
Copyright ©1996, Que Corporation. All rights reserved. No part of this book may be used or reproduced in any form or by any means, or stored in a database or retrieval system without prior written permission of the publisher except in the case of brief quotations embodied in critical articles and reviews. Making copies of any part of this book for any purpose other than your own personal use is a violation of United States copyright laws. For information, address Que Corporation, 201 West 103rd Street, Indianapolis, IN 46290 or at support@mcp .com.
Notice: This material is excerpted from Special Edition Using CGI, ISBN: 0-7897-0740-3. The electronic version of this material has not been through the final proof reading stage that the book goes through before being published in printed form. Some errors may exist here that are corrected before the book is published. This material is provided "as is" without any warranty of any kind.
When Karl Capek wrote R.U.R. (Rossum's Universal Robots) back in 1921, I seriously doubt he considered what the word robot would mean to us today. It's not just a mechanical device used to help us with complicated and sometimes mundane tasks. A robot can now be a program designed to help you do what's no longer conceivable to do "by hand"-even on the Web.
Most of you have probably used the various search engines available to find a particular piece of information. I've used them from finding information about what's new on the Internet to finding out which trails around the Cascade mountains would most interest me for a hike. I even used them to find a recipe for peanut butter cookies (my favorite) and to find information about one of the NASA projects that my son participated in at school.
Although most of these "search engines" let you add your Web pages into their database of information, they also do some work in the background-mainly by using robots to gather information that's available. They catalog it and then present this information for public or-at times-private use.
In this chapter, you learn about these entities that creep around in cyberspace. You learn
Most of the information that you've retrieved from places such as Lycos, Infoseek, and WebCrawler was compiled with the help of a robot. This strange entity has also been called a spider, crawler, Web-worm, and wanderer. All these strange sounding things are simply programs designed to do mainly one thing: to retrieve information that has been stored on the Internet-most noticeably, the World Wide Web. Some robots have been designed to help you maintain the Web pages that your organization already has. For instance, if your site is anything like most I've seen, it has a multitude of pages containing links to other pages on-site and off.
A robot acts much the same way as you do in that it retrieves information from various Web sites. A robot can work a lot faster, though. As you go out and retrieve information from a site, you may stop and look through the information sent to you. A robot, on the other hand, just grabs that information, stores it in a file, and continues. It can even have several processes running at the same time, so that it can retrieve information from many sites at once. A robot also can work at a faster pace, hitting quite a few sites in less than a minute if programmed to do so.
A robot's speed can be beneficial to the person or organization that hosts a robot. For instance, an organization wants you to find information on sites that supply equipment useful to connecting them to the Web. You can simply run a robot that goes out and looks for information about wide area networking, routers, modems, Internet providers, consultants, and whatever else would suit their business needs. The robot can go out "hitting" every site in its path and collect that information (A hit is a slang word indicating that someone or something has accessed your page.). After the information is gathered, it's transformed into a database that can be used by various search engines.
The idea of collecting such a large amount of information may sound interesting, but it can cause a lot of other problems as well. The speed of a robot has a price-not only with the site hosting a robot, but also on the system from which a robot is retrieving this information. Consider your site being hit by a multitude of users. Then consider your site being hit by something that could do the same thing but at a much faster pace. What could you do about it?
In June 1994, Martjin Koster, Jonathon Fletcher, and Lee McLoghlin, with a group of robot authors and enthusiasts, created a document called "A Standard for Robot Exclusion." This document provided a way in which a Web server administrator could control which robots were allowed access to the server, and where on the Web server they would be allowed to roam. Mind you, this document is just a proposal. At this time, it hasn't become an official standard by any means (and most likely never will). Any robot author can incorporate the proposed guidelines into his or her program if he or she chooses to do so. The nice thing is that many authors have already incorporated these guidelines into their programs.
The "Standard for Robot Exclusion" simply states that
a robot is to look in the server root for a file called robots.txt.
If the file is found, the robot reads the file and acts according
to the limitations provided in the file.
Because the file can be placed only in the server root, most likely only the server administrator could edit the robot.txt file. This restriction poses a problem for individual users who control a specific area on the server. You can't have your own robots.txt file in http://www.somewhere.com/~jdoe/, for example. You should talk with your server administrator and work out a method in which you can have him or her add the robot limitations desired.
Quite a few people that have access to the Web server error logs have wondered why someone or something out there has been trying to access the robots.txt file. A few even think this was some attempt at a break-in to their system.
