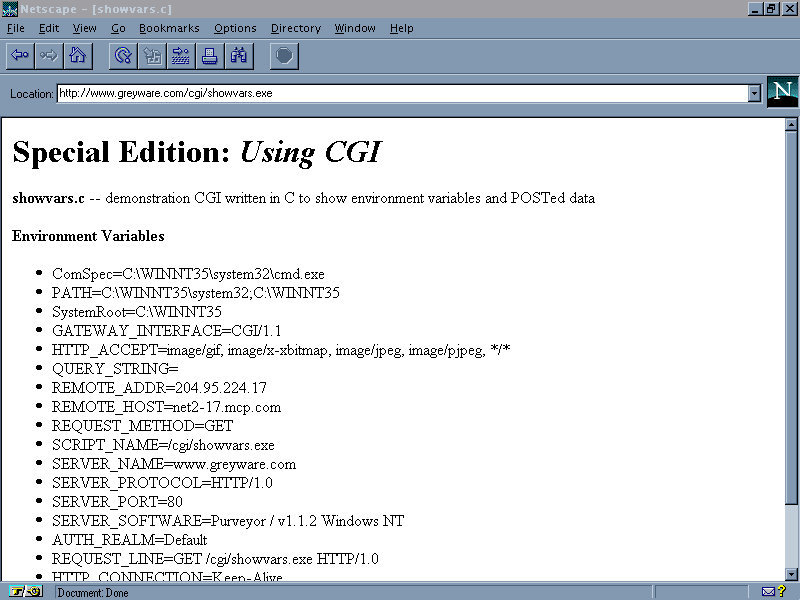
The result will be ShowVars (see listing 22.6). ShowVars has a simple top-down design, with a number of uncomplicated subroutines. The program determines how it was invoked, and takes appropriate action to decipher its input. It then decodes the input and prints it in a nicely formatted list, as shown in figure 22.1.
Listing 22.6 showvars.c: A Program that Demonstrates Reading, Parsing, URL Decoding, and Printing
// ShowVars
// A demonstration of CGI written in C
// This program shows all environment variables
// and POST data (when invoked with the POST method)
#include <windows.h> // only required for Windows
#include <stdio.h>
#include <stdlib.h>
// Global storage
char InputBuffer[1024]; // generic input buffer
// SwapChar: This routine swaps one character for another
void SwapChar(char * pOriginal, char cBad, char cGood) {
int i; // generic counter variable
// Loop through the input string (cOriginal), character by
// character, replacing each instance of cBad with cGood
i = 0;
while (pOriginal[i]) {
if (pOriginal[i] == cBad) pOriginal[i] = cGood;
i++;
}
}
// IntFromHex: A subroutine to unescape escaped characters.
static int IntFromHex(char *pChars) {
int Hi; // holds high byte
int Lo; // holds low byte
int Result; // holds result
// Get the value of the first byte to Hi
Hi = pChars[0];
if ('0' <= Hi && Hi <= '9') {
Hi -= '0';
} else
if ('a' <= Hi && Hi <= 'f') {
Hi -= ('a'-10);
} else
if ('A' <= Hi && Hi <= 'F') {
Hi -= ('A'-10);
}
// Get the value of the second byte to Lo
Lo = pChars[1];
if ('0' <= Lo && Lo <= '9') {
Lo -= '0';
} else
if ('a' <= Lo && Lo <= 'f') {
Lo -= ('a'-10);
} else
if ('A' <= Lo && Lo <= 'F') {
Lo -= ('A'-10);
}
Result = Lo + (16 * Hi);
return (Result);
}
// URLDecode: This routine loops through the string pEncoded
// (passed as a parameter), and decodes it in place. It checks for
// escaped values, and changes all plus signs to spaces. The result
// is a normalized string. It calls the two subroutines directly
// above in this listing, IntFromHex() and SwapChar().
void URLDecode(unsigned char *pEncoded) {
char *pDecoded; // generic pointer
// First, change those pesky plusses to spaces
SwapChar (pEncoded, '+', ' ');
// Now, loop through looking for escapes
pDecoded = pEncoded;
while (*pEncoded) {
if (*pEncoded=='%') {
// A percent sign followed by two hex digits means
// that the digits represent an escaped character. We
// must decode it.