The file name robots.txt was chosen because most operating systems could use it (for example, MS-DOS's 8-dot-3 file names), and using the name robots.txt wouldn't require the system administrator to configure the server any differently. Most servers allow for the extension *.txt already. The name is easy to remember, and it's easy to recognize.
Just as your browser sends a USER_AGENT variable to an HTTP server, most robots are designed to do the same. For the most part, a robot is just a userless HTML browser. For example, the USER_AGENT variable for Netscape's 2.0 browser using Linux on a 486 is
Mozilla/2.0b3 (X11; I; Linux 1.2.13 i486).
This information tells the server what's hitting the pages that it manages. The line usually contains at least the software and its version number.
The same approach works with robots. One robot used by Lycos sends the environmental variable USER_AGENT, as follows:
Lycos/0.9
Why do you need to know this information? Well, each record in the robots.txt file consists of two parts. The first is the User-agent: line, which is followed by the name of the robot and the version number on which you want to set limits. For example, the following line states that you are placing a limit on the Lycos robot version 0.9:
User-agent: Lycos/0.9
To exclude a different robot, simply change the User-agent option. If you want to keep all robots off your site, simply provide User-agent: with an asterisk, as follows:
User-agent: *
Then you don't have to deal with those pesky critters at all.
The second part of the record in the robots.txt file is the Disallow: line, which lets you define the areas of the server that are off limits. You can have as many Disallow: lines per user agent as needed to protect sensitive areas completely, but you need to have at least one (or why even place it there?). If you want to keep anything with the word private off limits to the robot, for example, you can enter the following on the next line:
Disallow: /private
This line tells the visiting robot that any directory with the word private is off limits as well as any file that begins with private. This includes a file called private.html or privateplace.txt. If you want to keep visiting robots only out of the private/ directories, you can use the following line:
Disallow: /private/
Notice the difference?
To completely disallow a user agent access to anything on your server, simply use the / (slash) with the Disallow:, as follows:
User-agent: wobot/1.0 Disallow: /
Or if you're not interested in any robots visiting your site, use the following:
User-agent: * Disallow: /
This line tells the server that Disallow: / applies to all robots.
Listing 14.1 shows an example of a robots.txt file.
Listing 14.1 Controlling Robots with the robots.txt File # robots.txt file for myhost.com # <User-agent>:<option><Disallow>:<option> User-agent: wobot/1.0 #Don't let that unknown Wobot in!! Disallow: / User-agent: Lycos/0.9 #Hey Lycos is nice! Disallow: /private/ #No need to poke around in there! Disallow: /test #Nobody really wants access to my test files User-agent: ArchitextSpider Disallow: /gifs #Don't need those pictures anyways User-agent: InfoSeek Robot 1.16 Disallow: /users/ #Keep 'em out of the user directories
As you can see from listing 14.1, you can set limitations on as
many robots as you need. You just need a blank line (CR, CR/NL,
or NL) between each record.
For a robots.txt file to work, the robot that accesses your site must actually look for this file. Not all robots are programmed to do so. If you're creating a robot, check out the example that's written in Perl and is available at the following:
By using a robots.txt file, you can control most of the robots in existence today. I don't think anyone would really want to deny all the robots that are gathering information out there. They serve a purpose; they get your information out to others, making it easier for people to find you. If you're having problems with a particular robot, however, knowing that you have some control is nice. Take a peek at the following for more information:
Robots are available to do anything from verifying links in bookmarks or existing pages, to scouring the Web for information and building a database for use with search engines. Martijn Koster provides an excellent list of these robots at the following site:
In his list, you can find information on just about every robot built. Most of them are in test stages of some sort or another. The list contains information on UNIX, Windows, and Macintosh systems.
Most of the robots commonly available simply check and verify links contained within a file. These robots are helpful in that they can make sure that existing links aren't broken and do, in fact, work. This capability is especially helpful if you have pages that contain a large number of links to other sites. You may have created a small index of your favorite sites or of sites that contain information specific to your needs. If you've ever built such a page, you often may find links that are no longer accessible. These robots can let you know if any of these sites go down so that you can change the links or delete them altogether. One such robot is the MOMSpider, which you can find at the following URL :
This program, written in Perl for UNIX, transverses your Web pages and reports any problems, thus letting you correct those problems in a more efficient manner than, say, using your Web browser to retrieve every page and check out every link yourself.
Another robot that does much the same thing is the EIT Verifier Robot. Or you can find it on the EIT Web site:
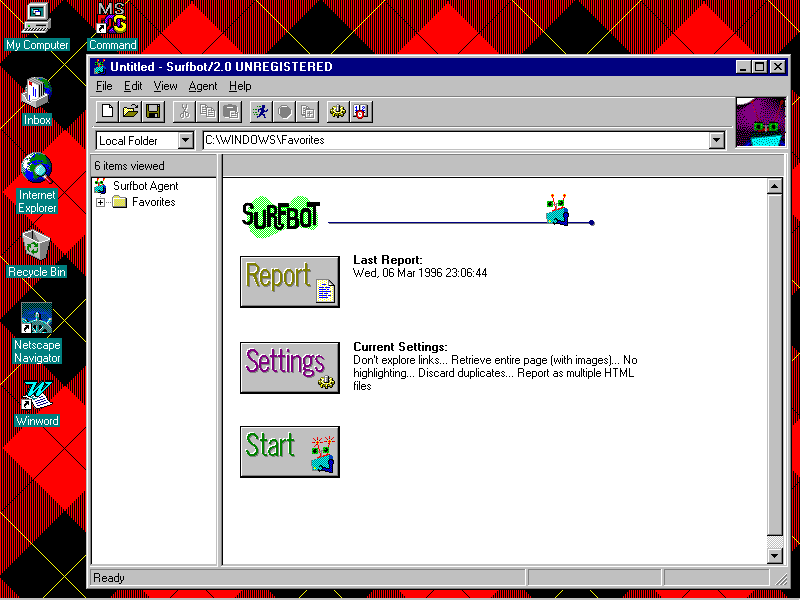
SurfBot 2.0 is another program that works much like MOMspider and EIT's Verify program. SurfBot checks links in a bookmarks file, ensuring that each link will work. It has a nice graphics interface that can get you running with a few clicks of the mouse button (see fig. 14.1). It reports any problems with any links on your bookmarks file and also reports other statistical information.
SurfBot, an indexing robot, has an easy-to-use interface that helps you keep on top of problems-like broken links. SurfBot runs on Windows NT and Windows 95 and is available at
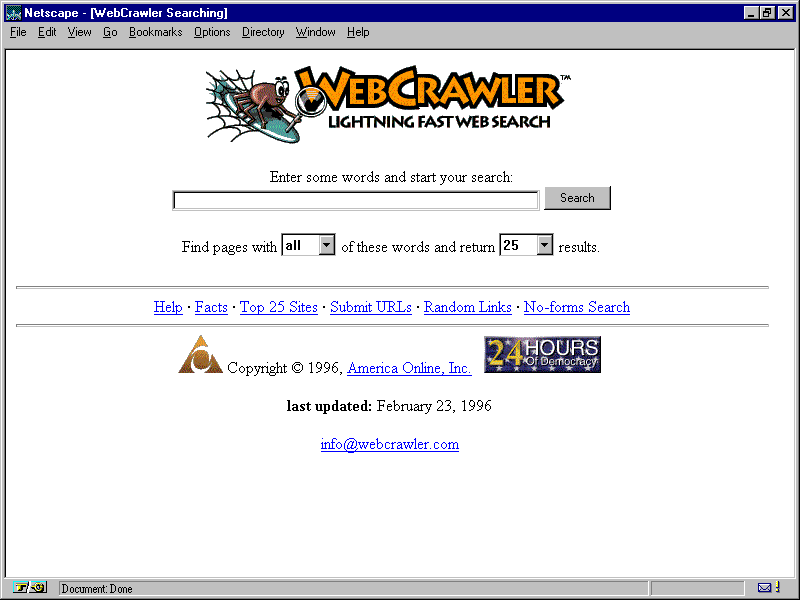
Only a few of the "wandering" robots are available for public use. These robots are an important resource that seems to end up being taken over by commercial organizations. WebCrawler, shown in figure 14.2, originated at the University of Washington and now belongs to America Online. You can access it at the following address:
Robots serve an important role on the Web by making information easily accessible.