pEncoded++;
if (isxdigit(pEncoded[0]) && isxdigit(pEncoded[1])) {
*pDecoded++ = (char) IntFromHex(pEncoded);
pEncoded += 2;
}
} else {
*pDecoded ++ = *pEncoded++;
}
}
*pDecoded = '\0';
}
// GetPOSTData: Read in data from POST operation
void GetPOSTData() {
char * pContentLength; // pointer to CONTENT_LENGTH
int ContentLength; // value of CONTENT_LENGTH string
int i; // local counter
int x; // generic char holder
// Retrieve a pointer to the CONTENT_LENGTH variable
pContentLength = getenv("CONTENT_LENGTH");
// If the variable exists, convert its value to an integer
// with atoi()
if (pContentLength != NULL) {
ContentLength = atoi(pContentLength);
}
else
{
ContentLength = 0;
}
// Make sure specified length isn't greater than the size
// of our staticly-allocated buffer
if (ContentLength > sizeof(InputBuffer)-1) {
ContentLength = sizeof(InputBuffer)-1;
}
// Now read ContentLength bytes from STDIN
i = 0;
while (i < ContentLength) {
x = fgetc(stdin);
if (x==EOF) break;
InputBuffer[i++] = x;
}
// Terminate the string with a zero
InputBuffer[i] = '\0';
// And update ContentLength
ContentLength = i;
}
// PrintVars: Prints out all environment variables
void PrintVars() {
int i = 0; // generic counter
// Tell the user what's coming and start an unnumbered list
printf("<b>Environment Variables</b>\n");
printf("<ul>\n");
// For each variable, decode and print
while (_environ[i]) {
strcpy(InputBuffer, _environ[i]);
URLDecode(InputBuffer);
printf("<li>%s\n",InputBuffer);
i++;
}
// Terminate the unnumbered list
printf("</ul>\n");
}
// PrintMIMEHeader: Prints content-type header
void PrintMIMEHeader() {
printf("Content-type: text/html\n\n");
}
// PrintHTMLHeader: Prints HTML page header
void PrintHTMLHeader() {
printf(
"<html>\n"
"<head><title>showvars.c</title></head>\n"
"<body>\n"
"<h1>Special Edition: <i>Using CGI</i></h1>\n"
"<b>showvars.c</b> -- demonstration CGI written "
"in C to show environment variables and POSTed "
"data<p>"
);
}
// PrintHTMLTrailer: Prints closing HTML info
void PrintHTMLTrailer() {
printf(
"</body>\n"
"</html>\n"
);
}
// PrintOut: Prints out a var=val pair
void PrintOut (char * VarVal) {
char * pEquals; // pointer to equals sign
int i; // generic counter
pEquals = strchr(VarVal, '='); // find the equals sign
if (pEquals != NULL) {
*pEquals++ = '\0'; // terminate the Var name
URLDecode(VarVal); // decode the Var name
// Convert the Var name to upper case
i = 0;
while (VarVal[i]) {
VarVal[i] = toupper(VarVal[i]);
i++;
}
// decode the Value associated with this Var name
URLDecode(pEquals);
// print out the var=val pair
printf("<li>%s=%s\n",VarVal,pEquals);
}
}
// PrintPOSTData: Prints data from POST input buffer
void PrintPOSTData() {
char * pToken; // pointer to token separator
// Tell the user what's coming & start an unnumbered list
printf("<b>POST Data</b>\n");
printf("<ul>\n");
// Print out each variable
pToken = strtok(InputBuffer,"&");
while (pToken != NULL) { // While any tokens left in string
PrintOut (pToken); // Do something with var=val pair
pToken=strtok(NULL,"&"); // Find the next token
}
// Terminate the unnumbered list
printf("</ul>\n");
}
// The script's entry point
void main() {
char * pRequestMethod; // pointer to REQUEST_METHOD
// First, set STDOUT to unbuffered
setvbuf(stdout,NULL,_IONBF,0);
// Figure out how we were invoked
pRequestMethod = getenv("REQUEST_METHOD");
if (pRequestMethod==NULL) {
// No request method; must have been invoked from
// command line. Print a message and terminate.
printf("This program is designed to run as a CGI script, "
"not from the command-line.\n");
}
else if (stricmp(pRequestMethod,"GET")==0) {
PrintMIMEHeader(); // Print MIME header
PrintHTMLHeader(); // Print HTML header
PrintVars(); // Print variables
PrintHTMLTrailer(); // Print HTML trailer
}
else if (stricmp(pRequestMethod,"POST")==0) {
PrintMIMEHeader(); // Print MIME header
PrintHTMLHeader(); // Print HTML header
PrintVars(); // Print variables
GetPOSTData(); // Get POST data to InputBuffer
PrintPOSTData(); // Print out POST data
PrintHTMLTrailer(); // Print HTML trailer
}
else
{
PrintMIMEHeader(); // Print MIME header
PrintHTMLHeader(); // Print HTML header
printf("Only GET and POST methods supported.\n");
PrintHTMLTrailer(); // Print HTML trailer
}
// Finally, flush the output
fflush(stdout);
}
This screen shot shows ShowVars in action.
The code is largely self-documenting. The parts that require special
comment have already been explained earlier, as each task was
presented.
The executable provided on the CD-ROM is compiled for 32-bit Windows, but you can take the source code and recompile it for any system. Leave off the #include <windows.h> line for UNIX systems; otherwise, the code is completely portable.
C's popularity comes from its portability across platforms (both hardware and operating system), and its capability to use common library routines. A C library is a group of subroutines your program can use, which you link to your program either at compile time or runtime. You can tailor the library to the requirements of a particular operation system or hardware platform. By linking with the appropriate version of the library and recompiling, you can use the same C source code for multiple target platforms.