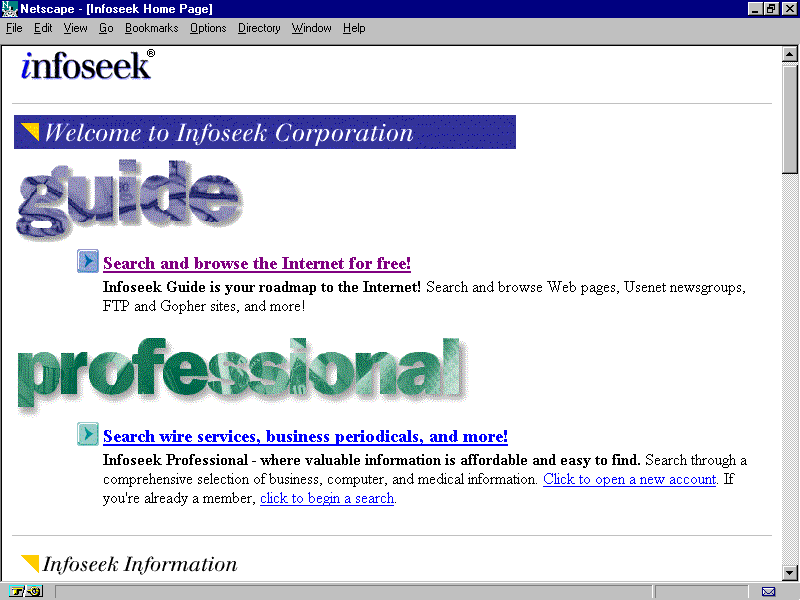
Others have started to use their robots for a commercial purpose as well. Infoseek Corporation even provides a fee-based access system to its search engine, and luckily the company provides a section that's free to users as well (see fig. 14.3). You can access Infoseek at the following address:
Infoseek provides search capabilities for free as well as more in-depth searching for a small fee.
Using robots apparently is going to become standard on the Net. If a robot does well, it could make a lot of money. As you know, information is power, and power is money. I can't say I blame these companies. A good robot really serves a needed purpose. The time it takes to build a robot, send it out to retrieve information from Web pages, and then maintain such a large database should return something to those who invested the time and energy to build it.
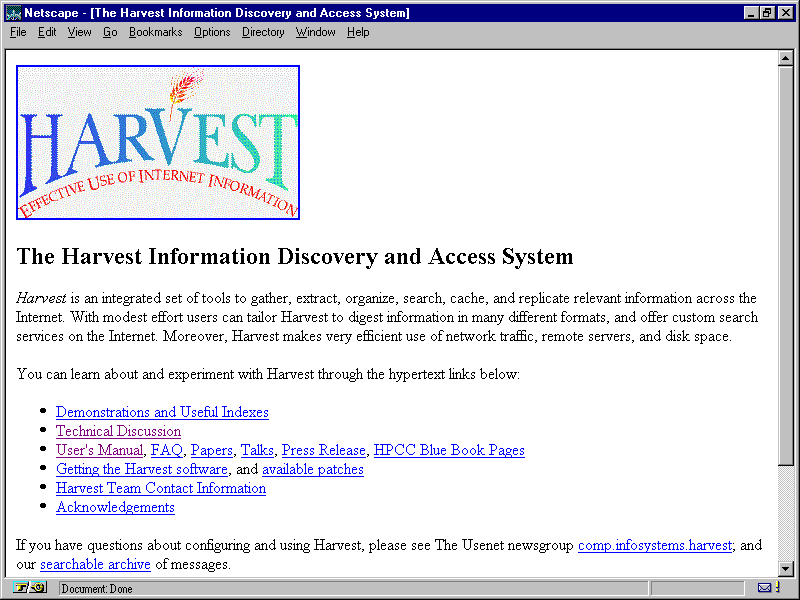
Even so, few robots that catalog information on the Net are available to system administrators. One such robot is called Harvest (see fig. 14.4). It's located at the following:
Harvest is one of the few wandering robots that's available to the public.
Harvest, built by a group of students at the University of Colorado, is an indexing robot that can go off site to gather information. Even though it wasn't meant to be used as a wandering robot, it can fill that purpose nicely. It doesn't go out aimlessly. You maintain control of the Harvest robot by specifically directing the robot to go to a specific host (or hosts). It won't wander off that host, but by viewing the information retrieved from one site you can easily plan which sites you feel should be accessed next.
Harvest consists of two main programs. The first, appropriately called the Gatherer, does the leg work. It goes out and grabs the information that's then used by the Broker. The Broker collects the information from the Gatherer (or many Gatherers) or other Brokers and then provides a query interface to the gathered information.
You need to know that running a robot that retrieves information from the Web is going to hog a lot of resources-not just bandwidth, but file space as well. The Harvest documentation states that you should start with at least 50M of free space.
Next, you need to collect the Harvest files, which are located at the following site:
If the binary for your system isn't available, the source code is provided. The distributed version for the Sun system on which I installed Harvest was over 5M.
Create a directory in which you can place the Harvest distribution and then unarchive the file. The default location is /usr/local/Harvest-1.4.
Now set an environmental variable, HARVEST_HOME, to the location in which you've placed the harvest executables. You can do this simply by typing
setenv HARVEST_HOME path_to_harvest
at the shell prompt. Of course, you would replace path_to_harvest with the actual path to the directory in which you have the harvest executables stored.
Then, depending on the HTTP server you use, edit the server configuration files so that the server recognizes the contents in Harvest/cgi-bin as CGI programs.
See "CGI Installation," for more information on how to set a directory for CGI programs for various servers.
For example, if you're using NCSA's HTTP server, add the following:
ScriptAlias /Harvest/cgi-bin/ /usr/local/Harvest-1.3/ Alias /Harvest/ /usr/local/Harvest-1.3/
Next, edit $HARVEST_HOME/cgi-bin/HarvestGather.cgi, and change the paths for the following lines to match your system's configuration:
HARVEST_HOME=/usr/local/harvest GZIP_PATH=/usr/local/bin
Edit $HARVEST_HOME/cgi-bin/BrokerQuery.pl.cgi, and change the HARVEST_HOME variable for your setup. You have to edit the path to Perl if it's any different from your system as well.

When you're configuring Harvest for the first time, it's best to simply index only your site at first. In doing so, you can get comfortable with Harvest before letting it loose on other hosts.
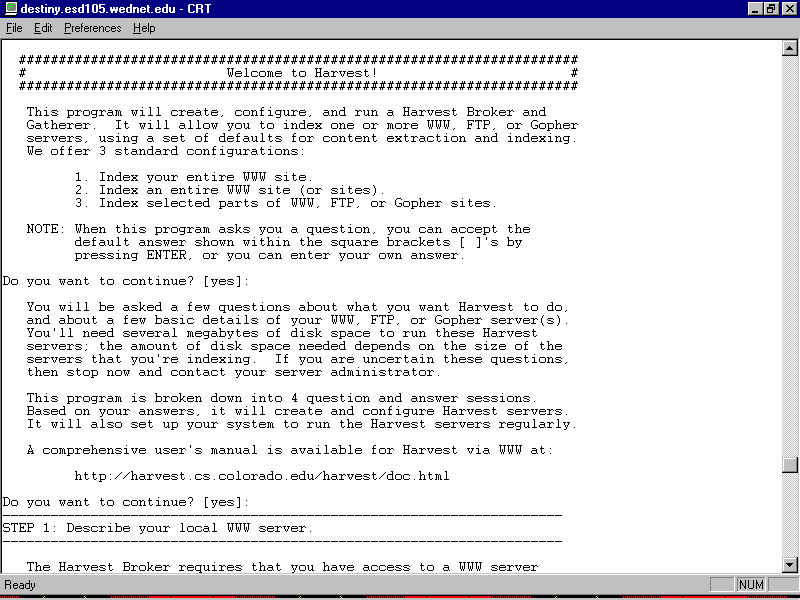
Now you're ready to run Harvest by using the supplied $HARVEST_HOME/RunHarvest program. When you do so, Harvest welcomes you to the program (see fig. 14.5). Then it asks you a series of questions. This process definitely makes setting up the Harvest robot a lot easier than configuring everything by hand.
When creating your Harvest broker and gatherer, the RunHarvest program walks you through the setup process.
Here are the questions Harvest asks:
***Production: Indent the following BL (7 lines) further within an NL. Use round bullets, per sample.***
I'm having problems getting the Harvest Gatherer and the Broker to run. Have I done something wrong?
Make sure that you set the environmental variable HARVEST_HOME properly, as well as the path's cgi scripts, HarvestGather.cgi and BrokerQuery.pl.cgi.