See "Public Libraries," p. xxx, for even more libraries you can use.
Libraries can take the form of source-code routines you include
with your program, or object code you link with your program.
In the following sections, I'll list some of the most popular
and useful libraries and show you where to get them. Some of the
libraries and routines are licensed for public distribution; others
you'll have to download yourself. I've put the distributable ones
on the accompanying CD-ROM for your convenience. However, keep
in mind that public and commercial libraries are continuously
evolving pieces of software-you should check the main distribution
sites for updates, bug fixes, and enhancements.
Although the information in the following sections represents the most current list of available resources, before limiting your development to one of these libraries, you may want to search the Web using CGI Library as your search term. New libraries and techniques appear every day, and you may well find that someone else has solved your problems already.
cgi++ is a UNIX-based C++ class library used for decoding encoded data such as data received from an HTML form. This class library is available at this site. This site provides overview information for the cgi++ class, a simple access request form, and download access for the class code. (This library assumes that you have libg++ already installed on your system.)
This library/source code is mirrored on the CD-ROM that accompanies this book. The file name is cgitar.gz. Rename it to cgi++-2.2.tar.gz and decompress it on your system.
(d)uncgi
uncgi is a UNIX-based C++ library that provides an interface between HTML forms and server-based data. This class library is available at this site. This site provides library overview information, a FAQ, bug list, and download access for the library.
This library/source code is mirrored on the CD-ROM. The file name is uncgitar.Z. Rename it to uncgi-1.7.tar.Z and decompress it on your system.
(d)Shareware CGIs
The Site has a group of various UNIX-based C routines that are CGI scripts for performing various useful functions. This site also provides download access for the various CGI scripts and C source code.
The scripts from this site are also on the accompanying CD-ROM. The file names are
See "Introducing HTTP Cookies," p. xxx, to find out more about cookies.
The Sessioneer CGI Authorization Tool, or SCAT, uses server-side cookies, or tokens, to identify users and preserve state information between successive CGI calls and among otherwise unrelated CGI programs. The chief advantage of SCAT is that it works with all browsers and any server that supports the CGI 1.1 specification. SCAT can alleviate the tedious chores of verifying and tracking individual users. This library is very useful for anyone trying to develop a "shopping-cart" program, or other CGI system that requires state information.
SCAT is available from this site. Note that the license agreement for SCAT specifically states that SCAT may not be used for commercial development.
(d)libcgi
libcgi, available from Enterprise Integration Technologies Corporation (EIT), contains functions that will let your CGI program incorporate accurate parsing, dynamic HTML generation, and form processing. libcgi is a wonderful tool that will save you hours and hours of sweat. Read the online documentation at this site, and then download the libraries appropriate to your flavor of UNIX from Site.
(d)CIS C Source Code Library
Custom Innovative Solutions, Corp. (CIS) has thoughtfully provided a double handful of useful routines to lighten the CGI programming load. All the routines are presented as well-documented C source code and are available from this site.
(d)cgic
Thomas Boutell's popular cgic library (available from this site ) provides ready-made routines for almost all common CGI tasks. If you use only a single library from those presented here, you could do far worse than to pick this one. Boutell has done a very credible and thorough job of making CGI programming as painless and bulletproof as possible.
You can find two versions of cgic on the CD-ROM. The first, cgic105.zip, is for Windows or Windows NT systems. The second is cgictar.Z, which you should rename to cgig105.tar.Z.
(d)Cgihtml
Cgihtml is a related set of CGI and HTML routines written in C by Eugene Kim. This library, designed to be compiled on your system and then linked with your programs, provides basic parsing and validation routines geared toward processing CGI input and producing HTML output. The documentation and the library code are available from this site.
Cgihtml is available on the accompanying CD-ROM as cgihtml.gz, which you should rename to cgihtml-1_21_tar.gz before decompressing on your system.
(d)MaxInfo's WebC
MaxInfo's WebC (available from this site) provides a complete graphical development environment specifically for CGI, letting you mingle HTML and C code. WebC consists of a special compiler, a runtime library, and a CGI stub program called the application manager.
Here's a sample of WebC source code, showing how WebC lets you freely intermix C and HTML:
!wchForm("step2.html");
<table border=0 width=100%>
<tr><td>
<table border=1>
<tr><th>Size</th><th># Slices</th><th>Base Price</th></tr><tr>
<!code>
for (num=0; num<SIZES; num++)
{
!<tr>
wchFancyCell(sizeNames[num]);
wchFancyCell(sizeSlices[num]);
wchFancyCell(wcSprintF("$%4.2f", sizePrices[num]));
!</tr>
}
<!/code>
WebC isolates you from the nitty-gritty details without making it impossible for advanced programmers to take total control of the processing. If you're looking for a fancy, high-powered development environment, you might want to take WebC for a spin. MaxInfo offers a trial version.
{kind=link}