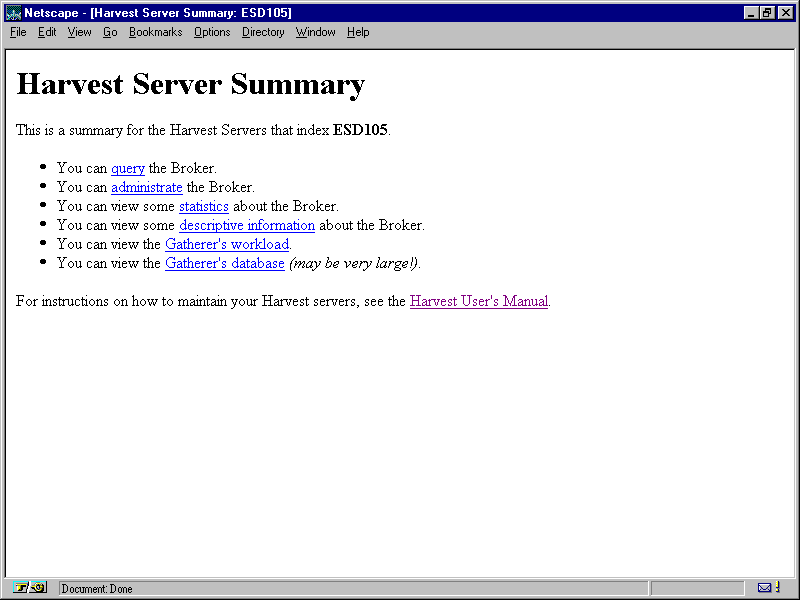
After it's finished, Harvest gives you an URL pointing to a summary page. For example, the following URL opens a screen like the one shown in figure 14.6:
The Harvest Summary screen lets you retrieve statistics about the Broker and Gatherer and administrate the Broker, and also provides a link to the query page.
The summary screen provides links to other sections that help you with your configuration.
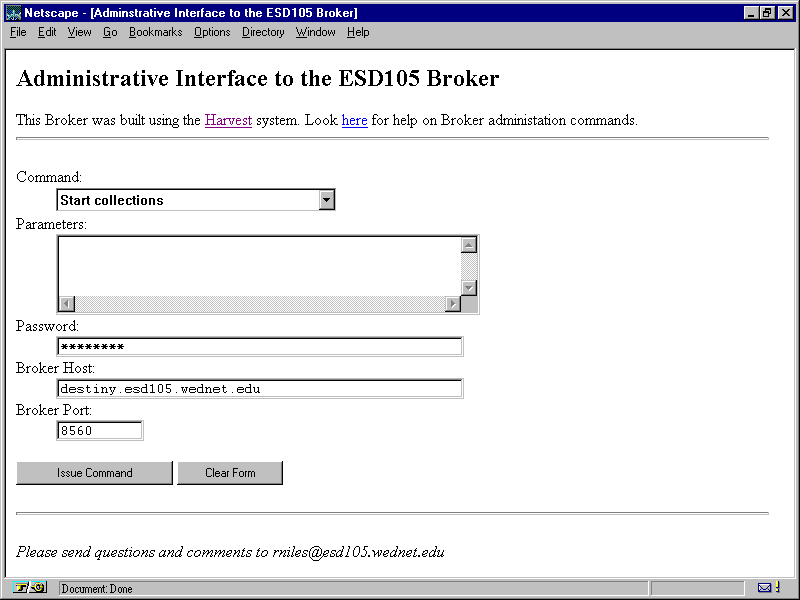
The administration page, shown in figure 14.7, provides a list of options you can use to control the server through a browser that supports forms. First, select an option from the Command list box. Then enter any parameters needed (if any). Then you can enter your password, the Broker host name, and the port. After you're finished with your selections, click the Issue Command button to activate the BrokerAdmin.cgi program and make the changes you requested.
The Administrative Interface allows you to control certain aspects of the robot through an easy-to-use interface.
Now that you have a robot ready, willing, and able to start collecting information from the vast World Wide Web, you should know a few things before unleashing such a beast onto the Web community.
Martijn Koster placed a page on the Web that contains the proposed guidelines for writing robots and using them. You can access the page at the following site:
The first part of this document was simply titled "Reconsider." You should think about why you want to place a wandering robot on the Web and then ask yourself if you can find another way to get this information.
Already, quite a few places are available for you to query information from robots already on the Web. Chances are, one of the existing databases has the information that you're trying to acquire. Almost every piece of information that I've sought was available not only on one search engine but on most of the search engines.
When you start to compile information from using one of the robots, you'll see your file space shrink. Harvest states that you should start out with 50M of free space, which the Gatherer can use to store the information collected. Disk space isn't the only consideration with robots. Even a well-configured robot can bog down a system by hogging system resources. Make sure that you don't go after too much information too quickly.
Every time you click another link while browsing around the Web, you use a portion of that superhighway to retrieve that information. Everyone else who's on the Internet at the same time as you are is taking another piece of it. Have you ever been on a freeway around a big city during rush hour where the speed limit is 55 miles per hour and found yourself at a complete stop? Have you ever figured out how that works? You might think that if every car is going 55, you shouldn't encounter any problems, right? Well the information superhighway works in much the same manner as the highways that you use to commute from one place to another. Just like the cyberhighway, the roads that you drive on often change from two lanes to four to three lanes. People get on the freeway, and people get off. Well, this doesn't cause any problems when just a few cars are on the road, but it certainly does when there are many cars on the road.
Robots don't carpool. In fact, they're just the opposite. One robot can drive multiple cars on the superhighway, taking up another part of the road, with the potential of causing another traffic jam.
When creating a robot, or if you happen to be running a robot, you should do a few things to minimize the chance of bottlenecking, if possible:
As with everything else on the Internet, there are guidelines to running a robot. Of course, none of these guidelines are carved in stone, but they should be followed. Most system administrators would love to have their pages indexed and have their information readily available for people to access, but a badly run robot can easily ensue the wrath of these administrators on you.
Working with other administrators and staying on top of what your robot is doing makes life on the Internet easier for everyone. If your robot is disruptive, most likely the site in which problems arose will deny you future access. This would undermine your intentions and create problems when you're trying to catalog information.
Previously, I stated that it might be wise to simply use the resources of other Web crawlers that are already on the Net. You can always tell your browser to go to one of the popular search engines, or even provide a link on one of your pages to a search engine to aid others in their search. You also can easily create a page that contains a form that queries the search engines already in existence. Most sites supply this information, but I'll walk you through a few of them so that you get an idea of how to go about this process.
Infoseek provides an e-mail address to which you can send a blank letter; in return, they provide you with the HTML code to add a link to their site on your page (see fig. 14.8). This capability is quite handy because Infoseek has one of the best search engines available.
When you send an e-mail message to html@infoseek.com, you should get a reply within five minutes or so. This reply contains HTML code for a form that looks like the example in listing 14.2. You don't need to have CGI enabled or anything else configured differently for your server.
Listing 14.2 Adding InfoSeek to Your Search Pages <FORM METHOD="GET" ACTION="http://guide-p.infoseek.com/WW/IS/Titles"> <A HREF="http://guide.infoseek.com/"><img src="http://images2.infoseek.com/images/guidesm.gif" border=2 width=105 height=62 alt="[Infoseek Guide]"></A><p> <A HREF="http://guide.infoseek.com/">Infoseek Guide</A>: <B>Your roadmap to the Internet</B><p> The best way to search the Web, Usenet News and <A HREF="http://guide.infoseek.com/">more</A>. Type in words and phrases and select a source to search below.<br> <INPUT NAME="qt" SIZE=50 VALUE="" MAXLENGTH=80> <INPUT TYPE="submit" VALUE="Search"><br> Source: <INPUT TYPE=radio NAME=col VALUE=DC CHECKED> All Web pages <INPUT TYPE=radio NAME=col VALUE=NN> Usenet Newsgroups (<A HREF="http://guide.infoseek.com/IS/Help?SearchHelp.html#searchtips">Search tips</A>) </FORM>
Lycos is kind enough to do the same thing as Infoseek, but it also provides a backlink to your page using your personal or company logo. This backlink almost makes it look like your site is performing these powerful searches, when in fact it's not!
To have Lycos add a backlink to your page, first look at Site. Fill out the form that Lycos provides to enable this service. After you get the HTML code (which might take a few days), add it to your search page.
If at any time you add a reference to your Web site at Starting Point, you receive an e-mail message. This message contains information on how you can add a link back to Starting Point's search engine, like you see in figure 14.8. Starting Point even provides the HTML code so that you can create a form that queries its search engine.
Adding external search engines to you pages allows you to provide powerful search capabilities to your users.
This service not only provides a means in which people on the Internet can find your site, but it also helps Starting Point because your site refers people to the company as well. Listing 14.3 shows you how to add this link.
Listing 14.3 Adding Starting Point to Your Search Page <!-- begin MetaSearch form interface for Starting Point--> Enter search keyword(s):<br> <form action="http://www.stpt.com/cgi-bin/searcher" method="post"> <input type="text" name="SearchFor" value="" size=38><br> <input type="submit" name="S" value="Starting Point - MetaSearch"> </form> <!-- end MetaSearch form interface -->
One thing you always find at every search engine is a form. Surprised? I didn't think so. Anyway, most browsers allow you to view the source code of the page that you're on. If you can do that, you can see how a particular search engine conducts queries. Hence, you can build a form that accesses an off-site search engine site to perform a search. Just for good etiquette, you might want to ask the business or individual whether it's okay to build such a form. Companies such as Infoseek or Starting Point have a premade form that you can add to your search page.
In figure 14.9, you can get an idea of how to create your own search page by using the robots already available.
By linking commonly available search engines from one of your pages, you can provide powerful search capabilities to your users.
Listing 14.4 search.htm: Powerful Search Capabilities Right from Your Web Site <head> <title>Search the Web!</title> </head> <body> <H1> Search the Web!</H1> <hr> <H2>Search the pages on ITM</H2> <A HREF="http://www.wolfenet.com/~rniles/itm.html"><IMG SRC="http://www.wolfenet.com/~rniles/pics/itm.gif" BORDER = 0></A> <dl><dt><dd> <h3>Search for:</h3> <FORM METHOD="POST" ACTION="http://www.wolfenet.com/~rniles/swish-web.cgi"> <input type="text" name="keywords" size="48"> <input type="submit" value=" Run "> <input type="reset" value=" Clear "><br> <select name="maxhits"> <option>10 <option SELECTED>25 <option>50 <option>100 <option>250 <option>500 <option>all </select> Results<br> <p> <input type="radio" name="searchall" value="1" checked>Search entire files<br> <input type="radio" name="searchall" value="0">Search in:<br> <dl><dt><dd> <input type="checkbox" name="head">Head (title and other items)<br> <input type="checkbox" CHECKED name="title">Title<br> <input type="checkbox" name="body">Document text<br> <input type="checkbox" CHECKED name="headings">Headings in text<br> <input type="checkbox" CHECKED name="emphasized">Emphasized text (bold, italic)<br> <input type="checkbox" CHECKED name="comments">Comments (may contain search keywords)<br> </dd></dl> <p> <input type="checkbox" name="compact">Compact listing (omit scores, URLs, file sizes and types)<br> <input type="checkbox" name="indexdata">Show data about index <p> <hr> <b>And</b>, <b>or</b> and <b>not</b> operators can be used. (The default is <b>and</b>.)<br> Searching is not case-sensitive.<br> <p> Limited wildcard searches are possible, by appending a * to the end of a word.<br> Otherwise the search looks for complete words.<br> Searching starts at the beginning of a word. You can't look for segments in the middle of words.<br> <p> Parentheses force a search order.<br> Searching for phrases is not supported.<br> <p> <pre> <b>Examples:</b> boat sail boat <b>and</b> sail boat <b>or</b> sail boat <b>and (</b>row <b>or</b> sail<b>)</b> boat<b>* and not</b> row </pre> </dd></dl> </form> <a href="mailto:rniles@wolfenet.com">E-mail: Robert Niles (rniles@wolfenet.com)</a><br> <p> <hr> <p> <H2>Search InfoSeek</H2> <FORM METHOD="GET" ACTION="http://guide-p.infoseek.com/WW/IS/Titles"> <A HREF="http://guide.infoseek.com/"><img src="http://images2.infoseek.com/images/guidesm.gif" border=0 width=105 height=62 alt="[Infoseek Guide]"></A><p> <A HREF="http://guide.infoseek.com/">Infoseek Guide</A>: <B>Your roadmap to the Internet</B><p> The best way to search the Web, Usenet News and <A HREF="http://guide.infoseek.com/">more</A>. Type in words and phrases and select a source to search below.<br> <INPUT NAME="qt" SIZE=50 VALUE="" MAXLENGTH=80> <INPUT TYPE="submit" VALUE="Search"><br> Source: <INPUT TYPE=radio NAME=col VALUE=DC CHECKED> All Web pages <INPUT TYPE=radio NAME=col VALUE=NN> Usenet Newsgroups (<A HREF="http://guide.infoseek.com/IS/Help?SearchHelp.html#searchtips">Search tips</A>) </FORM> <hr> <p> <H2>Search Starting Point</H2> <A href="http://www.stpt.com/"><IMG SRC="http://www.stpt.com/stpthalf.gif" border=0></a><p> Enter search keyword(s):<br> <form action="http://www.stpt.com/cgi-bin/searcher" method="post"> <input type="text" name="SearchFor" value="" size=38><br> <input type="submit" name="S" value="Starting Point - MetaSearch"> </form> </body> </html>
Power without all the work! Don't think that you'll be fooling anyone. They'll definitely see who's actually performing the searches, but thanks to the organizations providing these links, you can provide direct access to search engines right from your pages. Because of their accessibility, power, and ease of use, I'm sure your users will greatly appreciate it. Although options exist for you to run your own robot on the Web, with all the existing search engines out there, you can still provide a way for your users to access information without having to spare time and resources to do so.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}